Петабайты данных и быстрый поиск: зачем хранить файлы в облачном объектном хранилище
Большая часть современных компаний работает с огромными объемами данных, которые надо, во-первых, где-то хранить, а во-вторых — не потерять среди них что-нибудь важное. Объектные облачные хранилища (object cloud storage) легко справляются с решением этих проблем. Рассказываем, чем они отличаются от других видов хранилищ и какую информацию там лучше всего хранить.
Что такое объектное S3-хранилище
Объектное хранилище, или object storage, подходит для хранения и управления большими объемами информации: аудио и видеофайлы, документы, сообщения чатов, письма. Его используют, когда традиционная система хранения с множеством файлов и папок становится неудобной и неэффективной.
Компании могут развернуть объектное хранилище в собственном центре обработки данных (ЦОД) или воспользоваться услугой облачных провайдеров. Объектные хранилища взаимодействуют с приложениями через программный интерфейс — то есть, через команды, которые хранилище и приложения передают друг другу. Как правило, это интерфейсы S3 API, Swift API или CDMI.
Наличие стандартного интерфейса у хранилища позволяет без проблем его использовать большинству приложений и систем. S3-совместимые хранилища (S3 compatible storage) сейчас используют чаще всего.
В чем плюсы объектного хранения данных
Бывает, что нужно предоставить доступ к объектам хранения одновременно многим пользователям. Например — видеохостинг должен выдерживать тысячи запросов к выложенному видеоролику. Для таких задач не подходят «обычные» хранилища данных, в том числе — жесткие диски и облачные хранилища других типов, например, такие, где пользователи хранят свои фото: они не оптимизированы под параллельный доступ многих пользователей.
Объектные хранилища реализованы таким образом, что число обращений пользователей к объектам практически не замедляет доступ к ним.
При этом доступ к самому облачному объектному хранилищу данных возможен из любой точки мира, а совокупный объем загружаемых файлов может достигать десятков и сотен петабайт. Посмотрим, для чего его можно использовать.
Облачное объектное хранилище S3: что это такое и как подобрать тариф
ИТ-маркетплейс Market.CNews запустил поиск тарифов по облачным объектным хранилищам S3 для компаний. В рамках данной статьи мы расскажем, что такое объектное хранилище, для чего оно используется, кому нужно и как подобрать тариф.
Что такое объектное хранилище
По мере развития любой организации, ее ИТ-специалисты все чаще сталкиваются с вопросом «Как справиться с постоянно возрастающим объемом данных, которые создают и потребляют пользователи компании?». Среди различных стратегий хранения данных объектное хранилище является одним из самых эффективных решений.
Объектной системой хранения данных называется такой тип хранилища, в котором хранятся данные различного формата и объема в виде объектов с метаданными. Каждый такой объект имеет уникальный идентификатор, благодаря которому приложения находят и обращаются к данным, что значительно упрощает работу систем. Отличительной особенностью является то, что данные хранятся в так называемой плоской среде или, другими словами, на одном уровне, т.е. без использования дерева каталогов.
Для чего нужно объектное хранилище
Объектное хранилище обеспечивают высокую скорость работы с большими объемами данных и тысячами объектов. Такой тип хранилища не подразумевает работу пользователей напрямую, доступ к данным организован на уровне приложений с помощью API.

Чаще всего объектное хранилище используется для целей резервного копирования и архивированная критически важных данных. Среди объектов хранения самыми распространенными являются: статический контент (изображения, видео, аудио, файлы JS и CSS), архивы и резервные копии систем, данные корпоративных, мобильных и веб-приложений (изображений, образов, обновлений ПО), электронный документооборот.
Каким компаниям нужно объектное хранилище
Среди самых частых пользователей объектных хранилищ встречаются компании, занимающиеся проектированием и разработкой, игровые порталы, издательства и информационные агентства, организации, предоставляющие медиаконтент для широкой аудитории, маркетплейсы, социальные сети, образовательные учреждения и многие другие, обладающие большими массивами данных.
Преимущества облачных объектных хранилищ
Основными преимуществами в пользу использования объектных хранилищ являются:
Недостатки облачных объектных хранилищ
Среди замечаний, которые называют ИТ-специалисты можно выделить следующие:
Особенности интерфейса
Несмотря на то, что в целом технологии объектного хранилища развиваются уже более 20 лет, до сих пор нет какого-то одного общепринятого стандарта интерфейса. Но за это время довольно прочно закрепилась тройка самых популярных интерфейсов:
Из чего складывается стоимость услуги
Основными параметрами, от которых зависит стоимость услуги являются:
Как выбрать провайдера облачного хранилища
Для выбора провайдера облачного хранилища воспользуйтесь гибким поиском тарифа на ИТ-маркетплейсе Market.CNews. На нем представлено более десятка поставщиков данной услуги.
Чтобы подобрать подходящий тариф, определите необходимый объем хранилища, тип, частоту и количество запросов к нему и трафик. Обычно холодное хранилище стоит дешевле горячего, но запросы к нему стоят дороже, чем запросы к горячему хранилищу. Подсказка о том, холодное это хранилище или горячее, часто содержится в названии тарифа.
Выводы
Объектное хранилище позволяет хранить любые типы данных в исходном виде, обеспечивает быстрое масштабирование и оптимизирует потребление ресурсов системами компании. Такая организация хранения данных делает инфраструктуру организации более отказоустойчивой и эффективной. Объектные хранилища позволяют обеспечить надежное и продолжительное хранение неограниченного количества данных и файлов, предоставляя доступ к ним через интернет из любой точки мира.
Объектное хранилище для извлечения любых объемов данных из любого места
5 ГБ в хранилище S3 Standard
Масштабируйте ресурсы хранилища, чтобы соответствовать меняющимся потребностям с надежностью данных 99,999999999 % (11 9 секунд).
Храните данные в разных классах хранилища Amazon S3, чтобы сократить затраты за счет отсутствия авансовых вложений или периодического обновления оборудования.
Защитите данные благодаря самым широким возможностям по обеспечению безопасности, соблюдению законодательных требований и аудиту.
С легкостью управляйте данными в любом масштабе с помощью надежных средств контроля доступа, гибких инструментов репликации и
видимости целой организации.
Как это работает


Примеры использования
Создание озера данных
Запустите приложения для аналитики больших данных, искусственного интеллекта (ИИ), машинного обучения (ML) и высокопроизводительных вычислений (HPC), чтобы получить полезную информацию.
Резервное копирование и восстановление критически важных данных
Выполняйте нормативы по времени восстановления (RTO), точкам восстановления (RPO) и законодательные требования с помощью надежных возможностей репликации S3.
Архивация данных по наименьшей цене
Переместите локальные архивы в недорогие классы хранения Amazon S3 Glacier и Amazon S3 Glacier Deep Archive, избавившись от операционных сложностей.
Запуск приложений с оптимизацией для облака
Создавайте быстрые, мощные мобильные и оптимизированные для облака интернет-приложения, которые автоматически масштабируются до самой высокой доступной конфигурации.
Как устроено S3 хранилище DataLine

Не секрет, что в работе современных приложений задействованы огромные объемы данных, и их поток постоянно растет. Эти данные нужно хранить и обрабатывать, зачастую с большого числа машин, и это непростая задача. Для ее решения существуют облачные объектные хранилища. Обычно они представляют из себя реализацию технологии Software Defined Storage.
В начале 2018 года мы запускали (и запустили!) собственное 100% S3-совместимое хранилище на основе Cloudian HyperStore. Как оказалось, в сети очень мало русскоязычных публикаций о самом Cloudian, и еще меньше — о реальном применении этого решения.
Сегодня я, основываясь на опыте DataLine, расскажу вам об архитектуре и внутреннем устройстве ПО Cloudian, в том числе, и о реализации SDS от Cloudian, базирующейся на ряде архитектурных решений Apache Cassandra. Отдельно рассмотрим самое интересное в любом SDS хранилище — логику обеспечения отказоустойчивости и распределения объектов.
Если вы строите свое S3 хранилище или заняты в его обслуживании, эта статья придется вам очень кстати.
В первую очередь, я объясню, почему наш выбор пал на Cloudian. Всё просто: достойных вариантов в этой нише крайне мало. Например, пару лет назад, когда мы только задумывали строительство, опций было всего три:
И да, самое (безусловно!) главное — у DataLine и Cloudian похожие корпоративные цвета. Согласитесь, перед такой красотой мы не могли устоять.
К сожалению, Cloudian — не самое распространенное ПО, и в рунете информации о нём практически нет. Сегодня мы исправим эту несправедливость и поговорим с вами об особенностях архитектуры HyperStore, изучим его наиболее важные компоненты и разберемся с основными архитектурными нюансами. Начнем с самого основного, а именно — что же находится у Cloudian под капотом?
Как устроено хранилище Cloudian HyperStore
Давайте взглянем на схему и посмотрим, как устроено решение от Cloudian.

Основная компонентная схема хранилища.
Как мы видим, система состоит из нескольких основных компонентов:
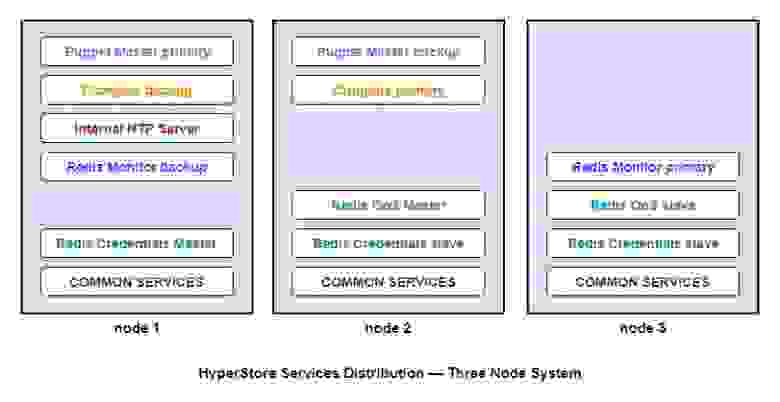
Под common services в схеме выше имеются в виду сервисы S3, HyperStore, CMC и Apache Cassandra. На первый взгляд, все красиво и аккуратно. Но при более детальном рассмотрении выясняется, что эффективно отрабатывается только одиночный отказ ноды. А одновременная потеря сразу двух нод может стать фатальной для доступности кластера — у Redis QoS (на node 2) есть только 1 slave (на node 3). Такая же картина с риском потери управления кластером — Puppet Server есть только на двух нодах (1 и 2). Впрочем, вероятность отказа сразу двух узлов очень невысока, и с этим вполне можно жить.
Тем не менее, для повышения надежности хранилища мы в DataLine используем 4 ноды вместо минимальных трёх. Получается следующее распределение ресурсов:
Сразу бросается в глаза еще один нюанс — Redis Credentials ставится не на каждую ноду (как можно было предположить из официальной схемы выше), а только на 3 из них. При этом Redis Credentials используется при каждом входящем запросе. Получается, из-за необходимости ходить в чужой Redis есть некоторый перекос в производительности четвертой ноды.
Для нас это пока несущественно. При нагрузочном тестировании значительных отклонений в скорости отклика ноды замечено не было, но на больших кластерах в десятки рабочих нод есть смысл поправить этот нюанс.
Вот так выглядит схема миграции на 6 нодах:

Из схемы видно, как реализована миграция сервиса при отказе ноды. Учитывается только случай отказа одного сервера каждой роли. Если упадут оба сервера, потребуется ручное вмешательство.
Здесь дело тоже не обошлось без некоторых тонкостей. Для миграции ролей используется Puppet. Поэтому, если вы потеряете его или случайно сломаете, automatic failover может не сработать. По этой же причине не стоит вручную править манифесты встроенного Puppet. Это не совсем безопасно, изменения могут быть внезапно перетерты, так как манифесты редактируются с помощью админки кластера.
С точки зрения сохранности данных всё значительно интереснее. Метаданные объектов хранятся в Apache Cassandra, и каждая запись реплицирована на 3 ноды из 4-х. Для хранения данных также используется фактор репликации 3, но можно настроить и больший. Это гарантирует сохранность данных даже при одномоментном отказе 2-х нод из 4-х. А при наличии времени на перебалансировку кластера можно и с одной оставшейся нодой ничего не потерять. Главное, чтобы хватило места.

Вот что происходит при отказе двух нод. На схеме хорошо видно, что даже в этой ситуации данные остаются сохранными
При этом доступность данных и хранилища будет зависеть от стратегии обеспечения консистентности. Для данных, метаданных, чтения и записи она настраивается отдельно.
Допустимые варианты — хотя бы одна нода, кворум или все ноды.
Эта настройка определяет, сколько нод должны подтвердить запись/чтение, чтобы запрос считался успешным. Мы используем кворум как разумный компромисс между временем на обработку запроса и надежностью записи/противоречивостью чтения. То есть из трех нод, задействованных в операции, для безошибочной работы достаточно получить непротиворечивый ответ от 2-х. Соответственно, чтобы остаться на плаву при отказе более чем одной ноды, понадобится перейти в стратегию единичной записи/чтения.
Отработка запросов в Cloudian
Ниже мы рассмотрим две схемы отработки входящих запросов в Cloudian HyperStore, PUT и GET. Это основная задача для S3 Service и HyperStore.
Начнем с того, как обрабатывается запрос на запись:
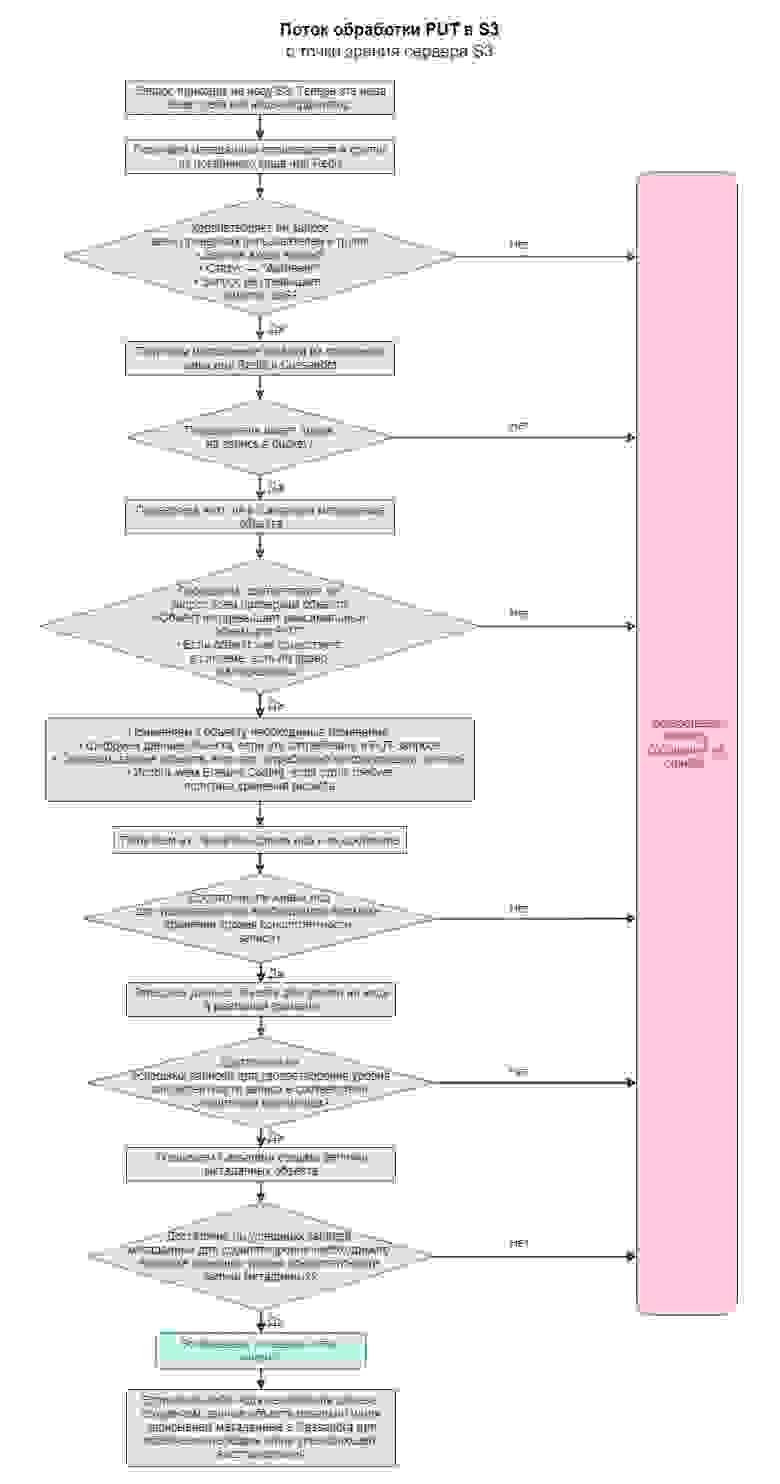
Наверняка вы отметили, что каждый