Топ-10 причин падения серверов
— Ты чего такой грустный?
— Да вот сервер вчера «упал».
— Ну да, ты что его до сих пор не «поднял»?
— Поднял, но он со стола упал.
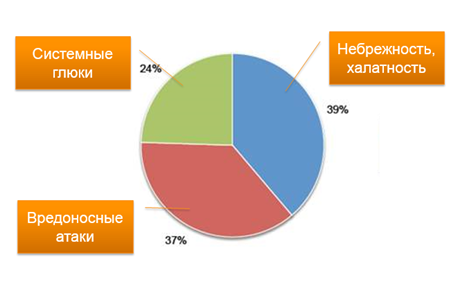
10 место. Резервное копирование. Системные администраторы бывают двух видов: которые делают резервные копии и которые пока не делают резервные копии. Бывает еще и третий вид, но очень редкий: системные администраторы, которые проверяют свои резервные копии. На них вся надежда.
8 место. Оборудование. Вместо серверных платформ используются обычные рабочие станции. Бывали случаи, когда база 1С лежала у бухгалтера на рабочем компьютере на диске D, и даже резервных копий никто не делал! Вопиющая смелость!
7 место. Использование нелицензионного ПО. Был случай, когда один товарищ пытался убедить меня в то, что весть его софт абсолютно лицензионный. Дабы подтвердить свои слова, мне был продемонстрирован лицензионный компакт-диск со всем софтом, купленный в фирменной палатке на Ждановичах. Чек прилагался.
6 место. Плановые замены HDD. Примерно раз в два-три месяца слышу новую историю про рассыпавшийся RAID. Для серверных винчестеров ресурс составляет не более 4 лет. Еще одной частой ошибкой является использование дешевых, не серверных винчестеров, что также весьма чревато. Еще я рекомендую при покупке нового оборудования закупать парочку винчестеров в запас, на всякий пожарный.
5 место. Запуск нескольких сервисов на одном сервере. Говорят, системные администраторы не смешиваю. Все они смешивают! Особенно любят администраторы смешивать контроллеры домена с чем-нибудь еще, например, с MS SQL и с 1C, файловым сервером, прокси-сервером и др. Лет 5 назад это не вызвало бы больших нареканий, но сегодня нравы поменялись, смешивать как минимум, неприлично, как максимум, небезопасно.
4 место. Встроенная учетная запись администратора. Как взломать сервер: берем шару и подбираем пароль к встроенной учетной записи администратора. Если пароль состоит из 4 цифр – пара минут, и сервер наш! А всего-то нужно было учетную запись отключить, а еще лучше и переименовать, да через групповые политики.
2 место. Брандмауэр. Какими бы крепкими ни были стены города, они не защитят жителей от больного чумой внутри периметра. Конечно, все дома в городе забором не обнесешь, а вот улочку с серверами обгородить вполне возможно, более того, сисадмины могут сделать это бесплатно и быстро, а если повезет, то и качественно.
В очередной раз мы видим, как данные статистики сходятся с жизненными реалиями. А как дела обстоят у вас?
Андрей Махнач
руководитель отдела инфраструктурных решений СООО «ДПА»
Как привести в порядок перегруженный сервер?
Материал, перевод которого мы сегодня публикуем, посвящён поиску узких мест в производительности серверов, исправлению проблем, улучшению производительности систем и предотвращению падения производительности. Здесь, на пути к решению проблем перегруженного сервера, предлагается сделать следующие 4 шага:
1. Оценка ситуации
Когда трафик перегружает сервер, узким местом производительности могут стать процессор, сеть, память, дисковая подсистема ввода-вывода. Определение того, что именно вызывает проблему, позволяет сконцентрировать усилия на самом важном. Рассмотрим некоторые особенности анализа важнейших серверных подсистем.
Начать работу по выявлению проблем сервера можно, воспользовавшись командой top. Если есть такая возможность, здесь можно прибегнуть к историческим данным хостинг-провайдера и к данным, собранным системами мониторинга.
2. Стабилизация сервера
Наличие в системе перегруженного сервера может быстро привести к каскадным отказам в других частях системы. В результате важно, после того, как стало известно о том, что сервер перегружен, стабилизировать его, а уже потом исследовать ситуацию на предмет внесения в систему неких серьёзных улучшений.
▍Ограничение скорости обработки запросов
Ограничение скорости обработки запросов позволяет защитить инфраструктуру, ограничивая количество входящих запросов. Это очень важно при падении производительности сервера. По мере того, как растёт время ответа сервера, пользователи имеют свойство агрессивно обновлять страницу, что ещё сильнее повышает нагрузку на сервер.
Хотя отказ от обработки запроса — мера простая и действенная, лучше всего снижать нагрузку на сервер, занимаясь ограничением числа поступающих к нему запросов средствами некоей внешней системы. Это может быть, например, балансировщик нагрузки, обратный прокси-сервер или CDN. Ниже приведены ссылки на инструкции по работе с несколькими системами такого рода:
▍HTTP-кеширование
Поищите способы улучшения кеширования содержимого. Если ресурс может быть отдан пользователю из HTTP-кеша (из кеша браузера или из CDN), тогда его не нужно запрашивать с сервера, что уменьшает нагрузку на сервер.
HTTP-заголовки наподобие Cache-Control, Expires и ETag указывают на то, как должен кешироваться тот или иной ресурс. Аудит и исправление этих заголовков могут помочь улучшить кеширование.
Хотя для кеширования можно прибегнуть к возможностям сервис-воркеров, они используют отдельный кеш. Это — помощь основной системе кеширования браузера, а не её замена. Поэтому при исправлении проблем перегруженного сервера усилия надо сосредоточить на оптимизации HTTP-кеширования.
Диагностика
Запустите Lighthouse и взгляните на показатель Serve static assets with an efficient cache policy для того чтобы увидеть список ресурсов с коротким и средним временем кеширования (Time To Live, TTL). Проанализируйте ресурсы, перечисленные в списке, и рассмотрите возможность увеличения их TTL. Вот ориентировочные сроки кеширования, применимые к различным ресурсам.
Настройка кеширования
Нужно записать в директиву max-age заголовка Cache-Control необходимое время кеширования ресурса, выраженное в секундах. Вот инструкции по настройке этого заголовка в разных системах:
▍Постепенное сокращение возможностей системы
Постепенное сокращение возможностей системы — это стратегия временного ограничения функционала, направленная на снятие с сервера чрезмерной нагрузки. Эта концепция может быть применена множеством различных способов. Например, выдача клиентам статической текстовой страницы вместо полномасштабного приложения, отключение поиска или возврат меньшего, чем обычно, количества результатов поиска. Сюда относится и отключение ресурсоёмких возможностей проектов, не влияющих на их основной функционал. Основное внимание тут должно быть уделено отключению функционала, от которого можно отказаться, не слишком сильно воздействовав на основные возможности приложения.
3. Улучшение системы
▍Использование CDN
Задача по обслуживанию статических ресурсов может быть переложена с сервера на сеть доставки контента (Content Delivery Network, CDN). Это позволит снизить нагрузку на сервер.
Основная функция CDN заключается в быстрой доставке материалов пользователям благодаря использованию большой сети серверов, расположенных поблизости от пользователей. Кроме того, некоторые CDN предлагают дополнительные возможности, связанные с производительностью. Среди них — сжатие данных, балансировка нагрузки, оптимизация медиа-файлов.
Настройка CDN
Преимущества CDN раскрываются в том случае, если компания, владеющая сетью, имеет большую группировку серверов, распределённых по всему миру. Поэтому поддержка собственного CDN-сервиса редко имеет смысл. Обычная настройка CDN — это достаточно быстрая процедура, занимающая около получаса. Она заключается в обновлении DNS-записей таким образом, чтобы они указывали бы на CDN.
Оптимизация использования CDN: исследование ситуации
Для того чтобы идентифицировать ресурсы, которые обслуживаются не с помощью CDN (но должны выдаваться пользователям с CDN), можно воспользоваться WebPageTest. На странице результатов щёлкните по прямоугольнику, подписанному как Effective use of CDN и просмотрите список ресурсов, которые следует обслуживать средствами CDN.

Результаты, выдаваемые WebPageTest
Решение проблем
Если ресурсы не кешируются с помощью CDN, выясните, выполняются ли следующие условия:
▍Масштабирование вычислительных ресурсов
Решение относительно масштабирования вычислительных ресурсов следует принимать с осторожностью. Хотя часто решить некие проблемы можно, прибегнув к масштабированию, сделав это несвоевременно, можно неоправданно усложнить систему и необоснованно повысить затраты на её поддержку.
Диагностика
Высокий показатель, характеризующий время до первого байта (Time To First Byte, TTFB), может быть признаком того, что сервер приближается к пределам своих возможностей. Найти сведения о TTFB можно в разделе Reduce server response times (TTFB) отчёта Lighthouse.
Для более глубокого исследования ситуации нужно воспользоваться каким-нибудь средством мониторинга и проанализировать использование процессора. Если текущее или прогнозируемое значение загрузки процессора превышает 80% — это значит, что нужно задуматься о повышении мощности сервера.
Решение проблем
Добавление в систему балансировщика нагрузки позволяет распределять трафик между множеством серверов. Балансировщик нагрузки находится перед пулом серверов и распределяет трафик на подходящие серверы. Облачные провайдеры предлагают пользователям балансировщики нагрузки (GCP, AWS, Azure), но можно пользоваться и собственным балансировщиком, применив HAProxy или NGINX. После того, как балансировщик нагрузки готов к работе, в систему можно добавлять дополнительные серверы.
В дополнение к балансировке нагрузки большинство облачных провайдеров предлагает услуги по автоматическому масштабированию вычислительных мощностей (GCP, AWS, Azure). Автоматическое масштабирование связано с балансировкой нагрузки. А именно, при автоматическом масштабировании ресурсов в моменты высокой нагрузки производится выделение дополнительных ресурсов, а в периоды низкой — отключение ненужных ресурсов. Но, даже учитывая это, нужно отметить, что автоматическое масштабирование — это тоже не универсальное решение. Для автоматического запуска серверов нужно время. Конфигурации автоматического масштабирования требуют серьёзной настройки. Поэтому до применения сложной системы автоматического масштабирования стоит опробовать сравнительно простую конфигурацию с балансировщиком нагрузки.
▍Использование сжатия данных
Текстовые ресурсы нужно сжимать с использованием алгоритма gzip или brotli. В некоторых случаях сжатие может помочь в сокращении размеров таких ресурсов примерно на 70%.
Диагностика
Для того чтобы найти ресурсы, нуждающиеся в сжатии, можете воспользоваться показателем Enable text compression из отчёта Lighthouse.
Решение проблем
Для включения сжатия нужно отредактировать настройки сервера. Вот подробности об этом:
▍Оптимизация изображений и других медиа-материалов
На изображения приходится основной объём материалов большинства веб-сайтов. Оптимизация изображений может привести к значительному уменьшению размеров материалов сайта. При этом такая оптимизация выполняется достаточно быстро.
Диагностика
В отчёте Lighthouse есть разные показатели, которые указывают на потенциальные возможности по оптимизации изображений. Для поиска крупных изображений, нуждающихся в оптимизации, можно воспользоваться и обычными инструментами разработчика браузера. Такие изображения вполне могут стать хорошими кандидатами на оптимизацию.
Вот список показателей отчёта LightHouse, на которые стоит обратить внимание, исследуя возможность оптимизации изображений:
Решение проблем
Сначала поговорим о том, что стоит предпринять в том случае, если у вас мало времени.
В такой ситуации стоит обратить внимание на большие изображения, и на изображения, которые загружаются чаще других. Обнаружив их, их надо подвергнуть ручной оптимизации, воспользовавшись инструментом наподобие Squoosh. Хорошими кандидатами на оптимизацию обычно являются большие фотографии. Например, взятые с ресурса вроде Hero Images.
Вот на что надо обращать внимание, оптимизируя изображения:
Если изображения составляют значительную долю материалов сайта — рассмотрите возможность использования для их обслуживания специализированного CDN-сервиса, рассчитанного на работу с изображениями. Такие сервисы позволяют снять нагрузку по работе с изображениями с основного сервера. Настройка проекта на использование подобного CDN-сервиса проста, но она требует обновления существующих ссылок на изображения таким образом, чтобы они указывали бы на CDN-ресурсы. Вот материал, посвящённый использованию специализированных CDN-сервисов, рассчитанных на изображения.
▍Минификация JavaScript- и CSS-кода
Минификация кода позволяет уменьшать его размер, удаляя ненужные символы.
Диагностика
Взгляните на показатели Minify CSS и Minify JavaScript отчёта Lighthouse для того чтобы выявить ресурсы, нуждающиеся в минификации.
Решение проблем
Если у вас мало времени — сосредоточьтесь на минификации JavaScript-кода. На большинстве сайтов объём JavaScript-кода превышает объём CSS-кода, поэтому такой ход даст лучшие результаты. Вот материал о минификации JavaScript, а вот — о минификации CSS.
4. Мониторинг сервера
Инструменты для мониторинга серверов поддерживают сбор данных и их визуализацию с использованием панелей управления. Они умеют оповещать пользователей о различных событиях, имеющих отношение к производительности серверов. Использование таких инструментов может помочь в предотвращении и смягчении проблем с производительностью серверов.
Настраивая систему мониторинга, стоит стремиться к как можно большей простоте. Сбор чрезмерного количества данных и слишком частые уведомления способны вызывать негативные эффекты. Чем шире диапазон собираемых данных и чем чаще осуществляется их сбор — тем дороже будет обходиться их сбор и хранение. А если того, кто отвечает за состояние сервера, будут заваливать сообщениями о незначительных событиях, то он, в итоге, будет эти сообщения игнорировать.
В уведомлениях должны содержаться метрики, которые последовательно и точно описывают проблемы. Например, время ответа сервера (latency) — это метрика, которая особенно хорошо для этого подходит: она позволяет выявить большое количество проблемных ситуаций и напрямую связана с тем, как сервер воспринимается пользователями. Уведомления, основанные на низкоуровневых метриках, вроде уровня использования процессора, могут играть роль полезного дополнения, но они способны указать лишь на небольшую часть возможных проблем. Кроме того, уведомления должны быть основаны не на средних показателях, а на показателях, соответствующих 95-99 перцентилям. В противном случае анализ средних значений может легко привести к пропуску проблем, которые не затрагивают всех пользователей.
Настройка мониторинга
Все основные облачные провайдеры предоставляют клиентам собственные инструменты мониторинга (GCP, AWS, Azure). Кроме того, тут можно отметить инструмент Netdata — отличную бесплатную опенсорсную альтернативу инструментам провайдеров. Вне зависимости от того, чем именно вы пользуетесь, вам понадобится установить на каждый сервер, который нужно мониторить, приложение-агент. После завершения настройки системы не забудьте настроить уведомления. Вот инструкции по настройке разных средств мониторинга:
Итоги
Сегодня мы поговорили о том, как выявлять и исправлять проблемы с производительностью серверов. Хочется верить, что ваши серверы будут работать стабильно и вам советы из этого материала не пригодятся. А если что-то пойдёт не так — надеемся, тут вы нашли что-то такое, что поможет вам как можно быстрее справиться с проблемой.
Уважаемые читатели! Что вы делаете в ситуации, когда сервер, на котором работает ваш проект, начинает «тормозить»?
Как понять почему упал сервер не подключая к нему монитор и клавиатуру?
Так бывает что сервер зависает, но к нему не подключена ни клавиатура, ни монитор.
У меня нет лишнего монитора, и обнаружив, что сервер не отвечает по сети,
снимать монитор с моего компьютера и подключать к серверу в кладовке нет никакого желания и сил.
В Linux есть такая возможность ядра как Netconsole.
Netconsole позволяет послать сообщения от ядра на удаленный компьютер.
Для настройки netconsole нужен другой (постоянно включенный) компьютер который примет сообщение по сети.
Проверено на Ubuntu 10.04
На сервере который отлаживаем выполняем:
1. В /etc/modules добавляем netconsole
2. В /etc/modprobe.d/netconsole.conf пишем
options netconsole netconsole=SRCPORT@SRCHOST/eth0,DSTPORT@DSTHOST/DSTMAC
Где SRCPORT и SRCHOST соответственно порт и IP адрес сервера который отлаживаем.
А DSTPORT и DSTHOST порт и IP адрес сервера который будет принимать сообщения.
DSTMAC — это MAC адрес сервера который будет принимать сообщения ЕСЛИ он в той же сети. Если он за роутером или где нибудь в интернете, то нужно указывать MAC адрес ближайшего роутера (Gateway).
Должно получится чтото типа
options netconsole netconsole=6666@192.168.1.2/eth0,6666@192.168.1.3/e0:91:f5:7d:e6:38
На сервере который будет принимать сообщения.
Нам нужно как то запустить программу которая будет слушать UDP порт DSTPORT и куда-либо записывать сообшения.
Самый просто способ — запустить netcat который будет выдавать на экран все что приходит на порт. Для того чтобы после закрытия окна данная программа не прекратила работать, можно запустить ее в screen.
Как понять что все работает?
Можно подождать какого нибудь события, но как убедится что сообщения реально ходят? Можно активировать SysRQ механизм ядра.
echo 1 > /proc/sys/kernel/sysrq
echo h > /proc/sysrq-trigger
После этого на сервере который принимает сообщения в окне с netcat появится текст типа
[ 7849.700372] SysRq : HELP : loglevel(0-9).
Как определить причину падений сервера?
Смотри error логи, если их нет, смотри на какой карте упал сервер, возможно это из за карты.
Какие плагины у тебя отсуствуют? В amxx.cfg пропиши
и потм смотри эти логи
CRASH: Sun Jul 24 01:07:03 MSD 2011
awp_india
CRASH: Sun Jul 24 01:07:03 MSD 2011
awp_india
CRASH: Sat Jul 23 13:41:40 MSD 2011
aim_aztec
CRASH: Fri Jul 22 18:53:22 MSD 2011
de_nuke
CRASH: Fri Jul 22 02:17:09 MSD 2011
de_dust2_2x2
CRASH: Thu Jul 21 02:08:01 MSD 2011
aim_headshot
CRASH: Tue Jul 19 21:51:29 MSD 2011
he_glass2
CRASH: Tue Jul 19 17:44:07 MSD 2011
aim_sk_ak_m4
CRASH: Tue Jul 19 02:47:07 MSD 2011
awp_city2
CRASH: Tue Jul 19 02:18:36 MSD 2011
cs_arabstreets
CRASH: Mon Jul 18 19:00:33 MSD 2011
awp_india
CRASH: Sun Jul 17 18:03:09 MSD 2011
awp_india
CRASH: Fri Jul 15 12:11:15 MSD 2011
awp_india
CRASH: Thu Jul 14 19:46:16 MSD 2011
aim_sk_ak_m4
CRASH: Thu Jul 14 03:29:07 MSD 2011
he_glass2
CRASH: Wed Jul 13 15:00:12 MSD 2011
awp_india
CRASH: Sat Jul 9 19:00:00 MSD 2011
de_dust2_2x2
CRASH: Sat Jul 9 11:31:24 MSD 2011
aim_deagle_map
CRASH: Sat Jul 9 01:25:38 MSD 2011
awp_city2
ЗЫ карта awp_india из ПУ
На счёт карты awp_india это правда из за неё как раз сервер и может упасть кода больше 12×12 игроков
awp_india не стабильна на ней крэшит)
Звонок сисадмина — упал сервер.
Звонит, — приятель сисадмин, в большой компании, — упал сервер, что делать ( и этот человек работает сисадмином ), я говорю за что тебя там держат, если ты за неделю звонишь мне третий раз. Ладно — это лирика… Выяснили сервер не упал, а всего навсего….
Существует несколько хороших утилит, позволяющих искать неисправности в сети на уровне TCP/IP. Большинство из них выдаёт низкоуровневую информацию, поэтому для того чтобы пользоваться ими, нужно хорошо понимать принципы работы протоколов TCP/IP и маршрутизации. Неисправностями в сетях могут служить ошибки в работе таких высокоуровнивых протоколов, как DNS, NFS и HTTP. Вообщем не стоит торопиться и вносить плохо спланированные изменения в неисправную сеть. Прежде чем набрасываться на собственную сеть, необходимо учесть следующее:
Вносить изменения пошагово, тщательно проверять результаты, чтобы убедиться в совпадении полученного эффекта с ожидаемым. Изменения не давшие нужного результата, должны отменяться.
Документировать возникшую ситуацию и все внесённые изменения.
Начинать с края сети и идти по ключевым ее компонентам, пока не будет найден источник неисправности.
Не забывайте человеческий фактор, — что собрано человеком, им же и может быть разрушено.
Итак:
Есть ли физическое соединение?
Правильно ли сконфигурированы сетевые интерфейсы?
Правильно ли работает ( настроена ) служба DNS?
Отображаются ли в таблице маршрутизации адреса других компьютеров?
Пингуется ли локальный компьютер ( 127.0.0.1 ) ping localhost?
Пингуется ли локальная сеть по IP-адресам?
Пингуется ли локалка по именам?
Пингуется ли внешняя сеть, например ping helpset.ru?
После определения на каком уровне возникает проблема, внимательно подумав, не изменит ли работу сети внесенные вами изменения, можно приступать к лечению.
Обмен пакетами с helpset.ru [212.76.128.227] по 32 байт:
Ответ от 212.76.128.227: число байт=32 время=4мс TTL=56
Ответ от 212.76.128.227: число байт=32 время=5мс TTL=56
Ответ от 212.76.128.227: число байт=32 время=5мс TTL=56
Ответ от 212.76.128.227: число байт=32 время=4мс TTL=56
Статистика Ping для 212.76.128.227:
Пакетов: отправлено = 4, получено = 4, потеряно = 0 (0% потерь),
Приблизительное время приема-передачи в мс:
Минимальное = 3мсек, Максимальное = 4 мсек, Среднее = 3 мсек
Команда TRACEROUT показывает последовательность шлюзов, через которые проходит IP-пакет на пути к пункту назначения. Если где-то затык значит что-то не так. А вобще tracert /?.
Программы TCPDUMP, ETHEREAL — анализаторы пакетов ( Ehtereal — визуальный анализатор пакетов ), они могут следить за трафиком в сети и регистрировать, либо выводить, на экран пакеты, удовлетворяющие заданным критериям. Можно перехватывать пакеты пересылаемые на определённый сервер или с него, а также TCP-пакеты, относящиеся к конкретному сетевому соединению. Пример запуска утилиты tcpdump запущенной на сервере helpset.ru
tcpdump host helpset
Общая стратегия поиска неисправностей тут же принесла свои плоды:
…и этот человек работает сисадмином ), я говорю за что тебя там держат, если ты за неделю звонишь мне третий раз. Ладно — это лирика…
Выяснили сервер не упал, а всего навсего не пингует внешнюю сеть. Внутренняя пингуется.
Вопрос шнурок вставлен, «… за кого ты меня принимаешь? — Сейчас проверю…»



