Что такое регрессионный анализ?
Регрессионный анализ — это набор статистических методов оценки отношений между переменными. Его можно использовать для оценки степени взаимосвязи между переменными и для моделирования будущей зависимости. По сути, регрессионные методы показывают, как по изменениям «независимых переменных» можно зафиксировать изменение «зависимой переменной».
Зависимую переменную в бизнесе называют предиктором (характеристика, за изменением которой наблюдают). Это может быть уровень продаж, риски, ценообразование, производительность и так далее. Независимые переменные — те, которые могут объяснять поведение выше приведенных факторов (время года, покупательная способность населения, место продаж и многое другое).Регрессионный анализ включает несколько моделей. Наиболее распространенные из них: линейная, мультилинейная (или множественная линейная) и нелинейная.
Как видно из названий, модели отличаются типом зависимости переменных: линейная описывается линейной функцией; мультилинейная также представляет линейную функцию, но в нее входит больше параметров (независимых переменных); нелинейная модель — та, в которой экспериментальные данные характеризуются функцией, являющейся нелинейной (показательной, логарифмической, тригонометрической и так далее).
Чаще всего используются простые линейные и мультилинейные модели.
Регрессионный анализ предлагает множество приложений в различных дисциплинах, включая финансы.
Рассмотрим поподробнее принципы построения и адаптации результатов метода.
Линейный регрессионный анализ основан на шести фундаментальных предположениях:
Простая линейная модель выражается с помощью следующего уравнения:
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.
Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

Случайная величина может быть интерпретирована как сумма из двух слагаемых:

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.
Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.

В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
Перейдем теперь к расшифровке полученных результатов.

Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
Прогнозирование. Регрессионный анализ, его реализация и прогнозирование
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Сущность метода регрессионного анализа
Одним из методов, используемых для прогнозирования, является регрессионный анализ.
Регрессия – это статистический метод, который позволяет найти уравнение, наилучшим образом описывающее совокупность данных, заданных таблицей.

На графике данные отображаются точками. Регрессия позволяет подобрать к этим точкам кривую у=f(x), которая вычисляется по методу наименьших квадратов и даёт максимальное приближение к табличным данным.
Линейная регрессия
Линейная регрессия дает возможность наилучшим образом провести прямую линию через точки одномерного массива данных (рис.13.1 а). Уравнение с одной независимой переменной, описывающее прямую линию, имеет вид:
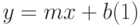
где:x – независимая переменная;
y – зависимая переменная;
m – характеристика наклона прямой;
b – точка пересечения прямой с осью у.
Например, имея данные о реализации товаров за год с помощью линейной регрессии можно получить коэффициенты прямой (1) и, предполагая дальнейший линейный рост, получить прогноз реализации на следующий год.
Нелинейная регрессия
Нелинейная регрессия позволяет подбирать к табличным данным нелинейное уравнение (рис. 13.1 рис. 13.1, б.) – параболу, гиперболу и др. Excel реализует нелинейность в виде экспоненты, т.е. подбирает кривую вида:
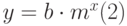 ,
,
которая позволяет наилучшим образом провести экспоненциальную кривую по точкам данных, которые изменяются нелинейно.
Так, например, данные о росте населения почти всегда лучше описываются не прямой линией, а экспоненциальной кривой. При этом нужно помнить, что достоверное прогнозирование возможно только на участках подъёма или спуска кривой (при отрицательных значениях х), т.к. сама кривая (2) изменяется монотонно, без точек перегиба. Например, делать экспоненциальный прогноз для функции, изменяющейся синусоидально, можно только на участках подъёма или спуска функции, для чего её разбивают на соответствующие интервалы.
Множественная регрессия
Множественная регрессия представляет собой анализ более одного набора данных аргумента х и даёт более реалистичные результаты.
Множественный регрессионный анализ также может быть как линейным, так и экспоненциальным. Уравнение регрессии (1) и (2) примут соответственно вид (3) и (4):
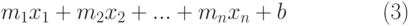 | ( 3) |
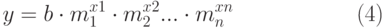 | ( 4) |
С помощью множественной регрессии, например, можно оценить стоимость дома в некотором районе, основываясь на данных его площади, размерах участка земли, этажности, вида из окон и т.д.
Использование функций регрессии
В Excel имеется 5 функций для линейной регрессии: ЛИНЕЙН(…)(LINEST), ТЕНДЕНЦИЯ(…), ПРЕДСКАЗ(…), НАКЛОН(…), СТОШУХ(…)) и 2 функции для экспоненциальной регрессии – ЛГРФПРИБЛ(…) и РОСТ(…).
Рассмотрим некоторые из них.
Функция ЛИНЕЙН((LINEST) вычисляет коэффициент m и постоянную b для уравнения прямой (1). Синтаксис функции:
Известные_значения_у и известные_значения_х – это множество значений у и необязательное множество значений х (их вводить необязательно), которые уже известны для соотношения (1).
Константа – это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
Статистика – это логическое значение, которое указывает требуется ли вывести дополнительную статистику по регрессии.
| mn | mn-1 | … | m2 | m1 | b |
|---|---|---|---|---|---|
| sen | sen-1 | … | se2 | se1 | seb |
| r 2 | sey | … | #Н/Д | #Н/Д | #Н/Д |
| F | df | … | #Н/Д | #Н/Д | #Н/Д |
| ssreg | ssresid | … | #Н/Д | #Н/Д | #Н/Д |
seb – стандартное значение ошибки для постоянной b (seb равно #Н/Д, т.е. «нет допустимого значения», если конст. имеет значение ЛОЖЬ);
r 2 – коэффициент детерминированности. Сравниваются фактические значения у и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями у. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений у;
sey – стандартная ошибка для оценки у (предельное отклонение для у);
F – F-cтатистика, или F-наблюдаемое значение. Она используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df – степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надёжности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН;
ssreg – регрессионная сумма квадратов;
ssresid – остаточная сумма квадратов;
#Н/Д – ошибка, означающая «нет доступного значения».
Любую прямую можно задать её наклоном m и у-пересечением:
Если для функции у имеется только одна независимая переменная х, можно получить наклон и у-пересечение непосредственно, используя следующие формулы:
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точными являются модель, используемая функцией ЛИНЕЙН, и значения, получаемые из уравнения прямой.
В случае экспоненциальной регрессии аналогом функции (5) является функция ЛГРФПРИБЛ(LOGEST):
которая отличается лишь тем, что вычисляет коэффициенты m и b для экспоненциальной кривой (2).
Функция ТЕНДЕНЦИЯ(TREND) имеет вид:
возвращает числовые значения, лежащие на прямой линии, наилучшим образом аппроксимирующие известные табличные данные.
Новые_значения_х – это те, для которых необходимо вычислить соответствующие значения у.
Если параметр новые_значения_х пропущен, то считается, что он совпадает с известными х. Назначение остальных параметров функции ТЕНДЕНЦИЯ совпадает с описанными выше.
В случае экспоненциальной регрессии аналогом функции (7) является функция РОСТ(GROWTH):
возвращает стандартную погрешность регрессии – меру погрешности предсказываемого значения у для заданного значения х.
Правила ввода функций
Формулы(5)-(8) являются табличными, т.е. они заменяют собой несколько обычных формул и возвращают не один результат, а массив результатов. Поэтому необходимо соблюдать следующие правила:
Линия тренда
Excel позволяет наглядно отображать тенденцию данных с помощью линии тренда, которая представляет собой интерполяционную кривую, описывающую отложенные на диаграмме данные.
Для того, чтобы дополнить диаграмму исходных данных линией тренда, необходимо выполнить следующие действия:
Чтобы отобразить на графике (гистограмме и др.) новые, прогнозируемые в результате регрессионного анализа данные, нужно:
На диаграмме появится продолжение кривой, построенной по новым данным.
Простая линейная регрессия
Пример 1. Функция ТЕНДЕНЦИЯ(TREND)
а) Предположим, что фирма может приобрести земельный участок в июле. Фирма собирает информацию о ценах за последние 12 месяцев, начиная с марта, на типичный земельный участок. Название первого столбца «Месяц» с данными о номерах месяцев записано в ячейке А1, а второго столбца «Цена» – в ячейке В1. Номера месяцев с 1 по 12 (известные значения х) записаны в ячейки А2…А13. Известные значения у содержат множество известных значений (133 890 руб., 135 000 руб., 135 790 руб., 137 300 руб., 138 130 руб., 139 100 руб., 139 900 руб., 141 120 руб., 141 890 руб., 143 230 руб., 144 000 руб., 145 290 руб.), которые находятся в ячейках В2;В13 соответственно (данные условия). Новые значения х, т.е. числа 13, 14,15,16,17 введём в ячейки А14…А18. Для того чтобы определить ожидаемые значения цен на март, апрель, май, июнь, июль, выделим любой интервал ячеек, например, B14:B18 (по одной ячейке для каждого месяца) и в строке формул введем функцию:
После нажатия клавиш Ctrl+ Shift+Enter данная функция будет выделена как формула вертикального массива, а в ячейках B14:B18 появится результат: <146172;174190;148208;149226;150244>.
Таким образом, в июле фирма может ожидать цену около 150 244 руб.
б) Тот же результат будет получен, если вводить в формулу не все массивы переменных х и у, а использовать часть массивов, которые предусматриваются автоматически по умолчанию. Тогда формула (10) примет вид:
В формуле (11) используется массив по умолчанию (1:2:3:4:5:6:7:8:9:10:11:12) для аргумента «известные_значения_х», соответствующий 12 месяцам, для которых имеются данные по продажам. Он должен был бы быть помещен в формуле (11) между двумя знаками ;;. Массив (13:14:15:16:17) соответствует следующим 5 месяцам, для которых и получен массив результатов (146172:147190:148208:149226:150244).
Элементы массивов разделяет знак «:», который указывает на то, что они расположены по столбцам.
в) Аргумент «новые значения х» можно задать другим массивом ячеек, например, В14:В18, в которые предварительно записаны те же номера месяцев 13,14,15,16,17. Тогда вводимая в строку формул функция примет вид =ТЕНДЕНЦИЯ(В2:В13;;В14:В18).
Пример 2. Функция ЛИНЕЙН
а) Дана таблица изменения температуры в течение шести часов, введённая в ячейки D2 :E7 (табл. 13.2 таблица 13.2).
Требуется определить температуру во время восьмого часа.
Выделим ячейки D8:E12 для вывода результата, введем в строку ввода формулу =ЛИНЕЙН(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
| 3,142857 | -3,3333333 |
| 0,540848 | 2,106302 |
| 0,894088 | 2,2625312 |
| 33,76744 | 4 |
| 172,8571 | 20,47619 |
Таким образом, коэффициент m=3,143 со стандартной ошибкой 0,541, а свободный член b=-3,333 со стандартной ошибкой 2,106, т.е. функция, описывающая данные табл. 13.2 таблица 13.2, имеет вид
Стандартные ошибки показывают максимально возможное отклонение параметра от рассчитанной величины. Для у оно составляет 2,263, т.е. реальное значение у может лежать в пределах 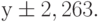 .
.
Точность приближения к табличным данным (коэффициент детерминированности r 2 ) составляет 0,894 или 89,4%, что является высоким показателем. При х=8 получим: у=3,143*8-3,333=21,81 град.
б) Тот же результат можно получить, использовав функцию =ТЕНДЕНЦИЯ(Е2:Е7;;G2:G5) для, например, следующих четырёх часов, предварительно введя в ячейки G2 :G5 числа с 7 до 10. Выделив ячейки Н2:Н5, введя в строку формул эту функцию и нажав Сtrl+Shift+Enter, получим в выделенных ячейках массив <18,667;21,80952;24,95238;28,09524>, т.е. для восьмого часа значение  град.
град.
в) Функция ПРЕДСКАЗ ( FORECAST ) – позволяет предсказать значение у для нового значения х по известным значениям х и у, используя линейное приближение зависимости у=f(x).
Для данных примера 2 ввод формулы =ПРЕДСКАЗ(8;Е2:Е7;D2:D7) выводит в заранее выделенной ячейке результат 21,809. Новое значение х может быть задано не числом, а ячейкой, в которую записано это число.
Отличие функции ПРЕДСКАЗ от функции ТЕНДЕНЦИЯ заключается в том, что ПРЕДСКАЗ прогнозирует значения функции линейного приближения только для одного нового значения х.
Экспоненциальная регрессия
Пример 3
а) Функция ЛГРФПРИБЛ.
Рассмотрим условие примера 2.
| 1,56628015 | 1,196513 |
| 0,02038299 | 0,07938 |
| 0,99181334 | 0,085268 |
| 484,599687 | 4 |
| 3,52335921 | 0,029083 |
Таким образом, коэффициент m=1,566, а b=1,197, т.е. уравнение приближающей кривой имеет вид:
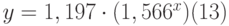
Поскольку интерполяция табл. 13.2 таблица 13.2 экспоненциальной кривой даёт более точное приближение (99,2%) и с меньшими стандартными ошибками для m, b и у, в качестве приближающего уравнения принимаем уравнение (13).
При х=8 получим у=1,197*34,363=41,131 град.
б) Функция РОСТ вычисляет прогнозируемое по экспоненциальному приближению значение у для новых значений х, имеет формат:
Примечание. При выборе экспоненциальной приближающей кривой следует учитывать, что интерполировать ею можно только участки, где функция монотонно возрастает или убывает (при отрицательном аргументе х), т.е. функцию, имеющую точки перегиба (например, параболу, синусоиду, кривую рис. 2 – т. А и др.) следует разбить на участки монотонного изменения от одной точки перегиба до другой и каждый участок интерполировать отдельно. Для рисунка 2 функцию нужно разбить на 2 участка – от начала до т. А и от т. А до конца кривой.
Множественная линейная регрессия
Пример 4
Предположим, что коммерческий агент рассматривает возможность закупки небольших зданий под офисы в традиционном деловом районе. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных:
у – оценочная цена здания под офис;
х1 – общая площадь в квадратных метрах;
х2 – количество офисов;
х3 – количество входов;
х4 – время эксплуатации здания в годах.
Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные:
| А | В | С | D | Е | |
|---|---|---|---|---|---|
| 1 | х1— площадь, м2 | х2 – офисы | х3 – входы | х4 – срок, лет | у – цена, у.е. |
| 2 | 2310 | 2 | 2 | 20 | 42000 |
| 3 | 2333 | 2 | 2 | 12 | 144000 |
| 4 | 2356 | 3 | 1,5 | 33 | 151000 |
| 5 | 2379 | 3 | 2 | 43 | 151000 |
| 6 | 2402 | 2 | 3 | 53 | 139000 |
| 7 | 2425 | 4 | 3 | 23 | 169000 |
| 8 | 2448 | 2 | 1,5 | 99 | 126000 |
| 9 | 2471 | 2 | 2 | 34 | 142000 |
| 10 | 2494 | 3 | 3 | 23 | 163000 |
| 11 | 2517 | 4 | 4 | 55 | 169000 |
| 12 | 2540 | 2 | 3 | 22 | 149000 |
«Пол-входа» означает вход только для доставки корреспонденции.
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (х1,х2,х3,х4) и зависимой переменной (у), т.е. ценой зданий под офис в данном районе.
| А | В | С | D | E | |
|---|---|---|---|---|---|
| 14 | -234,237 | 2553,210 | 12529,7682 | 27,6413 | 52317,83 |
| 15 | 13,2680 | 530,6691 | 400,066838 | 5,42937 | 12237,36 |
| 16 | 0,99674 | 970,5784 | #Н/Д | #Н/Д | #Н/Д |
| 17 | 459,753 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 18 | 1732393319 | 5652135 | #Н/Д | #Н/Д | #Н/Д |
Уравнение множественной регрессии  теперь может быть получено из строки 14:
теперь может быть получено из строки 14:
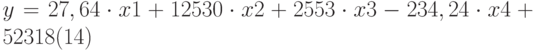
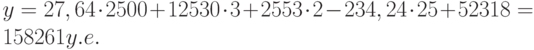
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ:
При интерполяции с помощью функции
для получения уравнения множественной экспоненциальной регрессии выводится результат:
| 0,99835752 | 1,0173792 | 1,0830186 | 1,0001704 | 81510,335 |
| 0,00014837 | 0,0065041 | 0,0048724 | 6,033Е-05 | 0,1365601 |
| 0,99158875 | 0,0105158 | #Н/Д | #Н/Д | #Н/Д |
| 176,832548 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 0,07821851 | 0,0006635 | #Н/Д | #Н/Д | #Н/Д |
| #Н/Д | #Н/Д | #Н/Д | #Н/Д | #Н/Д |
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14).
Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты, свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда.
ЗАДАНИЕ
Вариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
Варианты заданий (номер варианта соответствует номеру компьютера).
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы, сделать прогноз цены на следующий месяц и др. (см. Задание).
Для выполнения задания нужно составить таблицу со столбцами вида:
и сделать множественный регрессионный прогноз (см. Задание).
Для выполнения задания нужно составить таблицу вида:
| Годы | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| х1-хлеб, кг | 23,5 | 26,7 | 27,9 | 30,1 | 31,5 | 35,7 | 38,3 | 40,1 | 41,5 | 42,8 | |
| х2-молоко, л | 20,45 | 22 | 23,8 | 25,9 | 27,4 | 29 | 33,5 | 36,8 | 38,1 | 39,5 | |
| У-доход, р. | 6600 | 7200 | 8400 | 10500 | 12750 | 14730 | 16240 | 17000 | 18050 | 18250 |
и получить два уравнения – у=f(x1) и у=f(x2), сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
Исходные данные нужно ввести в таблицу вида:
| А | В | С | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 1 | х1-эрудиция | х2-энергичность | х3-люди | х4-внешность | х5-знания | Эффективность | |
| 2 | Агент 1 | 0,8 | 0,2 | 0,4 | 0,6 | 1,0 | 76% |
| 3 | Агент 2 | 0,74 | 0,3 | 0,39 | 0,58 | 0,95 | 78% |
| 4 | Агент 3 | 0,67 | 0,41 | 0,35 | 0,5 | 0,83 | 79% |
| 5 | Агент 6 | 0,59 | 0,59 | 0,33 | 0,47 | 0,8 | 80% |
| 6 | Агент 5 | 0,5 | 0,7 | 0,3 | 0,4 | 0,74 | 81% |
| 7 | Средняя эффективность пяти агентов | ||||||
| 8 | Средний агент | 0,5 | 0,5 | 0,5 | 0,5 | 0,5 | |
Для выполнения задания нужно составить и заполнить таблицу вида:
сделать прогноз продаж на новый квартал и выполнить другие пункты задания.
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тираж,тыс. | 100 | 120 | 121,7 | 124,2 | 128 | 130,1 | 133,45 | 136 | 141 | 142,1 | 143,8 | 145 |
| Доход,тыс. руб. | 128 | 135 | 138 | 142 | 147 | 154 | 159 | 161 | 163 | 168 | 170,5 | 172 |
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
Для выполнения задания нужно составить таблицу вида:
| Мес. | Фирма | Конкурент 1 | Конкурент 2 | Конкурент 3 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | У-объём | х1-цена | х2-объём | х3-цена | х4-объём | х5-цена | х6-объём | х7-цена |
| 2 | 10000 | 1875 | 12000 | 1720 | 12500 | 1740 | 11970 | 1700 |
| 3 | 11000 | 1850 | 12340 | 1705 | 12620 | 1735 | 12100 | 1690 |
| 4 | 11570 | 1810 | 12750 | 1675 | 12740 | 1710 | 12350 | 1645 |
| 5 | 11850 | 1750 | 12910 | 1630 | 12960 | 1695 | 12500 | 1615 |
| 6 | 12100 | 1685 | 13100 | 1615 | 13000 | 1674 | 12630 | 1580 |
| 7 | 12340 | 1630 | 13570 | 1600 | 13210 | 1625 | 12920 | 1545 |
| 8 | 12750 | 1615 | 13820 | 1575 | 13320 | 1610 | 13150 | 1520 |
| 9 | 12910 | 1600 | 13980 | 1515 | 13460 | 1560 | 13300 | 1500 |
| 10 | 13100 | 1575 | 14000 | 1500 | 13600 | 1525 | 13610 | 1490 |
| 11 | 13230 | 1530 | 14070 | 1495 | 13780 | 1500 | 13850 | 1485 |
| 12 | 13470 | 1510 | 14120 | 1488 | 13900 | 1460 | 14000 | 1475 |
| 13 | ||||||||
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Доллар | 24,5 | 24,9 | 25,7 | 26,9 | 28,0 | 28,8 | 29,3 | 29,7 | 30,5 | 30,9 | 31,8 | |
| Марка | 72,1 | 76,3 | 79,6 | 85,3 | 89,7 | 90,9 | 93,2 | 96,4 | 100,2 | 101,6 | 104,9 |
и сделать линейный прогноз на следующие 6 месяцев и др. (см. Задание).
Для выполнения задания нужно составить и заполнить таблицу вида:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | месяц | х1 | х2 | х3 | y=у2/у1*100% |
| 2 | 1 | 15 | 10 | 24 | 78% |
| 3 | 2 | 16 | 11 | 23 | 80% |
| 4 | 3 | 18 | 12 | 22 | 81% |
| 5 | 4 | 19 | 12 | 22 | 84% |
| 6 | 5 | 21 | 13 | 21 | 85% |
| 7 | 6 | 22 | 14 | 20 | 89% |
| 8 | 7 |
и выполнить применительно к таблице пункты Задания.
Для выполнения задания нужно составить и заполнить таблицу вида
| Годы | х1 | х2 | х3 | х4 | х5 | х6 | х7 | Расход  | Доход | Кредит(Y) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 1,3 | 1 | 0,3 | 5 | 4 | 18,6 | 21,4 | 3,1 |
| 2 | 5,2 | 2,2 | 1,2 | 1,2 | 0,4 | 4,8 | 4,5 | 19,5 | 22 | 2,5 |
| 3 | 5,5 | 2,5 | 1,1 | 1,4 | 0,6 | 4,6 | 4,9 | 20,6 | 23,4 | 2,8 |
| 4 | 5,8 | 2,7 | 0,9 | 1,6 | 1 | 4,2 | 5,6 | 21,8 | 25,8 | 4 |
| 5 | 7 | 3 | 0,8 | 2 | 1,2 | 4 | 6,5 | 24,7 | 26,2 | 1,5 |
| 6 | 7,5 | 3,3 | 0,7 | 2,2 | 1,5 | 3,8 | 7 | 26,5 | 27,5 |
В ячейках столбца  ) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
| Квартиры | X1 | X2 | X3 | X4 | X5 | Стоимость ( y ) |
|---|---|---|---|---|---|---|
| 1 | 41 | 33 | 7 | 1 | 2 | 42000 |
| 2 | 40 | 30 | 7,7 | 2 | 3 | 40000 |
| 3 | 45 | 37 | 8 | 0 | 5 | 47000 |
| 4 | 46,3 | 34 | 9 | 1 | 6 | 49500 |
| 5 | 50 | 36 | 9 | 1 | 4 | 51000 |
| 6 | 53 | 40 | 9,5 | 1 | 7 | 55000 |
| 7 | 56 | 41 | 10 | 0 | 9 | 62000 |
| 8 | 60 | 47 | 12 | 2 | 10 | 62300 |
| 9 | 65 | 49 | 14 | 2 | 12 | 69000 |
| 10 | 70 | 58 | 14,5 | 2 | 14 | 72000 |
| 11 | 28 | 16 | 6 | 0 | 1 |
| Годы | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Родились | 100 | 110 | 130 | 155 | 170 | 174 | 180 | 185 | 190 | 200 | |
| Умерли | 108 | 115 | 135 | 160 | 178 | 180 | 186 | 190 | 197 | 205 |
Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
| Матричные принтеры | Струйные принтеры | Лазерные принтеры | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Спрос у1 | Цена х1 | Рас.мат. z1 | Спрос у2 | Цена х2 | Рас.мат. z/2 | Спрос у3 | Цена х3 | Рас.мат. z3 | |
| 1 | 56 | 4172 | 174 | 26 | 2384 | 558 | 13 | 12517 | 1558 |
| 2 | 58 | 4250 | 179 | 24 | 2398 | 570 | 11 | 12984 | 1612 |
| 3 | 60 | 4289 | 182 | 23 | 2401 | 598 | 9 | 13259 | 1789 |
| 4 | 65 | 4297 | 194 | 20 | 2456 | 649 | 8 | 13687 | 1865 |
| 5 | 69 | 4305 | 205 | 19 | 2512 | 722 | 7 | 14013 | 1998 |
| 6 | 75 | 4318 | 213 | 18 | 2543 | 768 | 6 | 14587 | 2200 |
| 7 | 4456 | 220 | 17 | 2601 | 779 | 5 | 14789 | 2245 | |
Необходимо сделать прогноз на седьмой месяц по уравнению у1=f(x1,z1), получить уравнение y=(у2,x2, z2, у3, x3, z2 ) и проанализировать его. Если слагаемые у2 и у3 входят в регрессионное уравнение со знаком «-«, то уменьшение спросов у2 и у3 ведёт к увеличению спроса у1.
| Годы | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Динамика населения (тыс. чел) | 21,5 | 26,1 | 31,5 | 34,9 | 45,1 | 50,8 | 56 | 59,4 | 63,9 | 67,1 | |
| Динамика продаж (тыс. шт.) | 2,5 | 2,9 | 3,4 | 3,9 | 4,1 | 4,8 | 5 | 5,6 | 5,9 | 6,2 |
Пользуясь данными таблицы
| Издания | х1 | х2 | х3 | х4 | х5 | х6 | Отклики, у |
|---|---|---|---|---|---|---|---|
| 1 | 10000 | 13 | 700 | 15000 | 4 | 1 | 108 |
| 2 | 12500 | 12 | 850 | 22000 | 8 | 1 | 115 |
| 3 | 15890 | 11,8 | 960 | 28000 | 10 | 0 | 120 |
| 4 | 17850 | 11 | 1200 | 32000 | 26 | 1 | 128 |
| 5 | 15000 | 10 | 1000 | 25000 | 4 | 0 |
необходимо сделать прогноз при заданных характеристиках.
| Месяцы | Издание 1 | Издание 2 | ||
|---|---|---|---|---|
| Звонки | Сделки | Звонки | Сделки | |
| 1 | 98 | 66 | 112 | 79 |
| 2 | 105 | 72 | 143 | 85 |
| 3 | 105 | 75 | 150 | 90 |
| 4 | 110 | 80 | 130 | 100 |
| 5 | 125 | 90 | 120 | 75 |
| 6 | 140 | 100 | 115 | 80 |
| 7 | 136 | 95 | 128 | 82 |
| 8 | 137 | 87 | 132 | 78 |
| 9 | 145 | 102 | 138 | 88 |
| 10 | 123 | 75 | 143 | 92 |
| 11 | 130 | 79 | 150 | 97 |
| 12 | 139 | 88 | 155 | 97 |
| 13 | ||||
Эффективность определяется как сделки/звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям.
Пользуясь данными таблицы
сделать прогноз и выполнить другие пункты задания.
| Месяц | Радиостанция 1 | Радиостанция 2 | ||
|---|---|---|---|---|
| Аудитория | Цена 1 мин. | Аудитория | Цена 1 мин. | |
| 1 | 250000 | 8000 | 300000 | 7560 |
| 2 | 540000 | 6500 | 450000 | 6340 |
| 3 | 580000 | 6460 | 490000 | 6250 |
| 4 | 650000 | 6300 | 550000 | 6000 |
| 5 | 730000 | 6060 | 610000 | 5730 |
| 6 | 750000 | 6000 | 690000 | 5300 |
| 7 | 800000 | 5400 | 750000 | 5100 |
| 8 | 840000 | 5320 | 780000 | 5000 |
| 9 | 890000 | 5130 | 870000 | 4700 |
| 10 | 950000 | 5000 | 900000 | 4650 |
| 11 | 1000000 | 4800 | 940000 | 4600 |
| 12 | 1108000 | 4700 | 1025000 | 4540 |
| 13 | ||||
| Контакт | ||||
В строке «Контакт» в ячейках С8 и D8 должны быть записаны формулы = С7/В7 и =Е7/D7 соответственно, вычисляющие стоимость 1 мин. Эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев.



