16 сервисов для работы с семантическим ядром
Сделал подборку из 16 сервисов для сбора и работы с семантическим ядром.
У сервиса большой инструментарий для работы с семантикой.
SemRush покажет вам, на какие ключевые слова следует обратить внимание, чтобы обойти конкурентов. Поможет узнать общие и уникальные ключевые слова доменов. Есть базы ключевых слов для 26 стран.
Всем известный сервис для анализа поисковых запросов в Яндексе. Есть возможность смотреть статистику поисковой фразы по регионам, похожие поисковые запросы и историю запросов в разрезе года.
Расширение для браузеров, которое позволяет значительно ускорить ручной сбор слов из Яндекс Wordstat. С помощью расширения вы сможете одним кликом выбрать все ключевые слова на странице и копировать в буфер обмена.
Бесплатная версия Keyword Tool генерирует до 750 + ключевых слов для каждого поискового запроса. Собирает поисковые подсказки, частотность и может анализировать домены конкурентов. Сервис позиционирует себя, как лучшая альтернатива планировщику ключевых слов Google.
Профессиональный инструмент для работы с семантическим ядром сайта. Собирает статистику поисковых запросов Google, Яндекс, Mail, поисковые подсказки Google и Яндекс и еще много всего.
Сервис умеет анализировать позиций поисковых запросов в Яндекс и Google. Парсить ключи из Яндекс Wordstat, собирать подсказки Яндекса, Google и YouTube.
Сервис, позволяющий получать информацию о рекламных кампаниях конкурентов. Работает по гео: Москва, Санкт-Петербург, Киев, Астана. Что вы сможете узнать о конкуренте: ключевые запросы, тексты объявлений, позиции, получите оценку трафика и бюджета.
8. Планировщик ключевых слов Google (в Google Ads)
Инструмент ищет и прогнозирует эффективность ключевых слов (трафик, бюджет, ctr, cpc) для рекламы в Google Ads. Найденные ключевые слова можно в один клик загрузить в рекламную кампанию Google Ads
Платформа состоящая из пяти блоков: анализ обратных ссылок, SEO-аудит сайта, анализ семантики, аналитика конкурентов, мониторинг позиций.
Быстрый сбор семантики, кластеризация запросов и выгрузка данных в csv или xlsx
Сервис быстро собирает ключи из wordstat, поисковые подсказки и частотность. Есть настройки по региону, глубине частотности, может парсить ставки Яндекс Директа.
Статистика по ключевым запросам за год. Оценка конкуренции по каждому ключевику. Еще сервис предлагает идеи ключевых слов. (интересная функция)
Сервис для парсинга поисковых запросов. Бесплатная версия сервиса сильно урезана. Есть такие инструменты как: дополняющие фразы, базы запросов, сравнение сайтов, чистка неявных дублей, доля конкурентов по фразам и т.д.
Широкий инструментарий для работы с ключевиками. (есть бесплатная версия) Сервис может: парсить ключи из Яндекс Wordstat, пересекать и склонять фразы, выделять уникальные ключи из списка и подсчитывать их. Также есть кросс-минусовка фраз, удаление дублей и поиск синонимов.
С помощью Google Trends можно проанализировать популярность поискового запроса в разрезе по городам/субрегионам. Посмотреть похожие запросы. Сравнить свою компанию с конкурентом по популярности в субрегионах. (Данные из поисковика Google)
Сервис подбора ключевых слов.
Есть простой подбор слов (поиск по одному слову) и расширенный (поиск по списку ключевых слов). В бесплатной версии можно выгружать не более 3000 ключевых слов в csv. Сервис может: искать семантическое ядро конкурентов, удалять дубликаты, собирать частотность запросов, группировать словоформы при анализе уникальных слов.
Напишите в комментарии, какими сервисами вы пользуйтесь и можете порекомендовать.
Автор телеграм-канал (@proroas), пишу о digital-маркетинге, сервисах и аналитике. О том, чем пользуюсь в работе сам.
Сколько уже таких статей на ВиСИ было? 100 или больше?
Есть еще Slovoeb, как Key Collector только бесплатный.
Да, но у Slovoeb ограниченные возможности, а в кеу коллекторе можно настроить фильтры и собрать более качественное семантическое ядро.
А чем все эти сервисы лучше: Вордстата и Кейколлектор рт гугла?
Каждый по своему хорош
извините, что немного не в тему.
Подскажите, пожалуйста
Есть сайт, по структуре похож на интернет-магазин.
Нужно написать тайтлы и декрипшн для 60 разлиных страниц: мужская обувь, мужские украшения и аксессуары, женские джинсы и тд, стоит ли для каждой страницы прописывать разные тайтлы и дескрипшн или лучше сделать все одинаковые с заменой основных значений, такие как пол и название категории?
Да кому нужны эти сервисы. Вордстата всегда хватало
Статья просто Magik trands
Про Semtools от Тумайкина забыли, для многих задач незаменимая вещь, причем как для PPC, так и для SEO.
С названиями некоторых сервисов накосячили. Еще не хватает KeyAssort, раз тут не только сервисы.
И с этого получишь кучу. плюсиков. 😁
Почему плюсиков? Там вон в конце ссылка на канал автора.
Лучше конечно, чтобы тайтлы и дескрипшины были разные, это положительно скажется для ранжирования в ПС.
Все до кучи и плагин для браузера (Yandex Wordstat Assistant) и системы помогающие проанализировать конкурентов (Spy Words \ Keys.so) я лично все разные инструменты разложил бы по полочкам.
Потому что когда собираешь семантику (особенно если ты новичок ) важно понимать:
—- какие виды и типы запросов нужны
—- как упростить сложные задачи
—- как автоматизировать процесс
—- и что самое важное (может не стоит заморачиваться самому а заплатить денег)
Все кому интересно чуть больше узнать по семантике читайте в моем блоге
А ещё как распределяют экскурсоводов по группам, зависит ли спрос на поездки от сезона, возраста и пандемии и почему даже просто нейтральный отзыв на гида — это уже тревожный звонок.
Как быстро уточнить частотность запросов в Wordstat
Пошаговая инструкция по использованию парсера Wordstat от PromoPult. Полезные фишки и лайфхаки.
Узнать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы есть парсеры: десктопные программы, расширения для браузеров, облачные сервисы и скрипты. Все они похожи — есть лишь отличия в нюансах работы. Собственный сервис есть и в системе PromoPult. Разбираемся, как он работает и чем он лучше аналогов.
Основные возможности Парсера Wordstat в PromoPult:
Немного теории: зачем знать частотности ключевиков?
Основная причина, по которой собирают частотности, — прогнозирование трафика. Зная, сколько раз пользователи интересовались определенной фразой, можно примерно рассчитать, сколько сайт получит переходов, если займет N-ую позицию в поиске.
Как это работает на практике:
1. Вы сформировали список ключевых фраз, по которым планируете продвигаться.
2. Для фразы, по которой планируете оценить трафик, определяете частотность (например, «купить тахту в Москве» — 2852).
3. Узнаете значения CTR в зависимости от позиции в поиске. Приблизительные данные о распределении CTR можно найти в открытых источниках, но если у вас сайт работает хотя бы несколько месяцев, то более точные данные доступны в отчете Яндекс.Вебмастера «Поисковые запросы» / «Статистика запросов». В нем нужен показатель: «CTR на позициях, %»:
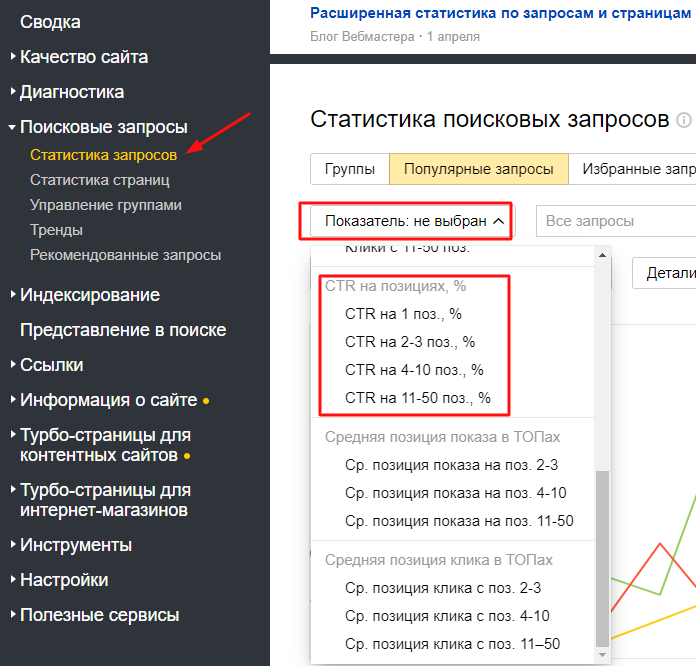
4. Составляете прогноз трафика для ТОП-10. Для этого умножаете частотность на CTR и делите на 100 %.
Допустим, если CTR 2-3 позиции составляет 25 %, то прогнозный трафик при достижении этой позиции равен: 2852*25/100 = 713.
Вторая причина собирать частотности — отсеивание «мусорных» фраз. Это фразы, частотность которых стремится к нулю, и их нет смысла включать на существующие страницы (и тем более создавать под них новые страницы).
Какие именно фразы считать «мусорными»? Здесь все зависит от тематики. Например, если тематика узкая, трафика мало (например, по ключам «покупка аппарата МРТ» или «ремонт Vertu»), и каждый пользователь на вес золота, то можно оставлять и фразы с частотностью 1. Для магазинов масс-маркета отсеивают запросы с частотностью ниже 5. А для информационных сайтов частотность 10-20 вполне может быть нижним пределом. Главное, не переусердствуйте с удалением лишних фраз, иначе есть риск потерять трафик по низкочастотным запросам, который порой составляет до 70-80 % от общего трафика.
Еще одна причина уточнить частотности — выстраивание иерархии запросов на странице. Более частотные запросы добавляют в Title и H1, а под менее частотные — формируют разделы и подразделы.
Продвигать сайт на автомате? С модулем SEO от PromoPult это реально! Внутренняя оптимизация, линкбилдинг, наполнение контентом — все это автоматизируется в пару кликов. Вам лишь остается контролировать результат. Готовы? Поехали!
Как узнать частотности с помощью PromoPult
Этап №1. Загрузка ключевых фраз
Для начала перейдите на страницу Парсера и загрузите запросы, частотности которых необходимо узнать. Сделать это можно двумя способами:
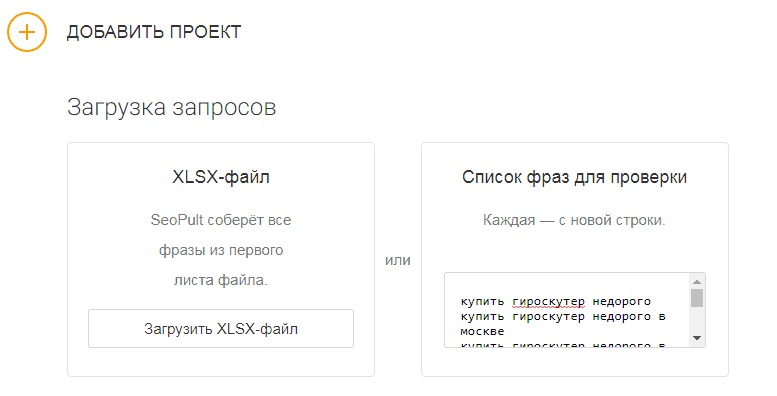
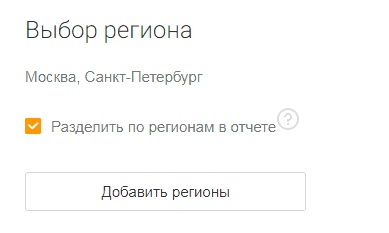
Этап №2. Выбор региона
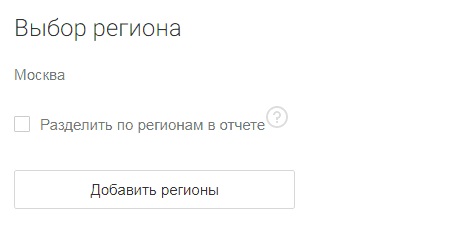
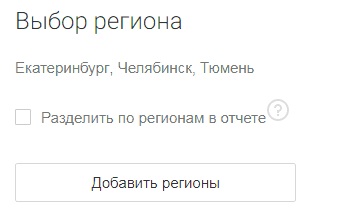
В системе доступны все регионы, которые поддерживает Яндекс. Выбор регионов для парсинга зависит от поставленных задач. Рассмотрим несколько ситуаций:
Хотите расширить базовое семантическое ядро? Вот инструкция как это сделать с помощью фраз-ассоциаций.
Этап №3. Указание параметров сбора частотностей
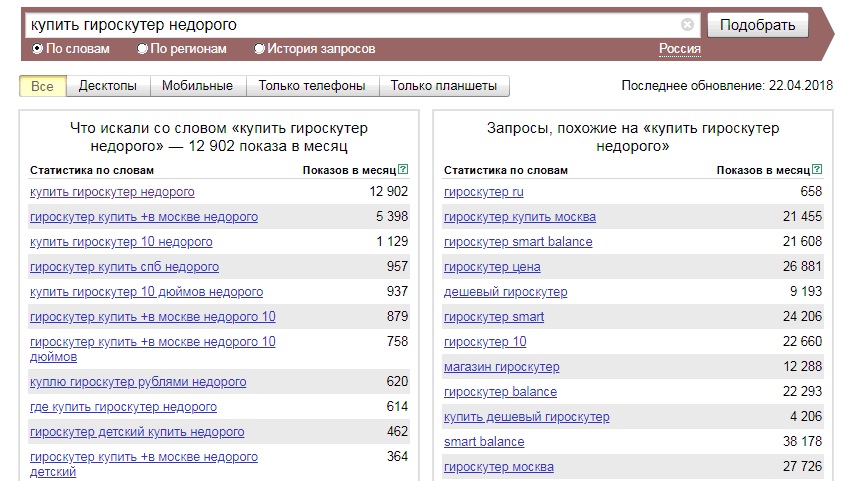
Если в Вордстате просто ввести фразу и запустить сбор частотностей, то вы получите статистику по всем вариантам словоформ (в том числе по фразам, которые включают заданную). Это так называемое широкое соответствие. Например, 12902 показов по фразе «купить гироскутер недорого» не означает, что пользователи 12902 раз вводили эту фразу в таком варианте написания. В эту цифру входят и обращения по фразе «гироскутер купить в Москве недорого», и «куплю гироскутер рублями недорого», и «гироскутер купить в Перми недорого» и мн. др.
Для получения более точной статистики по запросам используются операторы соответствия. О них мы подробно рассказывали в этой статье. Здесь остановимся на тех из них, которые поддерживает инструмент парсинга Wordstat от PromoPult.
1. Широкое соответствие (информация ищется по заданным фразам без дополнительных операторов). В этом случае вы получаете очень широкую статистику, далеко не всегда релевантную и отражающую реальную картину спроса. На это есть несколько причин:
Парсить частотности в широком соответствии полезно лишь с точки зрения общей картины, для понимания тенденций, но для принятия окончательных решений по включению тех или иных запросов в ядро лучше воспользоваться представленными ниже операторами соответствия.
2. Фиксация количества слов (оператор «кавычки»). В этом случае отражается статистика только по заданной фразе, но с учетом различных падежей и перестановки слов. Например, частотность ключа «купить гироскутер недорого» включает частотность фразы «недорого купить гироскутеры», но не включает «купить гироскутер недорого в Москве» или «купить гироскутер». Это намного более точная статистика, чем при широком соответствии, поскольку отражает информацию по конкретному запросу.
4. Фиксация порядка слов (оператор [квадратные скобки]). Этот оператор используется, если для правильной оптимизации страниц важен порядок слов. Классический пример — с покупкой билетов. По фразе «билеты Москва Питер» в широком соответствии будет включена статистика по фразам вроде «билеты Питер Москва», которые подходят для оптимизации страницы поиска билетов из Москвы в Санкт-Петербург. Чтобы этого избежать, искомая фраза берется в квадратные скобки, и тогда статистика будет только по фразам с заданным порядком слов (с учетом разной морфологии).
Лучше всего собирать частотности с учетом всех операторов соответствия. Так у вас будет наиболее полная картина. Если же у вас бюджет ограничен, активируйте хотя бы два типа соответствия — например, широкое и «кавычки».
Обогатить семантическое ядро? Легко! В статье Как быстро собрать поисковые подсказки из Яндекса, Google и Youtube описано, как сделать это без лишних трудозатрат.
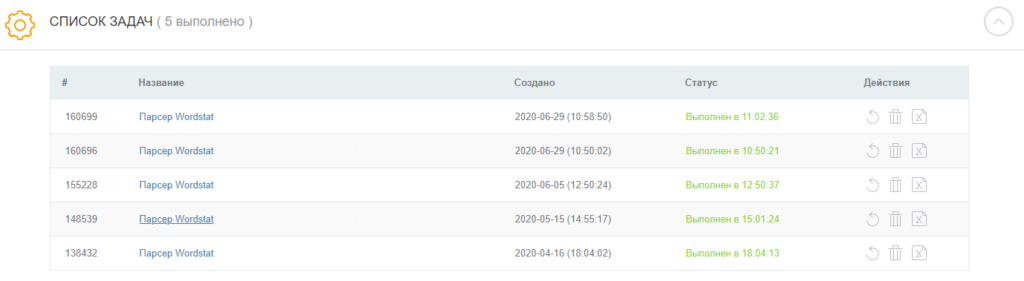
Этап №4. Получение результата
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов не очень много (до 1000), процесс займет не более 1-2 минут. Результат доступен в «Списке задач»:
Для скачивания отчета необходимо кликнуть по соответствующей ссылке. В отчете вы увидите список заданных фраз и частотности напротив каждой из них. Если вы задавали разделение по регионам, то в отчете будет несколько листов, соответствующих каждому региону. Также в каждом отчете есть лист с исходными настройками.
Если у вас нет времени ждать окончания выполнения задачи, вы можете закрыть браузер — парсинг будет идти без вашего участия.
После завершения парсинга система уведомит вас на электронную почту, указанную при регистрации в PromoPult. Отчеты доступны в системе в любое время, поэтому их необязательно скачивать сразу по окончании парсинга.
Если вы по ошибке зададите повторный парсинг с аналогичными исходными данными, то система уведомит вас об этом. Это позволяет избежать лишней траты денег.
После сбора ключей и оценки частотностей запросы необходимо сгруппировать. Лучший способ сделать это — кластеризовать. Вот подробный гайд, который поможет вам в этом.
Сколько стоит инструмент
Для тарификации используется базовая единица — ТЗ (получение данных по одному типу частотности по одной фразе для одного набора регионов).
Если вы указываете несколько регионов, но не активируете опцию «Разделить по регионам в отчете», то количество регионов не влияет на конечную стоимость проверки. Если же вы хотите получить раздельные отчеты по указанным регионам, то стоимость будет увеличиваться пропорционально количеству регионов.
Стоимость формируется по кумулятивному принципу: за первую 1000 ТЗ вы платите по 0,07 руб. за ТЗ, а цена последующих ТЗ снижается согласно таблице тарифов:
Первые 50 запросов — бесплатные.
Приведем несколько примеров расчета бюджета парсинга частотностей:
| Исходные параметры | Количество фраз | ||||
|---|---|---|---|---|---|
| 200 | 2000 | 4000 | 8000 | 15000 | |
| 1 регион, 1 тип соответствия | 14 | 120 | 210 | 340 | 500 |
| 1 регион, 2 типа соответствия | 28 | 210 | 340 | 520 | 800 |
| 1 регион, 4 типа соответствия | 56 | 340 | 520 | 840 | 1400 |
| 5 регионов (без разделения по регионам в отчете), 4 типа соответствия | 56 | 340 | 520 | 840 | 1400 |
| 5 регионов (с разделением по регионам в отчете), 4 типа соответствия | 210 | 1000 | 1800 | 3400 | 6200 |
По сравнению с конкурентами стоимость парсинга в PromoPult в 2-3 раза ниже, особенно если речь идет о проверке большого массива ключей.
Парсер Вордстат — это лишь один из инструментов PromoPult. В разделе «Профессиональные инструменты» вы найдете чекер позиций в Яндексе и Google, парсер мета-тегов и заголовков, кластеризатор, подборщик поисковых подсказок и фраз-ассоциаций, генератор объявлений из YML, нормализатор и комбинатор слов, оптимизатор видео. Большинство инструментов полностью бесплатные.
Работа с Парсером Wordstat: помните о сезонности
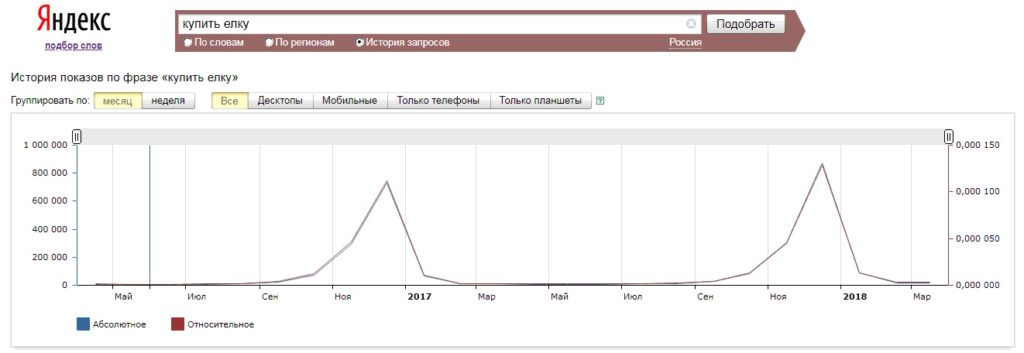
Вордстат выдает статистику за последние 30 дней. Поэтому если по запросу наблюдается сезонный спрос, то полученные данные могут быть завышенными или заниженными. Если вы видите в отчете Парсера нули и подозреваете, что со статистикой что-то не так, перейдите в Вордстат и посмотрите «Историю запросов». Ярко выраженная сезонность будет видна на графике:
Подводим итоги
Парсер Wordstat от PromoPult — это простой инструмент для быстрой проверки частотности по заданному списку фраз. Инструмент работает «в облаке», не требует создания специальных аккаунтов в Яндексе, ввода капчи, работы через прокси и других манипуляций. Выгодно выделяет инструмент возможность парсинга сразу по нескольким регионам и получения отчета с региональной разбивкой. Результаты проверки сохраняются в интерфейсе системы. Стоит парсинг в 2-3 раза дешевле, чем у конкурентов.
Хотите попробовать парсинг в действии? В системе доступно 50 пробных бесплатных проверок!
Как в несколько кликов узнать частотность запросов в Wordstat для всего семантического ядра

Уточнение частотности запросов – очень быстрый и простой способ оценить объем поискового трафика в нише. Вбейте запрос в Яндекс.Вордстат, посмотрите, сколько показов в месяц по запросу, и вот у вас уже есть примерное представление об объеме трафика по ключевому слову.
Но если вам нужно проверить несколько сотен или тысяч запросов, вручную сделать это будет очень трудозатратно. В такой ситуации поможет Парсер Wordstat от Click.ru. В статье рассказываем, для каких задач пригодится инструмент и как быстро спарсить частотность для неограниченного количества фраз.
Возможности Парсера и его преимущества
Парсер Wordstat позволяет быстро собрать частотность для отдельных фраз или целого семантического ядра. Вот, что можно сделать с помощью инструмента:
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.

3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».

К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования. Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
Отсеиваем запросы с частотностью
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Инструкция: как собрать частотность запросов с помощью Парсера Вордстат
1. Добавляем список слов, для которых нужно собрать частотность
Авторизуйтесь в системе Click.ru или пройдите быструю регистрацию, если у вас еще нет аккаунта. Затем перейдите на страницу Парсера Wordstat.
Добавьте новую задачу и загрузите в сервис список запросов. Сделать это можно двумя способами:

2. Задаем регионы для парсинга
После добавления списка запросов можно уточнить параметры парсинга – указать, в каком регионе нужно собрать статистику. Частотность можно собрать по всем регионам, которые доступны для выбора в Яндекс.Вордстат.
В зависимости от того, какие задачи перед вами стоят, выбор целевых регионов будет отличаться.
Вот несколько примеров:
1. Сайт нужно продвигать в одном регионе (если у вас интернет-магазин с ограниченным радиусом доставки, местный информационный портал или вы продвигаете сайт любого другого локального бизнеса). В этом случае выберите нужный регион из списка доступных. Уберите галочку с опции «Разделить по регионам», она вам не понадобится, так как регион всего один.

2. Сайт нужно продвигать в нескольких регионах: основном и нескольких соседних. Актуально для бизнеса, который работает в нескольких соседних регионах. Как правило, для продвижения используется один сайт без поддоменов. Здесь вам необходимо выбрать нужные регионы в настройках Парсера.
Опция «Разделить по регионам» не нужна. Частотность по всем регионам просуммируется, и в отчете вы увидите сводные данные.

3. Нужно продвигать крупный федеральный бизнес, присутствующий во многих регионах. Для продвижения в отдельных регионах используются поддомены. Здесь вам будет полезна опция «Разделить по регионам в отчете» – ее нужно активировать.
После парсинга в отчете будут содержаться отдельные листы для каждого региона и вы сможете оценить потенциал по трафику для каждого региона в отдельности.

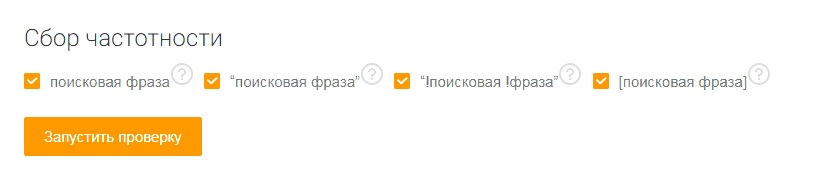
3. Задаем тип соответствия
Если проверять частотность в Яндекс.Вордстат без применения операторов поиска, статистика будет содержать данные по различным вариантам фразы (с измененной словоформой, а также по фразам, в которых содержится исходная). Статистика в этом случае будет собрана по фразе в широком соответствии.
В этом случае вы не получите чистых данных по количеству показов: кроме показов по фразе, которую вы задали, в статистике будут данные по показам по близким фразам.

Если нам нужны более точные данные, необходимо использовать операторы соответствия – специальные символы, которые помогают уточнить запрос. Подробнее об операторах соответствия можно почитать здесь. Мы же вкратце рассмотрим те, которые поддерживаются в Парсере.

1. Широкое соответствие (пункт поисковая фраза, без кавычек). В этом случае вы получаете максимально широкую статистику по всем фразам, содержащим исходную, а также по близким вариантам. Для поверхностной оценки общей картины по трафику в нише этот тип соответствия вполне подходит. Но для принятия взвешенных решений о включении или исключении тех или иных запросов в семантическое ядро лучше использовать операторы соответствия.
Вот несколько факторов, по которым широкое соответствие может искажать реальную картину:
2. Фиксированное количество слов (фразовое соответствие – пункт «поисковая фраза»). Если запрос указан в кавычках, система соберет статистику только по запросам, которые совпадают с исходной фразой по количеству слов. При этом слова могут находиться в фразах в разном порядке и в разных падежах.
Соответственно, в статистику не попадут фразы, которые содержат исходную, но имеют дополнительные слова.
Применение этого типа соответствия позволяет получить более точные данные.
Обратите внимание! При использовании точного соответствия вы можете получить слишком низкую частотность (или даже нулевую), если ниша узкая и трафика там не очень много даже в широком соответствии. Поэтому применяйте этот оператор осторожно, только там, где он действительно необходим для отсеивания нерелевантных показов.
4. Фиксация порядка слов (пункт [поисковая фраза]). С помощью квадратных скобок можно зафиксировать порядок слов в фразе. Для некоторых тематик это имеет огромное значение (например, для продажи билетов или бронирования поездок в определенных направлениях).
Чтобы получить максимально чистую статистику по запросам, рекомендуется использовать все операторы соответствия (за исключением случаев, когда некоторые операторы применять нецелесообразно). Если бюджет на парсинг ограничен, а требования к чистоте статистики не сильно строгие, используйте хотя бы широкое и фразовое (оператор « »).
4. Запускаем парсинг и скачиваем файл с отчетом
После указания всех настроек (регионы и параметры соответствия) запускайте парсинг. Системе потребуется некоторое время для парсинга. Оно зависит от объема списка запросов и настроек: количества типов соответствия и регионов. Как правило, парсинг небольших списков (до 1000 фраз) занимает 1–2 минуты.
В разделе «Список задач» отобразится статус задачи. Если парсинг завершен, отобразится статус «Выполнен», и вы сможете скачать отчет в XLSX-файле.

В отчет входит несколько листов:
Обратите внимание! Если вы повторно попытаетесь запустить парсинг с точно таким же списком ключевых фраз и такими же настройками парсинга, система покажет предупреждение.

Так вы не сможете по ошибке потратить деньги на повторный парсинг. Результаты предыдущих запусков Парсера будут доступны в блоке «Список задач».
Стоимость сервиса
Первые 50 запросов можно спарсить бесплатно. Последующий парсинг платный. Для расчета стоимости используется базовая единица – ТЗ.
1 ТЗ = парсинг данных по 1 фразе в 1 регионе с 1 типом соответствия.
Стоимость 1 ТЗ зависит от общего количества фраз, которое нужно спарсить:

Обратите внимание! Если опция «Разделить по регионам» неактивна, на итоговую стоимость парсинга не влияет количество регионов. Цена 1 ТЗ будет одинаковая: как при выборе одного региона, так и при выборе десяти регионов. Если же вы проставили здесь галочку, итоговая стоимость будет пропорциональна количеству регионов.
Для наглядности приведем примеры бюджета в зависимости от количества фраз, регионов и типов соответствия:

Как использовать Парсер при анализе сезонной семантики
Если вы работаете с нишами, где на спрос существенно влияет сезон, важно понимать специфику работы Яндекс.Вордстат. Сервис отображает статистику только за последние 30 дней, поэтому статистика может быть завышена, если на протяжении последнего месяца был сезонный всплеск, или, наоборот, занижена, если сейчас «не сезон».
Если вы увидели аномальные данные в результатах парсинга (например, по большинству запросов околонулевая частотность), проверьте историю запросов в Вордстате по нескольким фразам. Если запросы «сезонные», вы сразу увидите это:

Используйте Парсер для чистки ядра и прогноза потенциального объема трафика для вашей ниши.
В Click.ru также есть много полезных инструментов, которые пригодятся для решения других задач. Среди сервисов:



