Что такое Figma Overlays и как его использовать при создании интерфейса
Современные интерфейсы — это не просто статические экраны. Рассказываем, какие эффекты можно создать с помощью Figma Overlays.


Что такое оверлей
Overlay (дословно «перекрытие») — один из вариантов действий, которые можно назначить любому элементу.
Существует 3 варианта анимации для элементов на сайте:
Оверлей подходит для прототипирования бургер-меню, всплывающих модальных окон, системных сообщений, а также для всплывающих подсказок и экранной клавиатуры.

Автор статей по дизайну. В веб-дизайн пришел в 2013 году, осознанно начал заниматься с 2015 года. Параллельно освоил верстку. Время от времени публикует переводы на Хабре.
Как использовать параметр Overlay
Разберем на примере одного проекта, как использовать параметр Overlay и какие преимущества он дает.
Чтобы активировать оверлей, нужно перейти в режим прототипа.

Выберите элемент, по нажатию на который должен срабатывать оверлей. В нашем примере клик по элементу будет вызывать бургер-меню.
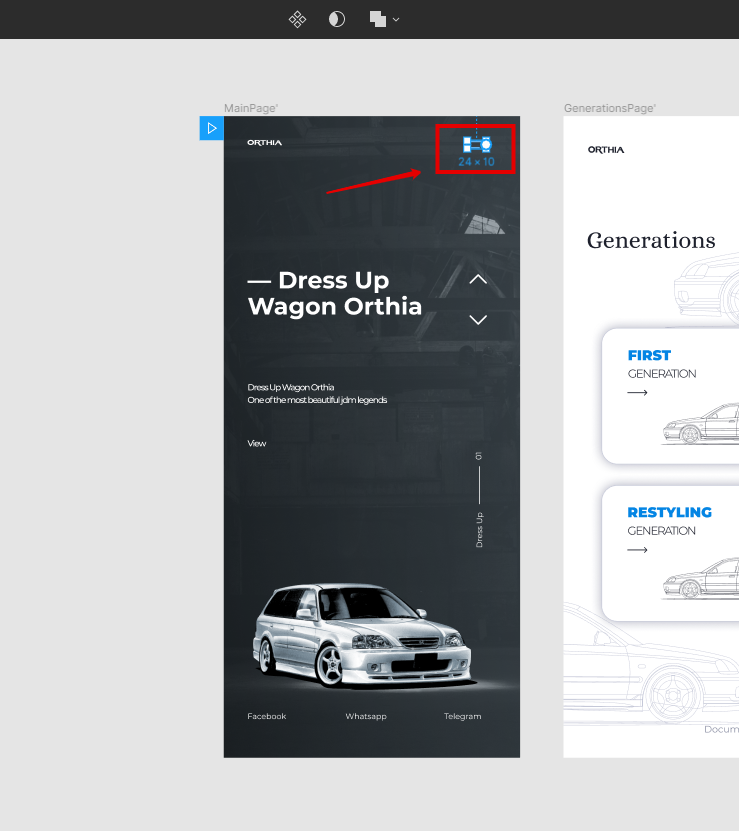
Чтобы создать связку бургер-меню с оверлеем, перетащите круглый маркер, который появился при выделении бургер-меню, на фрейм оверлея (я назвал его OverlaysMenu).
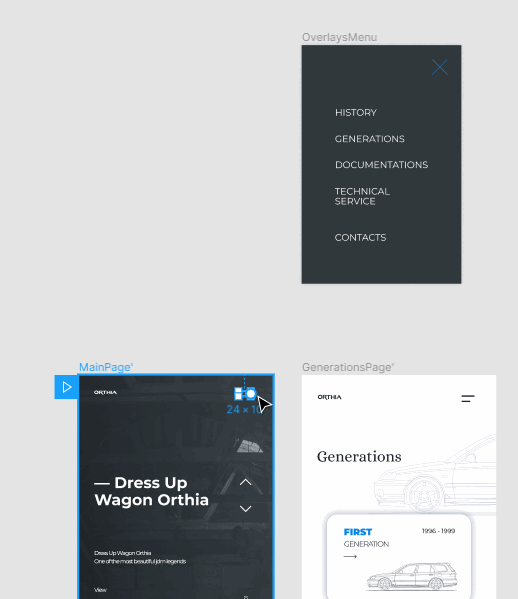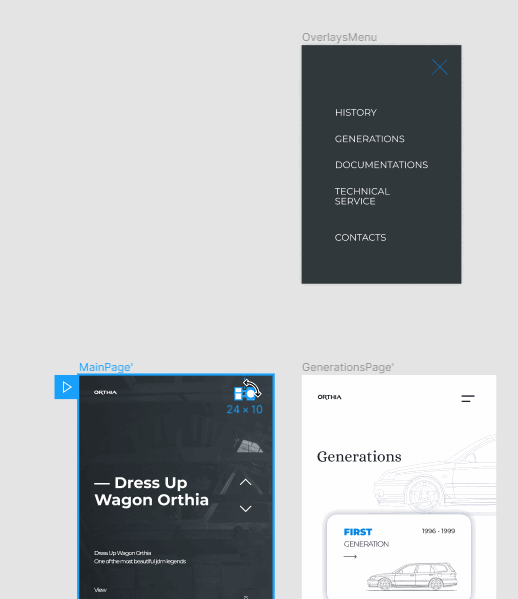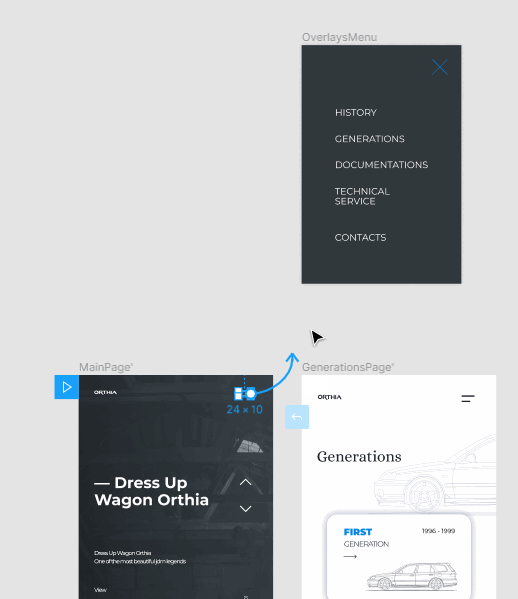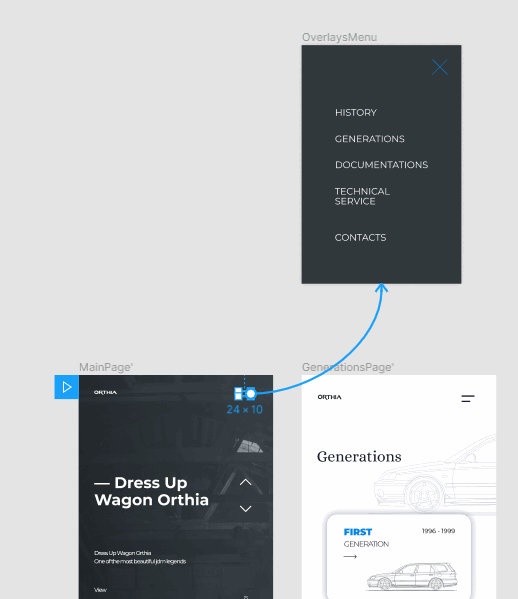
Выберите тип триггера — событие, которое будет запускать действие. Я выбрал On Tap — то есть при нажатии.
map overlay
Смотреть что такое «map overlay» в других словарях:
Map Overlay and Statistical System — The Map Overlay and Statistical System (MOSS), is a GIS software technology. Development of MOSS began in late 1977 and was first deployed for use in 1979. MOSS represents a very early public domain, open source GIS development predating the… … Wikipedia
overlay — [ō΄vər lā′; ] also, and for n.always [, ō′vər lā΄] vt. overlaid, overlaying 1. to lay or spread over 2. to cover or overspread, as with a decorative layer of something 3. Printing to place an overlay upon n. 1. anything laid over another thing;… … English World dictionary
overlay — (v.) to cover the surface of (something), c.1300, from OVER (Cf. over) + LAY (Cf. lay). There also was an overlie (late 12c.), but it had been merged into this word by 18c. The noun in the printing sense is attested from 1824; meaning transparent … Etymology dictionary
overlay — ► VERB (past and past part. overlaid) (often be overlaid with) 1) coat the surface of. 2) lie on top of. 3) (of a quality or feeling) become more prominent than (a previous one). ► NOUN 1) a covering. 2) … English terms dictionary
overlay — overlay1 v. /oh veuhr lay /; n. /oh veuhr lay /, v., overlaid, overlaying, n. v.t. 1. to lay or place (one thing) over or upon another. 2. to cover, overspread, or surmount with something. 3. to finish with a layer or applied decoration of… … Universalium
overlay — I. verb (t) /oʊvəˈleɪ/ (say ohvuh lay) (overlaid, overlaying) 1. to lay or place (one thing) over or upon another. 2. to cover, overspread, or surmount with something. 3. to finish with a layer or applied decoration of something: wood richly… … Australian-English dictionary
overlay — I o•ver•lay v. [[t]ˌoʊ vərˈleɪ[/t]] n. [[t]ˈoʊ vərˌleɪ[/t]] v. laid, lay•ing, n. 1) to lay or place (one thing) over or upon another 2) to cover, overspread, or surmount with something 3) to finish with an overlay: wood overlaid with gold[/ex] 4) … From formal English to slang
overlay — A printing or drawing on a transparent or semi transparent medium at the same scale as a map, chart, etc., to show details not appearing or requiring special emphasis on the original … Military dictionary
overlay — overlay1 verb (past and past participle overlaid) 1》 coat the surface of. 2》 lie on top of. 3》 (of a quality or feeling) become more prominent than (a previous one). noun 1》 a covering. ↘a transparent sheet over artwork or a map, giving… … English new terms dictionary
Aspen Movie Map — The Aspen Movie Map was a revolutionary hypermedia system developed at MIT by a team working with Andrew Lippman in 1978 with funding from ARPA.FeaturesThe Aspen Movie Map allowed the user to take a virtual tour mdash;travel surrogately… … Wikipedia
Heritage Overlay — A Heritage Overlay or HO is one of a number of planning scheme overlays contained in the Victorian Planning Provisions, for use in planning schemes in Victoria, Australia. The heritage overlay schedule of each local government planning scheme… … Wikipedia
Быстрые треки на google maps
Я работаю над визуализацией парапланерных соревнований — пишу плеер просмотра гонки для Airtribune.com. В процессе работы мне попадаются интересные и нестандартные задачи. Одна из них — задача быстрой отрисовки маркеров и треков на карте google maps.
Масштабы такие: есть
200 трекеров в довольно ограниченной области (50×50км), каждый передает данные о своем положении раз в 10 секунд. Нужно их все отрисовать на карте и плавно перемещать при изменении координат. За каждым маркером должен отрисовываться трек. Картинка примерно следующая:

Скоро обнаружилось, что встроенные объекты — google.maps.Marker и google.maps.Polyline — для данной задачи работают слишком медленно. Была куча идей по оптимизации, и в результате получилось решение на canvas-е, которое работает со скоростью 40fps даже на тысяче маркеров. Впрочем, fps вы можете померить сами — я собрал тестовое приложение для сравнения 4-х движков, в котором на лету можно подключать разные фишки и смотреть на скорость работы.
Тестовое приложение
kasheftin.github.io/gmaps — здесь демо, github.com/Kasheftin/gmaps — здесь исходный код. Работает в firefox и chrome, html+js. Используются google maps api v3, knockout, require, underscore и bootstrap.
Настройки разбиты на две части — в правой части генератор координат. Кроме управления количеством маркеров здесь мало интересного. Генератор эмулирует настоящий сервер, то есть выплевывает данные кусками на минуту вперед. Поэтому если настройки меняются, изменения видны не сразу. Скорость — это максимальная величина, на которую может измениться широта или долгота за секунду. Угол — максимальный угол, на который может поменяться курс. Вероятность движения — это вероятность того, что на данную секунду придут данные с координатами пилота, а hold — вероятность того, что данные придут те же самые (т.е. пилот зависнет на одном месте). Между контрольными точками движение считается равномерным прямолинейным.
Самое интересное — в левой колонке настроек. Здесь можно переключать движки, при выборе движка под ним отображаются чекбоксы с его настройками, причем все подключается налету на том же наборе данных — это сделано чтобы адекватно оценивать fps. Сам fps будет отображаться если нажать на кнопку play над картой. Fps меряется тупо и практически — для проигрывания анимации используется метод requestAnimFrame — сколько раз он успевает отработать за секунду, такой и fps.
Нативный движок
Это отрисовка стандартными средствами google maps. Первое, что приходит в голову — использовать google.maps.Marker для отображения текущего положения трекеров и google.maps.Polyline для отрисовки треков. Причина тормозов при анимации — объектная логика. Маркеры и линии — это картинки на канвасе, однако мы общаемся с ними как с объектами. И это затратно. Перемещения маркеров должны быть плавными. Если на данный момент времени маркер не имеет координат, его мгновенные координаты высчитываются как линейная пропорция между имеющимися координатами до и после. Это означает, что в каждом кадре ВСЕ маркеры сдвигаются.
Предположим, что в массиве markers были созданы 100 маркеров со случайными координатами. Рассмотрим код:
Отступление: задачка-шутка
Предположим, есть код, который в цикле совершает некоторое действие, причем неизвестно, сколько времени оно занимает (классический пример — функция requestAnimFrame). Хочется узнать это время, прибавить его к таймеру и получить какое-то время, которое показывать в плеере. При этом естественно ожидать, что расчитанное время будет идти с той же скоростью, что и настоящее. Очевидное решение:
Вроде все верно? Предлагаю запустить утрированный пример и найти в чем ошибка — jsfiddle.net/kasheftin/a5sen/1.
Дивный движок
Треками займемся позже, а пока оптимизируем отрисовку маркеров. В google maps v2 и леафлете маркеры рисуются дивами. Логично предположить, что передвинуть 100 дивов быстрее, чем 100 раз перерисовать канвасы с объектами. Особенно если при этом оптимизировать расчеты координат.
Есть два механизма наложения своих объектов на google maps — с помощью оверлеев (overlays) или с помощью своего типа карты (overlay map type). Для дивных маркеров будем использовать оверлей. Создадим див-контейнер, который наложим поверх карты, и в который будем добавлять дивы с иконками маркеров. В каждом кадре анимации будем пробегать по массиву маркеров, расчитывать новые координаты и сдвигать дивы.
Неудачная оптимизация
В google maps предусмотрено несколько мест, в которые можно добавлять свои элементы. Оверлеи рекомендуется добавлять в один из контейнеров MapPanes. Элементы управления (например, свою шкалу зума или переключатели)- в MapControls. Соответственно, все слои MapPanes «приклеены» к тайлам карты и двигаются при драге. Элементы управления находятся поверх тайлов и неподвижны.
Возникает идея — раз при каждом драге карты оверлей нужно возвращать обратно в левый-верхний угол, почему бы его не поместить в неподвижный слой контролов? Это работает (дискуссия на stackoverflow и рабочий пример на jsfiddle). Идея даже может показаться удачной — до тех пор, пока приложение не запущено на медленной системе типа андроида. Там оказывается, что карта двигается, а маркеры не успевают и тупят на месте. Все привыкли к тому, что при драге могут вылезать незагруженные серые области, которые потом заполняются данными (например, сдвинули карту — а трек на новой области отрисовался только через секунду). А вот рассинхрон в движении слоев недопустим.
Канвасный движок
Раз маркеры постоянно в движении, логично предположить, что перерисовать их все разом быстрее, чем двигать по одному. Не нужны observable или events emitter, не нужно следить, когда маркер меняет свои координаты (между кадрами это может произойти не один раз). Вместо этого в каждом кадре пробежим по всем маркерами и отрисуем их заново на одном большом канвасе, который наложен поверх карты.
Автор этого оверлея — napa3um. Он же предложил следующую оптимизацию. Каждый раз при изменении координат точки происходит вычисление ее прямоугольных координат по формуле проекции Меркатора WGS84. Чтобы избежать вычислений, можно расчитывать и хранить прямоугольные координаты на сервере, а на клиент отправлять уже результаты вычислений.
В тестовом приложении нет сервера, и поэтому не протестировать результат этой оптимизации. Чтобы сэмулировать эффект, я заменил вычисление проекции на более простое линейное преобразование (известны географические и прямоугольные координаты углов карты, и на их основе расчитываются прямоугольные координаты любой точки как линейная пропорция). В настройках приложения есть чекбокс «optimize geo calculations», который включает этот метод расчета. На больших зумах пропорция врет, но на тех зумах, на которых это заметно, парапланерные гонки не смотрят. Впрочем, результаты показывают, что любые вычисления сейчас происходят очень быстро, а тормоза возникают на этапе отрисовки.
При использовании канваса часто приходится решать задачу об обработке событий мыши на нарисованных объектах. На Airtribune для обработки кликов по парапланам используются оба движка — сами маркеры рисуются на канвасе, поверх канваса живет дивовый оверлей с пустыми дивами, которые двигаются синхронно маркерам и ловят клики.
Кеширование иконок
Это просто иллюстрация того, что спрайты, иконки, тексты и другую мелкую графику надо кешировать. В канвасном движке маркеры рисуются вместе с подписями. Рисование текста на канвасе, особенно с обводкой (strokeText) — очень дорогая операция. Есть настройка, которая включает кеширование иконки с текстом на отдельном небольшом канвасе (подготовленное изображение затем вставляется в оверлей командой drawImage). При прочих равных условиях на 100 маркерах производительность кешированной и не кешированной версий отличается в 15 раз.
Треки
Сервер отдает данные о положении маркера в виде массива контрольных точек [[time,lat,lng]. ]. Трек, который нужно отрисовывать вслед за маркером, разбивается на постоянную и динамическую части. Постоянная часть трека — это ломаная, соединяющая контрольные точки с временем меньшим, чем текущее. Динамическая — это отрезок от последней отрисованной контрольной точки до текущего положения маркера (из-за плавности перемещения маркер почти всегда находится между какими-то контрольными точками).
В нативном и дивном движках треки рисуются с помощью объекта google.maps.Polyline. Есть настройка — использовать одну polyline для всего трека или две (одну для динамической части, другую — для статической). Чем длиннее трек, тем больше единая polyline проигрывает разбитой на две. Это связано с тем, что в первом случае в каждом кадре нужно удалять последнюю точку из трека (ту, которая указывает на текущее положение маркера) и добавлять ее заново.
Главная фишка
Работа с канвасами напоминает рисование ручкой на бумаге. Дорисовать линию можно довольно быстро, но чтобы ее потом подвинуть — проще взять новый лист и перерисовать все заново. Рисование треков удачно вписывается в эту технологию. Сама суть трека в том, что это — след за маркером. Идея в том, что при добавлении нового звена не нужно перерисовывать весь трек заново!
Используем два канваса, один — для статичной части треков, другой — для динамической. Динамическую по-прежнему перерисовываем раз в кадр. Статическую — только при сдвигах карты и изменении зума. Когда нужно продлить трек — просто дорисуем новое звено к тому, что уже нарисовано на канвасе. Скорость работы таких треков высокая и не зависит от длины трека. По сути, если бы не сдвиги карты (и еще несколько случаев, когда нужна перерисовка), координаты точек трека можно бы было вообще не запоминать на клиенте.
Simplify.js
Simplify.js создан как будто специально для данной задачи, глупо его не использовать. На дефолтных настройках генератора эффект не виден, однако реальные треки меньше напоминают броуновское движение. В данной задаче скорость важнее точности, поэтому используем быстрый радиальный алгоритм.
Треки на тайлах
Все описанные оптимизации сейчас работают на Aitribune. Примеры гонок — 1, 2. С точки зрения производительности, главное, что сейчас не устраивает — это тормоза в отрисовке при сдвигах карты, когда каждый, даже небольшой, сдвиг вызывает полную перерисовку всех треков. Чтобы решить эту проблему, вместо оверлея будем использовать свой тип карты (custom map type) с тайлами. Тайл — это квадрат со стороной 256 пикселей. При сдвигах карты движок google maps сам достраивает новые квадраты и удаляет старые. Все, что от нас требуется — написать метод, который должен вызываться при достройке нового квадрата:
Статичные куски треков будем рисовать на этом слое, при этом трек рассматриваем как набор отрезков. Возможны два варианта:
Вариант 1: пришли новые данные, нужно достроить трек. В этом случае пробегаем только по новым точкам трека. Для каждого нового отрезка очень быстро можно получить номер(а) квадрата, в котором он содержится. Получили номер квадрата, отрисовали (на картинке: определяем, что из всех существующих тайлах отрезок находится в квадратах (2,3) и (3,3), на них рисуем).
Вариант 2: был сдвиг карты, в результате которого инициализировались новые тайлы. В этом случае нужно заново пробежать по всем отрезкам, но рисовать только те, которые попадают в новые тайлы. При добавлении нового тайла отрисовку нужно запускать не сразу, поскольку тайлы обычно добавляются по нескольку за раз рядами или колонками (на картинке: cдвиг карты влево, при этом справа достраивается новая колонка из тайлов, нужно дорисовать на них все существующие отрезки).
Оверлей карты что это
В программе UI-View есть возможность работы с оверлеями. Что это такое и зачем они нужны? Это проще один раз увидеть, чем об этом много рассказывать и говорить.
Оверлей-файлы располагаются в директории ‘C:\Program Files\UI-View32\OVERLAYS‘ и имеют расширение ‘.pos‘.
Формат оверлей-файлов очень прост. Вы легко можете создавать их сами с помощью любого текстового редактора. Возьмите любой оверлей-файл и посмотрите его с помощь редактора. Многое вам сразу станет понятно по этим примерам: 1) репитеры Польши на 2 м или 70 см, 2) TCPIP-BBS-станции Англии, 3) AX.25-BBS-станции Англии, 4) DX-кластеры, 5) SAT-гейты/шлюзы, 6) узлы. Просмотрите эти файлы внимательно. Аналогично, такие файлы для своих территорий вы можете составлять самостоятельно. Также, потом, вы сможете обмениваться оверлей-файлами с коллегами радиолюбителями.
Что можно хранить в этих файлах? Да что угодно! Простор для творчества тут огромен! Это могут быть: репитеры, BBS-станции, DX-кластеры, SAT-гейты, любимые DX-узлы, погодные станции, автозаправки, гостиницы, инфо-киоски, интересные антенны и др.
Для наглядности и в качестве примера посмотрите на карту расположения репитеров Польши, диапазона 144 MHz с загруженным оверлеем pl-144.pos. Оверлеи pl-144.pos и pl-70.pos составлены радиолюбителями Польши и любезно предоставлены для сайта http://aprs.qrz.ru
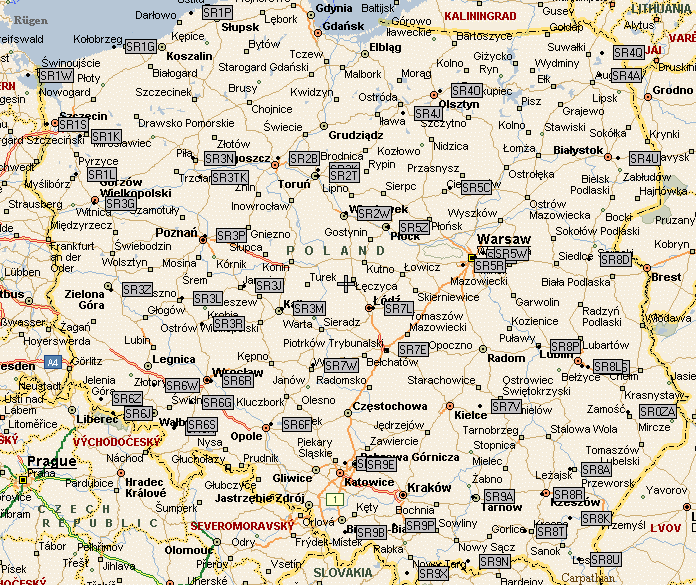
Карта расположения репитеров Польши, диапазона 144 MHz
Если у вас есть интересные и полезные файлы-оверлеи, присылайте их. Лучшие из них будут опубликованы на нашем сайте.
Автоматизация Для Самых Маленьких. Часть первая (которая после нулевой). Виртуализация сети
В предыдущем выпуске я описал фреймворк сетевой автоматизации. По отзывам у некоторых людей даже этот первый подход к проблеме уже разложил некоторые вопросы по полочкам. И это очень меня радует, потому что наша цель в цикле — не обмазать питоновскими скриптами анзибль, а выстроить систему.
Этот же фреймворк задаёт порядок, в котором мы будем разбираться с вопросом.
И виртуализация сети, которой посвящён этот выпуск, не особо укладывается в тематику АДСМ, где мы разбираем автоматику.
Но давайте взглянем на неё под другим углом.
Уже давно одной сетью пользуются многие сервисы. В случае оператора связи это 2G, 3G, LTE, ШПД и B2B, например. В случае ДЦ: связность для разных клиентов, Интернет, блочное хранилище, объектное хранилище.
И все сервисы требуют изоляции друг от друга. Так появились оверлейные сети.
И все сервисы не хотят ждать, когда человек настроит их вручную. Так появились оркестраторы и SDN.
Первый подход к систематической автоматизации сети, точнее её части, давно предпринят и много где внедрён в жизнь: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Вот с ним сегодня и поразбираемся.

Содержание
Причины
И раз уж мы об этом заговорили, то стоит упомянуть предпосылки к виртуализации сети. На самом деле этот процесс начался не вчера.
Наверно, вы не раз слышали, что сеть всегда была самой инертной частью любой системы. И это правда во всех смыслах. Сеть — это базис, на который опирается всё, и производить изменения на ней довольно сложно — сервисы не терпят, когда сеть лежит. Зачастую вывод из эксплуатации одного узла может сложить большую часть приложений и повлиять на много клиентов. Отчасти поэтому сетевая команда может сопротивляться любым изменениям — потому что сейчас оно как-то работает (мы, возможно, даже не знаем как), а тут надо что-то новое настроить, и неизвестно как оно повлияет на сеть.
Чтобы не ждать, когда сетевики прокинут VLAN и любые сервисы не прописывать на каждом узле сети, люди придумали использовать оверлеи — наложенные сети — коих великое многообразие: GRE, IPinIP, MPLS, MPLS L2/L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE итд.
Их привлекательность заключается в двух простых вещах:
Вся серия будет описывать датацентр, состоящий из рядов однотипных стоек, в которых установлено одинаковое серверное оборудование.
На этом оборудовании запускаются виртуальные машины/контейнеры/серверлесс, реализующие сервисы.

Терминология
В цикле сервером я буду называть программу, которая реализует серверную сторону клиент-серверной коммуникации.
Физические машины в стойках называть серверами не будем.
Физическая машина — x86-компьютер, установленный в стойке. Наиболее часто употребим термин хост. Так и будем называть её «машина» или хост.
Гипервизор — приложение, запущенное на физической машине, эмулирующее физические ресурсы, на которых запускаются Виртуальные Машины. Иногда в литературе и сети слово «гипервизор» используют как синоним «хост».
Виртуальная машина — операционная система, запущенная на физической машине поверх гипервизора. Для нас в рамках данного цикла не так уж важно, на самом ли деле это виртуальная машина или просто контейнер. Будем называть это «ВМ«
Тенант — широкое понятие, которое я в этой статье определю как отдельный сервис или отдельный клиент.
Мульти-тенантность или мультиарендность — использование одного и того же приложения разными клиентами/сервисами. При этом изоляция клиентов друг от друга достигается благодаря архитектуре приложения, а не отдельно-запущенным экземплярам.
ToR — Top of the Rack switch — коммутатор, установленный в стойке, к которому подключены все физические машины.
Кроме топологии ToR, разные провайдеры практикуют End of Row (EoR) или Middle of Row (хотя последнее — пренебрежительная редкость и аббревиатуры MoR я не встречал).
Underlay network или подлежащая сеть или андэрлей — физическая сетевая инфраструктура: коммутаторы, маршрутизаторы, кабели.
Overlay network или наложенная сеть или оверлей — виртуальная сеть туннелей, работающая поверх физической.
L3-фабрика или IP-фабрика — потрясающее изобретение человечества, позволяющее к собеседованиям не повторять STP и не учить TRILL. Концепция, в которой вся сеть вплоть до уровня доступа исключительно L3, без VLAN и соответственно огромных растянутых широковещательных доменов. Откуда тут слово «фабрика» разберёмся в следующей части.
SDN — Software Defined Network. Едва ли нуждается в представлении. Подход к управлению сетью, когда изменения на сети выполняются не человеком, а программой. Обычно означает вынесение Control Plane за пределы конечных сетевых устройств на контроллер.
NFV — Network Function Virtualization — виртуализация сетевых устройств, предполагающая, что часть функций сети можно запускать в виде виртуальных машин или контейнеров для ускорения внедрения новых сервисов, организации Service Chaining и более простой горизонтальной масштабируемости.
VNF — Virtual Network Function. Конкретное виртуальное устройство: маршрутизатор, коммутатор, файрвол, NAT, IPS/IDS итд.
Я сейчас намеренно упрощаю описание до конкретной реализации, чтобы сильно не запутывать читателя. Для более вдумчивого чтения отсылаю его к секции Ссылки. Кроме того, Рома Горге, критикующий данную статью за неточности, обещает написать отдельный выпуск о технологиях виртуализации серверов и сетей, более глубокую и внимательную к деталям.
Большинство сетей сегодня можно явно разбить на две части:
Underlay — физическая сеть со стабильной конфигурацией.
Overlay — абстракция над Underlay для изоляции тенантов.
Это верно, как для случая ДЦ (который мы разберём в этой статьей), так и для ISP (который мы разбирать не будем, потому что уже было в СДСМ). С энтерпрайзными сетями, конечно, ситуация несколько иная.
Картинка с фокусом на сеть:
Underlay
Underlay — это физическая сеть: аппаратные коммутаторы и кабели. Устройства в андерлее знают, как добраться до физических машин.
Опирается он на стандартные протоколы и технологии. Не в последнюю очередь потому, что аппаратные устройства по сей день работают на проприетарном ПО, не допускающем ни программирование чипа, ни реализацию своих протоколов, соответственно, нужна совместимость с другими вендорами и стандартизация.
А вот кто-нибудь вроде Гугла может себе позволить разработку собственных коммутаторов и отказ от общепринятых протоколов. Но LAN_DC не Гугл.
Underlay сравнительно редко меняется, потому что его задача — базовая IP-связность между физическими машинами. Underlay ничего не знает о запущенных поверх него сервисах, клиентах, тенантах — ему нужно только доставить пакет от одной машины до другой.
Underlay может быть например таким:
Вручную, скриптами, проприетарными утилитами.
Более подробно андерлею будет посвящена следующая статья цикла.
Overlay
Overlay — виртуальная сеть туннелей, натянутая поверх Underlay, она позволяет ВМ одного клиента общаться друг с другом, при этом обеспечивая изоляцию от других клиентов.
Данные клиента инкапсулируются в какие-либо туннелирующие заголовки для передачи через общую сеть.
Так ВМ одного клиента (одного сервиса) могут общаться друг с другом через Overlay, даже не подозревая какой на самом деле путь проходит пакет.
Overlay может быть например таким, как уже я упоминал выше:
Да, это SDN в чистом виде.
Существует два принципиально различающихся подхода к организации Overlay-сети:
Overlay с ToR’a
Overlay может начинаться на коммутаторе доступа (ToR), стоящем в стойке, как это происходит, например, в случае VXLAN-фабрики.
Это проверенный временем на сетях ISP механизм и все вендоры сетевого оборудования его поддерживают.
Однако в этом случае ToR-коммутатор должен уметь разделять различные сервисы, соответственно, а сетевой администратор должен в известной степени сотрудничать с администраторами виртуальных машин и вносить изменения (пусть и автоматически) в конфигурацию устройств.
Тут я отошлю читателя к статье о VxLAN на хабре нашего старого друга @bormoglotx.
В этой презентации с ENOG подробно описаны подходы к строительству сети ДЦ с EVPN VXLAN-фабрикой.
А для более полного погружения в реалии, можно почитать цискину книгу A Modern, Open, and Scalable Fabric: VXLAN EVPN.
Замечу, что VXLAN — это только метод инкапсуляции и терминация туннелей может происходить не на ToR’е, а на хосте, как это происходит в случае OpenStack’а, например.
Однако, VXLAN-фабрика, где overlay начинается на ToR’е является одним из устоявшихся дизайнов оверлейной сети.
Overlay с хоста
Другой подход — начинать и терминировать туннели на конечных хостах.
В этом случае сеть (Underlay) остаётся максимально простой и статичной.
А хост сам делает все необходимые инкапсуляции.
Для этого потребуется, безусловно, запускать специальное приложение на хостах, но оно того стоит.
Во-первых, запустить клиент на linux-машине проще или, скажем так, — вообще возможно — в то время как на коммутаторе, скорее всего, придётся пока обращаться к проприетарным SDN-решениям, что убивает идею мультивендорности.
Во-вторых, ToR-коммутатор в этом случае можно оставить максимально простым, как с точки зрения Control Plane’а, так и Data Plane’а. Действительно — с SDN-контроллером ему тогда общаться не нужно, и хранить сети/ARP’ы всех подключенных клиентов — тоже — достаточно знать IP-адрес физической машины, что кратно облегчает таблицы коммутации/маршрутизации.
В серии АДСМ я выбираю подход оверлея с хоста — далее мы говорим только о нём и возвращаться к VXLAN-фабрике мы уже не будем.
Проще всего рассмотреть на примерах. И в качестве подопытного мы возьмём OpenSource’ную SDN платформу OpenContrail, ныне известную как Tungsten Fabric.
В конце статьи я приведу некоторые размышления на тему аналогии с OpenFlow и OpenvSwitch.
На примере Tungsten Fabric
На каждой физической машине есть vRouter — виртуальный маршрутизатор, который знает о подключенных к нему сетях и каким клиентам они принадлежат — по сути — PE-маршрутизатор. Для каждого клиента он поддерживает изолированную таблицу маршрутизации (читай VRF). И собственно vRouter делает Overlay’ное туннелирование.
Чуть подробнее про vRouter — в конце статьи.
Каждая ВМ, расположенная на гипервизоре, соединяется с vRouter’ом этой машины через TAP-интерфейс.
TAP — Terminal Access Point — виртуальный интерфейс в ядре linux, которые позволяет осуществлять сетевое взаимодействие.
Если за vRouter’ом находится несколько сетей, то для каждой из них создаётся виртуальный интерфейс, на который назначается IP-адрес — он будет адресом шлюза по умолчанию.
Все сети одного клиента помещаются в один VRF (одну таблицу), разных — в разные.
Сделаю тут оговорку, что не всё так просто, и отправлю любознательного читателя в конец статьи.
Чтобы vRouter’ы могли общаться друг с другом, а соответственно и ВМ, находящиеся за ними, они обмениваются маршрутной информацией через SDN-контроллер.
Чтобы выбраться во внешний мир, существует точка выхода из матрицы — шлюз виртуальной сети VNGW — Virtual Network GateWay (термин мой).
Теперь рассмотрим примеры коммуникаций — и будет ясность.
Коммуникация внутри одной физической машины
VM0 хочет отправить пакет на VM2. Предположим пока, что это ВМ одного клиента.
Data Plane
Пакет в этом случае не попадает в физическую сеть — он смаршрутизировался внутри vRouter’а.
Control Plane
Гипервизор при запуске виртуальной машины сообщает ей:
И снова, реальная процедура взаимодействия упрощена в угоду понимания концепции.
Таким образом все ВМ одного клиента на данной машине vRouter видит как непосредственно подключенные сети и может сам между ними маршрутизировать.
А вот VM0 и VM1 принадлежат разным клиентам, соответственно, находятся в разных таблицах vRouter’а.
Смогут ли они друг с другом общаться напрямую, зависит от настроек vRouter и дизайна сети.
Например, если ВМ обоих клиентов используют публичные адреса, или NAT происходит на самом vRouter’е, то можно сделать и прямую маршрутизацию на vRouter.
В противной же ситуации возможно