Что такое графовая БД?
Графовые базы данных предназначены для хранения взаимосвязей и навигации в них. Взаимосвязи в графовых базах данных являются объектами высшего порядка, в которых заключается основная ценность этих баз данных. В графовых базах данных используются узлы для хранения сущностей данных и ребра для хранения взаимосвязей между сущностями. Ребро всегда имеет начальный узел, конечный узел, тип и направление. Ребра могут описывать взаимосвязи типа «родитель‑потомок», действия, права владения и т. п. Ограничения на количество и тип взаимосвязей, которые может иметь узел, отсутствуют.
Обход графа в графовой базе данных можно выполнять либо по определенным типам ребер, либо по всему графу. Обход соединений или взаимосвязей в графовых базах данных выполняется очень быстро, поскольку взаимосвязи между узлами не вычисляются во время выполнения запроса, а хранятся в базе данных. Графовые базы данных имеют ряд преимуществ в таких примерах использования, как социальные сети, сервисы рекомендаций и системы выявления мошенничества, когда требуется создавать взаимосвязи между данными и быстро их запрашивать.
Ниже приведен пример графа социальной сети. Имея данные о людях (узлы) и взаимосвязях между ними (ребра), можно узнать, кто является «друзьями друзей» конкретного человека (например, пользователя по имени Howard).

Примеры использования
Выявление мошенничества
Графовые базы данных позволяют выявлять сложные схемы мошенничества. Анализ взаимосвязей в графовых базах данных дает возможность обрабатывать финансовые операции и операции, связанные с покупками, практически в режиме реального времени. С помощью быстрых запросов к графу можно, например, определить, что потенциальный покупатель использует тот же адрес электронной почты и кредитную карту, которые уже использовались в известном случае мошенничества. Графовые базы данных также позволяют без труда обнаруживать определенные шаблоны взаимосвязей, например когда несколько человек связаны с одним персональным адресом электронной почты или когда несколько человек используют один IP‑адрес, но проживают по разным физическим адресам.
Сервисы рекомендаций
Графовые базы данных – хороший выбор для рекомендательных приложений. Используя графовую базу данных, можно хранить в графе взаимосвязи между такими информационными категориями, как интересы покупателя, его друзья и история его покупок. С помощью высокодоступной графовой базы данных можно рекомендовать пользователям товары на основании того, какие товары приобретали другие пользователи, которые интересуются тем же видом спорта и имеют аналогичную историю покупок. Или можно найти людей, у которых есть общий знакомый, но которые еще не знакомы друг с другом, и предложить им подружиться.
Графовые базы данных на AWS
Amazon Neptune
В основе Amazon Neptune лежит специально созданное высокопроизводительное ядро графовой базы данных, оптимизированное для хранения миллиардов взаимосвязей и выполнения запросов к графу с задержками на уровне миллисекунд. Neptune поддерживает популярные модели графов Property Graph и Resource Description Framework (RDF) консорциума W3C, а также соответствующие языки запросов – Apache TinkerPop Gremlin и SPARQL, что позволяет просто создавать запросы для эффективной навигации по наборам сложносвязанных данных.
В целях обеспечения высокой доступности в сервисе Neptune используются реплики чтения, возможность восстановления на момент времени, постоянное резервное копирование в Amazon S3 и репликация в разных зонах доступности. Сервис Neptune безопасен благодаря поддержке шифрования хранимых данных. Сервис Neptune полностью управляем, поэтому при работе с базами данных больше не требуется заниматься такими административными задачами, как выделение оборудования, установка исправлений ПО, установка и настройка самой базы данных, а также ее резервное копирование.
Графовые базы данных

Светлана Комарова
Автор статьи. Системный администратор, Oracle DBA. Информационные технологии, интернет, телеком. Подробнее.
 Система управления графовыми базами данных (далее графовые базы данных) поддерживает методы создания ( Create ), чтения ( Read ), изменения ( Update ) и удаления ( Delete ) (CRUD), основанные на графовой модели данных. Графовые базы данных, как правило, поддерживают систему транзакций реального времени (OLTP). Соответственно, они оптимизированы для выполнения транзакций и спроектированы с учетом транзакционной целостности и оперативности.
Система управления графовыми базами данных (далее графовые базы данных) поддерживает методы создания ( Create ), чтения ( Read ), изменения ( Update ) и удаления ( Delete ) (CRUD), основанные на графовой модели данных. Графовые базы данных, как правило, поддерживают систему транзакций реального времени (OLTP). Соответственно, они оптимизированы для выполнения транзакций и спроектированы с учетом транзакционной целостности и оперативности.
Имеются две особенности графовых баз данных, которые необходимо учитывать при рассмотрении применяемой ими технологии:
Взаимосвязи в графовой модели данных являются гражданами первого сорта. Здесь к ним относятся не так, как в других системах управления базами данных, где для отображения взаимосвязей применяются такие механизмы, как внешние ключи или внешние операции, например MapReduce. Собирая абстракции узлов и взаимосвязей в связанные структуры, графовая база данных позволяет строить модели любой сложности, лучше всего отражающие предметную область. Полученные модели проще и в то же время нагляднее, чем те, что создаются с помощью традиционных реляционных баз данных или других NOSQL-хранилищ.
На рис. 1 приведен графический обзор некоторых графовых баз данных из представленных сегодня на рынке, основанных на разных моделях хранения и обработки.
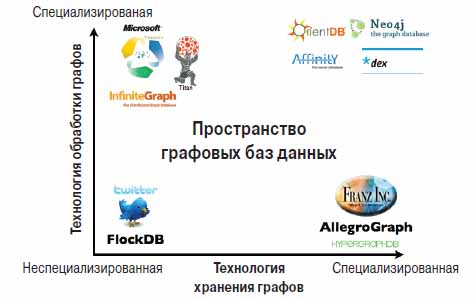
Рис. 1. Обзор графовых баз данных
Механизмы вычисления графов
Механизмы вычисления графов позволяют выполнять глобальные графовые вычислительные алгоритмы для больших наборов данных. Они предназначены для решения таких задач, как идентификация кластеров данных или получение ответов на такие вопросы, как: «Сколько всего взаимосвязей, сколько их в среднем, полна ли социальная сеть?»
Из-за своей направленности на глобальные запросы механизмы вычисления графов, как правило, оптимизированы для сканирования и пакетной обработки больших объемов информации, и в этом отношении они похожи на другие технологии пакетного анализа, такие как интеллектуальный анализ данных (data mining) или аналитическая обработка в реальном времени (OLAP), используемые в реляционном мире. Некоторые механизмы вычисления включают в себя и средства хранения графов, а другие (большинство) заботятся только об обработке данных, получаемых из внешнего источника, а затем возвращают результаты для сохранения в другом месте.
Рисунок 2 иллюстрирует типовую архитектуру развертывания механизмов вычисления графов. Она включает в себя систему записи (System of Record, SOR) базы данных со свойствами OLTP (например, MySQL, Oracle или Neo4j), которая обслуживает запросы и отвечает на запросы, поступающие от приложений (и в конечном счете от пользователей). Периодически задания на извлечение, преобразование и загрузку данных (Extract, Transform, Load, ETL) перемещают данные из системы записи базы данных в механизм вычисления графов для выполнения автономных запросов и анализа.
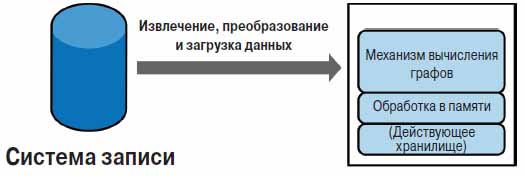
Рис. 2. Укрупненная схема типичной среды движков расчетов графов
Существуют разные типы механизмов вычисления графов. Наиболее известными из них являются одномашинные (in-memory/single machin), такие как Cassovary, и распределенные, такие как Pegasus и Giraph. В основе большинства распределенных механизмов вычисления графов лежит идея, изложенная в статье «Pregel: a system for large-scale graph processing», опубликованной на сайте Google, которая описывает движок Google для классификации страниц.
Преимущества графовых баз данных
Производительность
Одной из веских причин выбора графовой базы данных является большой прирост производительности при работе со взаимосвязанными данными, по сравнению с реляционными базами данных и NOSQL-хранилищами. В отличие от реляционных баз данных, где учет взаимосвязей интенсивно ухудшает производительность запросов на больших наборах данных, производительность графовых баз данных остается неизменной с увеличением объема хранимых данных. Это связано с тем, что запросы локализуются в определенной части графа. В результате время выполнения каждого запроса зависит от размера части графа, которую требуется обойти для удовлетворения запроса, а не от общего размера графа.
Гибкость
Разработчикам и проектировщикам необходимо организовать взаимосвязи между данными, согласно требованиям области применения, структура данных должна соответствовать изменяющимся потребностям, а не навязываться заранее и оставаться неизменной. В графовых базах данных эта задача легко решается. Как мы увидим в главе 3, графовая модель данных отражает и охватывает потребности бизнеса таким образом, что может изменяться со скоростью изменения самого бизнеса.
Присущая графам возможность расширения означает, что можно добавлять новые виды взаимосвязей, новые узлы, новые метки и новые подграфы в существующую структуру, не нарушив при этом существующих запросов и функционала приложения. Это положительно влияет на производительность разработки и снижает риски для проекта. Благодаря гибкости графовой модели не требуется предварительно моделировать задачу в мельчайших подробностях, что очень неудобно из-за быстро меняющихся бизнес-требований. Способность графов к расширению также позволяет уменьшить количество миграций, что снижает нагрузку при обслуживании данных и уменьшает риск потери данных.
Оперативность
Модель данных должна не отставать от прочих составных частей приложения и использовать технологии, соответствующие современным итерационным методам развертывания программного обеспечения. Современные графовые базы данных оснащены всем необходимым для разработки и системного обслуживания. В частности, встроенная графовая модель данных, лишенная схем, в сочетании со встроенным программным интерфейсом (API) и языком запросов позволяет эффективно вести разработку приложений.
В то же время благодаря отсутствию схемы графовые базы данных не предполагают наличия ориентированных на схемы механизмов контроля данных, которые широко применяются в реляционном мире. Но в этом нет ничего страшного, здесь они заменены гораздо более удобными и действенными видами контроля. Как мы увидим в главе 4, контроль выполняется в программной форме, с помощью тестов для моделей данных и запросов, а также с помощью определения бизнесправил, основанных на графе. Сейчас такая методика уже не вызывает сомнений: разработка с помощью графовых баз данных полностью соответствует современным методикам гибкой и надежной разработки программного обеспечения, что позволяет разработке приложений с использованием графовых баз данных не отставать от бизнес-среды.
Итоги
В этой главе мы рассмотрели графовую модель со свойствами, представляющую собой простой, но удобный инструмент для работы со взаимосвязанными данными. Графовая модель со свойствами хорошо моделирует области ее применения, а графовые базы данных облегчают разработку приложений, которые реализуют графовые модели.
В следующем моем блоге мы сравним несколько различных технологий обработки взаимосвязанных данных, начнем с реляционных баз данных, затем перейдем к агрегированным NOSQL-хранилищам и закончим графовыми базами данных. Обсудив их, мы узнаем, почему графы и графовые базы данных являются лучшим средством для моделирования, хранения и выборки взаимосвязанных данных. Затем, в последующих главах, будут описаны проектирование и реализация решений, основывающихся на графовых базах данных.
Знакомство с графовой базой данных Neo4j

Mar 15, 2019 · 6 min read
Содержание
История происхождения графов
Среди жителей Кёнигсберга (нынешний Калиниград) была распространена такая загадка: как пройти по всем городским мостам через реку, не проходя ни по одному из них дважды. Многие пытались решить эту задачу как теоретически, так и практически, во время прогулок. Впрочем, доказать или опровергнуть возможность существования такого маршрута никто не мог.

Решил задачку Леонард Эйлер, сформулировав ряд правил и доказав, что пройти по мостам, не повторяясь, невозможно.
Так и зародилась теория графов.
Что такое граф?
Граф — абстрактный математический объект, представляющий собой множество вершин (точек) и набор рёбер (линий ), то есть соединений между парами вершин.

Ориентированный граф
Ориентиров а нный граф — это граф, ребро которого имеет заданное направление между вершинами.
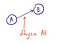
Петля
Если вершина графа соединена ребром сама с собой, то такое ребро называется петлей.

Классификация графов
Связанный граф
Если из любой вершины есть путь до любой другой — такой граф называется связанным.
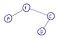
В данном примере есть путь от вершины А до вершины D, хоть он и пролегает через другие вершины.
Сильно связанный граф
Граф называется сильно связанным, если любая его вершина соединена с любой другой ребром. Если связи ориентированные — то граф называется ориентированно связанным.

Взвешенный граф
Если к каждому ребру в соответствие поставлено некоторое число (вес ребра) — такой граф называется взвешенным.
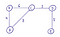
Мультиграф
Граф, в котором разрешается присутствие параллельных ребер, то есть ребер, имеющих те же самые конечные вершины. Параллельные ребра выделены красным.
Где используются графы
Графы используются в геоинформационных системах (ГИС), логистике, социальных сетях, магазинах и других сферах жизни.
Схема метро — взвешенный граф, на ребрах которого указано время перехода между станциями, или прогона состава.
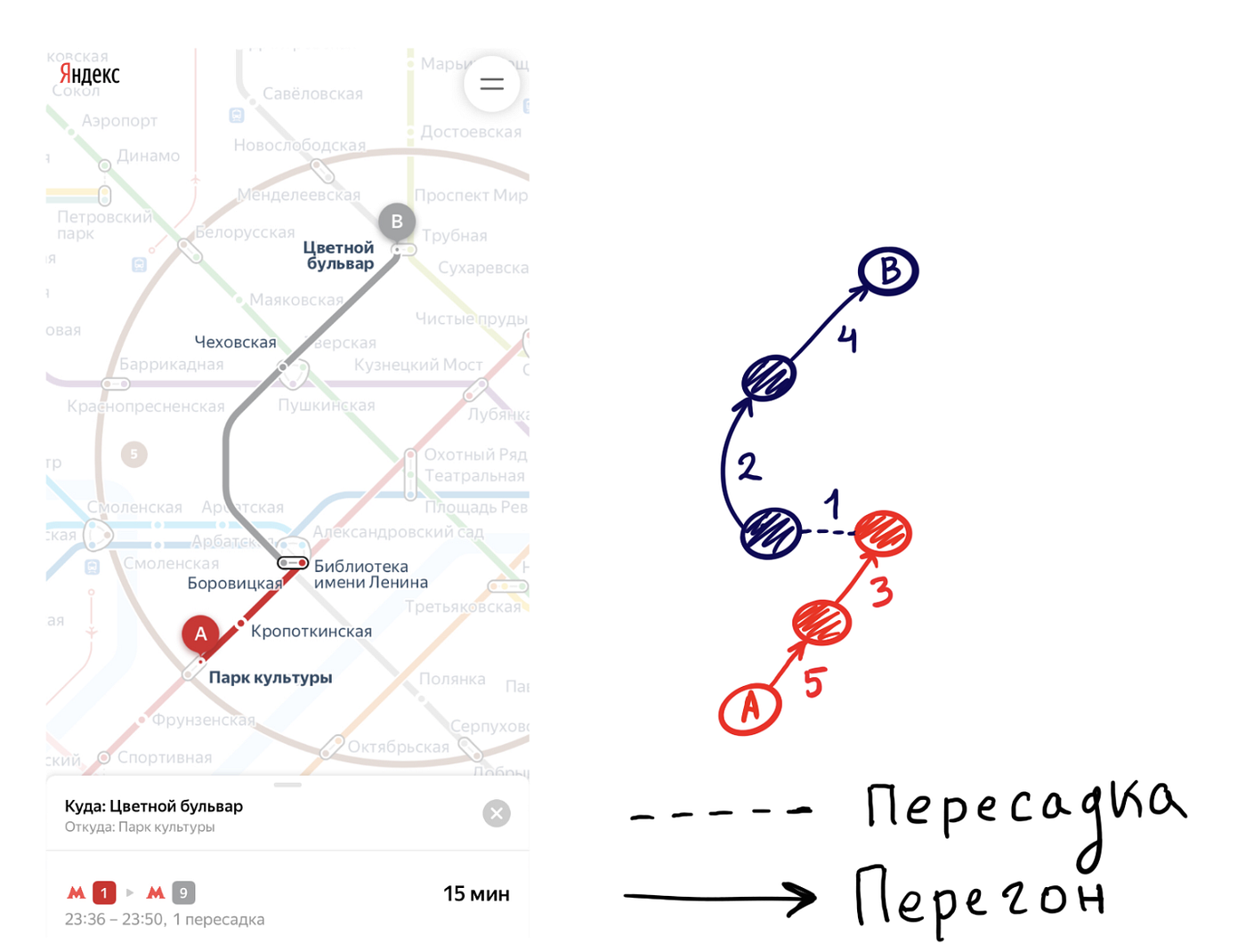
По весам ребер можно посчитать время в пути, так же и выбрать оптимальный путь с помощью какого-либо алгоритма. Алгоритмов поиска кратчайшего пути в графе много, самый известный — алгоритм Дейкстры, вы наверняка о нем слышали.
Карту города тоже можно представить в виде графа.

Данный граф применим в системах навигации для поиска оптимального маршрута. Перекрестки — вершины графа, а дороги — ребра.
Молекулярный граф — связный неориентированный граф, соответсвует формуле химического соединения таким образом, что вершины графа — атомы молекулы, а ребра — химические связи между этими атомами.

Наиболее частный пример графов в разработке — граф социальной сети, в котором отображены дружеские отношения между людьми, их вкусовые предпочтения и прочее.

Даже 3D-объект можно представить в виде графа:

Каждая вершина хранит координаты x, y, z.
Граф — довольно абстрактная вещь, поэтому ее можно применить практически во всех сферах жизни.
Графовые базы
Первая графовая СУБД Neo4j создана в 2007 году, сейчас их уже десятки, наиболее популярные:
Neo4j

Графовая СУБД с открытым исходным кодом, реализована на Java компанией Neo Technology.
Не уступает по производительности реляционным базам данных благодаря собственному формату хранения данных.
Приложение может взаимодействовать с БД по одному из протоколов:
Продолжим знакомство с Neo4j на примере стандартной БД “Movie”
Пользователь может просматривать БД с помощью Neo4j Browser
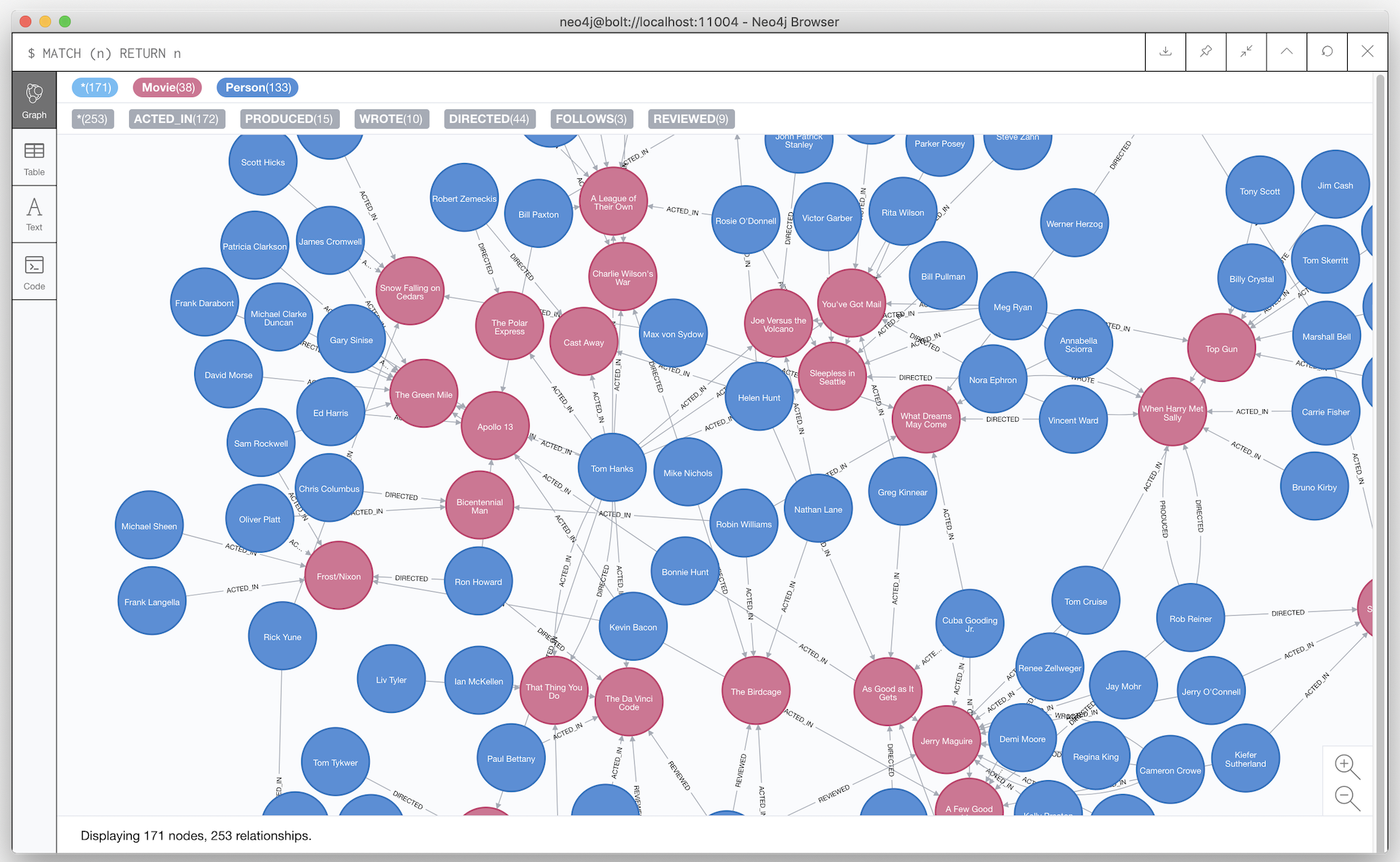
Вершины графа в Neo4j имеют свой тип, в БД Movie у нас 2 типа вершин:
* Person (name — имя актера, born — год рождения)
* Movie (title — наименование фильма, released — год выхода)
Если проводить аналогию с реляционными базами, то Person и Movie — это таблицы.
Для работы с БД используется язык запросов Cypher.
Cypher
Cypher — декларативный язык запросов в виде графа, позволяющий получить выразительный и эффективный