Математика для искусственных нейронных сетей для новичков, часть 3 — градиентный спуск продолжение
В предыдущей части я начал разбор алгоритма оптимизации под названием градиентный спуск. Предыдущая статья оборвалась на писании варианта алгоритма под названием пакетный градиентный спуск.
Существует и другая версия алгоритма — стохастический градиентный спуск. Стохастический = случайный.
Повторять, пока не сойдется
<
for i in train_set
<
>
>
Также напомню как выглядит пакетный:
Повторять, пока не сойдется
<
>
Формулы похожи, но, как видно, пакетный градиентный спуск вычисляет один шаг, используя сразу весь набор данных, тогда как стохастический за шаг использует только 1 элемент. Можно два этих варианта скрестить, получив мини-пакетный (mini-batch) спуск, который за раз обрабатывает, к примеру, 100 элементов, а не все или один.
Два этих варианта ведут себя похоже, но не одинаково. Пакетный спуск действительно следует в направлении наискорейшего спуска, тогда как стохастический, используя только один элемент из обучающей выборки, не может верно вычислить градиент для всей выборки. Это различие проще пояснить графически. Для этого я модифицирую код из первой части, в котором вычислялись коэффициенты линейной регрессии. Функция стоимости для нее выглядит следующим образом:
Как видно, это немного вытянутый параболоид. И также его «вид сверху», где крестом отмечен истинный минимум, найденный аналитически.
Сперва рассмотрим, как ведет себя пакетный спуск:
Из-за того, что параболоид вытянутый, по его «дну» проходит «овраг», в который мы попадаем. Из-за этого последние шаги вдоль этого оврага очень маленькие, но тем не менее рано или поздно градиентный спуск доберется до минимума. Спуск происходит по линии антиградиента, каждый шаг приближаясь к минимуму.
Теперь та же самая функция, но для стохастического спуска:
В определении сказано, что выбирается только один элемент — в этом коде каждый последующий элемент выбирается случайным образом.
Как видно, в случае стохастического варианта, спуск идет не по линии антиградиента, а вообще непонятно как — каждый шаг отклоняясь в случайную сторону. Может показаться, что такими случайными дергаными движениями к минимуму можно прийти только случайно, однако было доказано, что стохастический градиентный спуск сходится почти наверное. Пару ссылок, например.
На 200 элементах разницы в скорости почти никакой нет, однако, увеличив количество элементов до 2000 (что тоже очень мало) и подкорректировав скорость обучения, стохастический вариант бьет пакетный, как хочет. Однако, в силу стохастической природы, иногда метод промахивается, осциллируя возле минимума без возможности остановиться. Как-то так:
Этот факт делает неприменимой чистую реализацию. Чтобы как-то призвать к порядку и снизить «случайность» можно снизить скорость обучения. На практике применяют mini-batch вариацию — от стохастической она отличается тем, что вместо одного случайно выбранного элемента выбирают больше одного.
О разнице, плюсах и минусах данных двух подходов написано достаточно много, вкратце подведу итог:
— Пакетный спуск хорош для строго выпуклых функций, потому что уверенно стремится к минимуму глобальному или локальному.
— Стохастический в свою очередь лучше работает на функциях с большим количеством локальных минимумов — каждый шаг есть шанс, что очередное значение «выбьет» из локальной ямы и конечное решение будет более оптимальным, нежели для пакетного спуска.
— Стохастический вычисляется быстрее — на каждом шаге нужны не все элементы из выборки. Вся выборка целиком может не влезть в память. Но требуется больше шагов.
— Для стохастического легко добавить новые элементы во время работы («онлайн» обучение).
— В случае mini-batch, можно также векторизовать код, что значительно ускорит его выполнение.
Также у градиентного спуска существует множество модификаций — momentum, наискорейшего спуска, усреднение, Adagrad, AdaDelta, RMSProp и другие. Здесь можно посмотреть короткий обзор некоторых. Частенько они используют значения градиента с предыдущих шагов или автоматически вычисляют наизначение скорости для данного шага. Использование этих методов для простой гладкой функции МНК не имеет особого смысла, но в случае нейронных сетей и сетей с большим количеством слоев\нейронов, функция стоимости становится совсем грустной и градиентный спуск может застрять в локальной яме, так и не достигнув оптимального решения. Для таких проблем подходят методы на стероидах. Вот пример функции простой для минимизации (двумерная линейная регрессия с МНК):
И пример нелинейной функции:
Градиентный спуск — метод оптимизации первого порядка (первая производная). Также существует много методов второго порядка — для них необходимо вычислять вторую производную и строить гессиан (довольно затратная операция — ). Например, градиентный спуск второго порядка (скорость обучения заменили на гессиан), BFGS, сопряженные градиенты, метод Ньютона и еще огромное количество других методов. В общем, оптимизация — это отдельный и очень широкий пласт проблем. Впрочем, вот пример (правда, всего лишь презентация) работы + видео Яна Лекуна, в который он говорит, что можно не парится и просто использовать градиентные методы. Даже учитывая, что презентация 2007 года, многие последние эксперименты с большими ИНС использовали градиентные методы. Например.
На голых циклах далеко не уедешь — код нуждается в векторизации. Основной алгоритм для векторизации — пакетный градиентный спуск, с оговоркой, что , где k — количество элементов в тестовой выборке. Таким образом векторизация подходит для mini-batch метода. Как и в прошлый раз я выпишу все в раскрытых векторах. Обратите внимание что первая матрица транспонирована —
Для доказательства, пройдем пару шагов в обратную сторону:
В предыдущей формуле, в каждой строке индекс j зафиксирован, а i — изменяется от 1 до n. Свернув сумму:
Это выражение точно такое же, что и в определении градиентного спуска. Наконец, завершающий шаг — сворачивание векторов и матриц:
Стоимость одного такого шага — , где n — количество элементов, p — количество признаков. Много лучше . Также встречается выражение, тождественное этому:
Обратите внимание, что поменялись местами предсказанное значение и реальное, что привело к изменению знака перед скоростью обучения.
Метод градиентного спуска
Материал из MachineLearning.
Содержание
Введение
Пусть функция такова, что можно вычислить ее градиент. Тогда можно применить метод градиентного спуска, описанный в данной статье.
В статье приведены теоремы сходимости метода градиентного спуска, а также рассмотрена его варианты:
Метод градиентного спуска
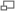
Идея метода
Основная идея метода заключается в том, чтобы осуществлять оптимизацию в направлении наискорейшего спуска, а это направление задаётся антиградиентом :
Алгоритм
Выход: найденная точка оптимума
Критерий останова
Критерии остановки процесса приближенного нахождения минимума могут быть основаны на различных соображениях. Некоторые из них:
Сходимость градиентного спуска с постоянным шагом
Теорема 1 о сходимости метода градиентного спуска спуска с постоянным шагом.
Тогда при любом выборе начального приближения.
В условиях теоремы градиентный метод обеспечивает сходимость либо к точной нижней грани (если функция не имеет минимума) либо к значению Существуют примеры, когда в точке реализуется седло, а не минимум. Тем не менее, на практике методы градиентного спуска обычно обходят седловые точки и находят локальные минимумы целевой функции.
Определение. Дифференцируемая функция называется сильно выпуклой (с константой 0″ alt= «\Lambda>0»/>), если для любых и из справедливо
Теорема 2 о сходимости метода градиентного спуска спуска с постоянным шагом.
Тогда при любом выборе начального приближения.
Выбор оптимального шага
При таком выборе шага оценка сходимости будет наилучшей и будет характеризоваться величиной:
Но даже для хорошо обусловленных функций проблема выбора шага нетривиальна в силу отсутствия априорной информации о минимизируемой функции. Если шаг выбирается малым (чтобы гарантировать сходимость), то метод сходится медленно. Увеличение же шага (с целью ускорения сходимости) может привести к расходимости метода. Далее будут описаны два алгоритма автоматического выбора шага, позволяющие частично обойти указанные трудности.
Градиентный метод с дроблением шага
В этом варианте градиентного метода величина шага на каждой итерации выбирается из условия выполнения неравенства
где  — некоторая заранее выбранная константа.
— некоторая заранее выбранная константа.
Метод наискорейшего спуска
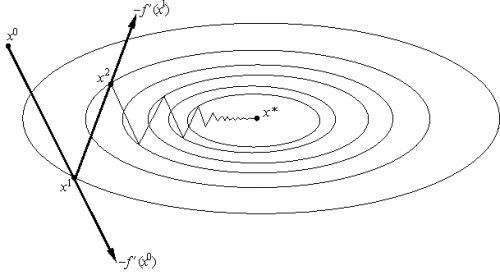
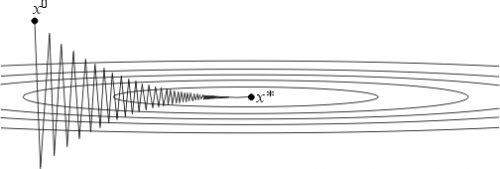
Этот вариант градиентного метода основывается на выборе шага из следующего соображения. Из точки будем двигаться в направлении антиградиента до тех пор пока не достигнем минимума функции f на этом направлении, т. е. на луче :
Другими словами, выбирается так, чтобы следующая итерация была точкой минимума функции f на луче L (см. рис. 3). Такой вариант градиентного метода называется методом наискорейшего спуска. Заметим, кстати, что в этом методе направления соседних шагов ортогональны.
Метод наискорейшего спуска требует решения на каждом шаге задачи одномерной оптимизации. Практика показывает, что этот метод часто требует меньшего числа операций, чем градиентный метод с постоянным шагом.
В общей ситуации, тем не менее, теоретическая скорость сходимости метода наискорейшего спуска не выше скорости сходимости градиентного метода с постоянным (оптимальным) шагом.
Числовые примеры
Метод градиентного спуска с постоянным шагом
Для исследования сходимости метода градиентного спуска с постоянным шагом была выбрана функция:
Результаты эксперимента отражены в таблице:
| Значение шага | Достигнутая точность | Количество итераций |
|---|---|---|
| 0.1 | метод расходится | |
| 0.01 | 2e-4 | 320 |
| 0.001 | 2e-3 | 2648 |
| 0.0001 | 1e-2 | 20734 |
Из полученных результатов можно сделать вывод, что при слишком большом чаге метод расходится, при слишком малом сходится медленно и точчность хуже. Надо выбирать шаг наибольшим из тех, при которых метод сходится.
Градиентный метод с дроблением шага
Для исследования сходимости метода градиентного спуска с дроблением шага (2) была выбрана функция:
Результаты эксперимента отражены в таблице:
| Значение параметра | Значение параметра | Значение параметра | Достигнутая точность | Количество итераций |
|---|---|---|---|---|
| 0.95 | 0.95 | 1 | 5e-4 | 629 |
| 0.1 | 0.95 | 1 | 1e-5 | 41 |
| 0.1 | 0.1 | 1 | 2e-4 | 320 |
| 0.1 | 0.95 | 0.01 | 2e-4 | 320 |
Метод наискорейшего спуска
Для исследования сходимости метода наискорейшего спуска была выбрана функция:
Для решения одномерных задач оптимизации использован метод золотого сечения.
Метод получил точность 6e-8 за 9 итераций.
Отсюда можно сделать вывод, что метод наискорейшего спуска сходится быстрее, чем градиентный метод с дроблением шага и метод градиентного спуска с постоянным шагом.
Недостатком методом наискорейшего спуска явлляется необходимость решать одномерную задачу оптимизации.
Рекомендации программисту
При программировании методов градиентного спуска следует аккуратно относится к выбору параметров, а именно
Заключение
Методы градиентного спуска являются достаточно мощным инструментом решения задач оптимизации. Главным недостатком методов является ограниченная область применимости.
Математика для искусственных нейронных сетей для новичков, часть 2 — градиентный спуск
В первой части я забыл упомянуть, что если случайно сгенерированные данные не по душе, то можно взять любой подходящий пример отсюда. Можно почувствовать себя ботаником, виноделом, продавцом. И все это не вставая со стула. В наличии множество наборов данных и одно условие — при публикации указывать откуда взял данные, чтобы другие смогли воспроизвести результаты.
Градиентный спуск
В прошлой части был показан пример вычисления параметров линейной регрессии с помощью метода наименьших квадратов. Параметры были найдены аналитически — , где — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
Проблема заключается в том, что вычисление псевдообратной матрицы очень затратно: 2 умножения по , нахождение обратной матрицы — , умножение матрицы вектор , где n — количество элементов в матрице A (количество признаков * количество элементов в тестовой выборке) Если количество элементов в матрице A велико (> 10^6 — например), то даже если в наличии 10000 ядер, нахождение решения аналитически может затянуться. Также первая производная может оказаться нелинейной, что усложнит решение, аналитического решения может не оказаться вовсе или данные могут просто не влезть в память и потребуется итеративный алгоритм. Бывает, что в плюсы записывают и то, что численное решение не идеально точное. В связи с этим функцию стоимости минимизируют численными методами. Задачу нахождения экстремума называют задачей оптимизации. В этой части я остановлюсь на методе оптимизации, который называется градиентный спуск.
Не будем отходить от линейной регрессии и МНК и обозначим функцию потерь как — она осталась неизменной. Напомню, что градиент — это вектор вида , где — это частная производная. Одним из свойств градиента является то, что он указывает направление, в котором некоторая функция f возрастает больше всего. Доказательство этого следует из определения производной. Пара доказательств. Возьмем некоторую точку a — в окрестности этой точки функция F должна быть определена и дифференцируема, тогда вектор антиградиента будет указывать на направление, в котором функция F убывает быстрее всего. Отсюда делается вывод, что в некоторой точке b, равной , при некотором малом значение функции будет меньше либо равным значению в точке а. Можно представить это, как движение вниз по холму — сделав шаг вниз, текущая позиция будет ниже, чем предыдущая. Таким образом, на каждом следующем шаге высота будет как минимум не увеличиваться. Формальное определение. Исходя из этих определений можно получить формулу для нахождения неизвестных параметров (это просто переписанная версия формулы выше):
— это шаг метода. В задачах машинного обучения его называют скоростью обучения.
Метод очень прост и интуитивен, возьмем простой двумерный пример для демонстрации:
Необходимо минимизировать функцию вида . Минимизировать значит найти при каком значении функция принимает минимальное значение. Определим последовательность действий:
1) Необходима производная по :
2) Установим начальное значение = 0
3) Установим размер шага — попробуем несколько значений — 0.1, 0.9, 1.2, чтобы посмотреть как этот выбор повлияет на сходимость.
4) 25 раз подряд выполним указанную выше формулу: Так как неизвестный параметр только один, то и формула только одна.
Код крайне прост. Исключая определение функций, весь алгоритм уместился в 3 строки:
Весь процесс можно визуализировать примерно так (синяя точка — значение на предыдущем шаге, красная — текущее):
Или же для шага другого размера:
При значении, равном 1.2, метод расходится, каждый шаг опускаясь не ниже, а наоборот выше, устремляясь в бесконечность. Шаг в простой реализации подбирается вручную и его размер зависит от данных — на каких-нибудь ненормализованных значениях с большим градиентом и 0.0001 может приводить к расхождению.
Вот еще пример с «плохой» функцией. В первой анимации метод также расходится и будет долго блуждать по холмам из-за слишком высокого шага. Во втором случае был найден локальный минимум и варьируя значение скорости не получится заставить метод найти минимум глобальный. Этот факт является одним недостатков метода — он может найти глобальный минимум только если функция выпуклая и гладкая. Или если повезет с начальными значениями.
Плохая функция:
Также возможно рассмотреть работу алгоритма на трехмерном графике. Часто рисуют только изолинии какой-то фигуры. Я взял простой параболоид вращения: . В 3D выглядит он так: , а график с изолиниями — «вид сверху».
Также обратите внимание, что все линии градиента, направлены перпендикулярно изолиниям. Это означает, что двигаясь в сторону антиградиента, не получится за один шаг сразу же прыгнуть в минимум — градиент указывает совсем не туда.
После графического пояснения, найдем формулу для вычисления неизвестных параметров линейной регрессии с МНК.
Если бы количество элементов в тестовой выборке было равно единице, то формулу можно было бы так и оставить и считать. В случае, когда в наличии n элементов алгоритм выглядит так:
Повторять v раз
<
для каждого j одновременно.
>, где n — количество элементов в обучающей выборке, v — количество итераций
Требование одновременности означает, что производная должна быть вычислена со старыми значениями theta, не стоит вычислять сначала отдельно первый параметр, затем второй и т.д., потому что после изменения первого параметра отдельно, производная также изменит свое значение. Псевдокод одновременного изменения:
Если вычислять значения параметров по одиночке, то это уже будет не градиентный спуск. Допустим, у нас трехмерная фигура и если вычислять параметры один за одним, то можно представить этот процесс как движение только по одной координате за раз — один шажок по x координате, затем шажок по y координате и т.д. ступеньками, вместо движения в сторону вектора антиградиента.
Приведенный выше вариант алгоритма называют пакетный градиентный спуск. Количество повторений можно заменить на фразу «Повторять, пока не сойдется». Эта фраза означает, что параметры будут корректироваться до тех пор, пока предыдущее и текущее значения функции стоимости не сравняются. Это значит, что локальный или глобальный минимум найден и дальше алгоритм не пойдет. На практике равенства достичь невозможно и вводится предел сходимости . Его устанавливают какой-нибудь малой величиной и критерием остановки является то, что разность предыдущего и текущего значений меньше предела сходимости — это значит, что минимум достигнут с нужной, установленной точностью. Выше точности (меньше ) — больше итераций алгоритма. Выглядит это как-то так:
Так как пост неожиданно растянулся, я бы хотел его на этом завершить — в следующей части я продолжу разбор градиентного спуска для линейной регрессии с МНК.



