Процесс компиляции программ на C++
Цель данной статьи:
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
Состав компилятора g++
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
driver.cpp:
1) Препроцессинг
Самая первая стадия компиляции программы.
Препроцессор — это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит происходит работа с препроцессорными директивами. Например, препроцессор добавляет хэдеры в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
Хэдеры, включенные в программу с помощью директивы #include, рекурсивно проходят стадию препроцессинга и включаются в выпускаемый файл. Однако, каждый хэдер может быть открыт во время препроцессинга несколько раз, поэтому, обычно, используются специальные препроцессорные директивы, предохраняющие от циклической зависимости.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
Взглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
Мы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
Но на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Этапы компиляции
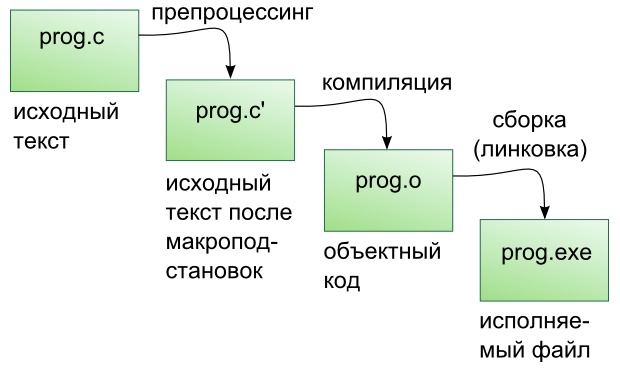
Компиляция исходных текстов на Си в исполняемый файл происходит в три этапа.
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
Компиляция
Процесс компиляции состоит из следующих этапов:
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
При отладочной сборке возможно сохранение большого количества символьной информации (идентификаторов переменных, функций, а также типов).
Компоновка
Также называется связывание, сборка или линковка.
При этом возможны ошибки связывания.
Если, допустим, функция была объявлена, но не определена, ошибка обнаружится только на этом этапе.
Особенность подключения пользовательских библиотек в Си
Подключение пользовательской библиотеки в Си на самом деле не так просто, как кажется.
Рассмотрим пример: есть желание вынести часть кода в отдельный файл — пользовательскую библиотеку.
program.c
#include «mylib.h»
const int MAX_DIVISORS_NUMBER = 10000;
int main()
<
int number = read_number();
int Divisor[MAX_DIVISORS_NUMBER];
size_t Divisor_top = 0;
factorize(number, Divisor, &Divisor_top);
print_array(Divisor, Divisor_top);
return 0;
>
Сама библиотека должна состоять из двух файлов: mylib.h и mylib.c.
mylib.h
#ifndef MY_LIBRARY_H_INCLUDED
#define MY_LIBRARY_H_INCLUDED
//считываем число
int read_number();
//получаем простые делители числа
// сохраняем их в массив, чей адрес нам передан
void factorize(int number, int *Divisor, int *Divisor_top);
//выводим число
void print_number(int number);
//распечатывает массив размера A_size в одной строке через TAB
void print_array(int A[], size_t A_size);
mylib.c
//считываем число
int read_number()
<
int number;
scanf(«%d», &number);
return number;
>
//получаем простые делители числа
// сохраняем их в массив, чей адрес нам передан
void factorize(int x, int *Divisor, int *Divisor_top)
<
for (int d = 2; d = 0; i—)
<
printf(«%d\t», A[i]);
>
printf(«\n»);
>
Препроцессор Си, встречая #include «mylib.h», полностью копирует содержимое указанного файла (как текст) в место вызова директивы. Благодаря этому на этапе компиляции не возникает ошибок типа Unknown identifier при использовании функций из библиотеки.
Файл mylib.c компилируется отдельно.
А на этапе компоновки полученный файл mylib.o должен быть включен в исполняемый файл program.exe.
Cреда разработки обычно скрывает весь этот процесс от программиста, но для корректного анализа ошибок сборки важно представлять себе как это делается.
Что делается при компиляции
Синтаксис команды компиляции имеет вид:
компилятор [опции] файлы [библиотеки]
В квадратных скобках указываются необязательные компоненты команды.
На UNIX-подобных системах имеется множество компиляторов. Большая часть из них является коммерческими продуктами. Для систем Linux пакет GCC является неотъемлемой частью дистрибутивов, поскольку является базовым компилятором сборки ядра системы и всех ее утилит.
Пакет компиляторов GCC
В него входят компиляторы:
Помимо этого, на Linux кластерах, являющихся сегодня основным видом высокопроизводительных вычислительных систем, широко используется пакет компиляторов Intel Compiler, наилучшим образом оптимизированный под платформу x86-64, являющуюся основной при построении вычислительных кластеров. Это коммерческй продукты и он приобретен Вычислительным центром СПбГУ.
Пакет компиляторов Intel
Рассмотрим подробнее работу с компилятором gcc.
Создадим файл с именем ex1.c с помощью команды touch. Откроем его в текстовом редакторе и наберем текст программы на языке С.
Далее следует скомпилировать программу, т.е. перевести в исполнимый код. Для этого выполним следующую команду.
Если программа написана без ошибок, то никакой выдачи информации на терминал не будет, а в рабочем каталоге появится файл с именем a.out. Это исполнимый файл, полученный в результате компиляции программы. Его можно запустить на исполнение(поэтому файлы и называются исполнимыми), набрав в командной строке:
На терминал будет напечатана строка «Hello word».
Для того чтобы поменять имя создаваемого файла c a.out на любое другое необходимо использовать опцию -o:
В результате будет создан исполнимый файл с именем ex1.
Приведем несколько важных опций компилятора gcc (они справедливы и для icc)
Рассмотрим назначение опций более подробно на примерах.
В программах часто используются уже написанные ранее функции. Например, в приведенной выше программе, применялась системная функция вывода информации в стандартный поток printf. Для того чтобы транслятор на этапе создания программы, мог правильно обработать внешнюю функцию необходимо ее предварительно описать, либо внутри программы, либо в специальном заголовочном файле. Такие файлы еще называют include файлами, в языке С они подключаются с помощью специальной директивы #include. На первом этапе трансляции программы, запускается так называемый препроцессор, он находит файл с именем stdio.h, и вставляет его содержимое внутрь программы. Пути поиска задаются с помощью опции
Если используется стандартный заголовочный файл, то опцию -I для его поиска в командной строке компиляции программы указывать необязательно. Существует специальный каталог, где располагаются стандартные заголовочные файлы. Препроцессор автоматически просматривает его при поиске заголовочных файлов. Все сказанное в полной мере относится и к компилятору с языка Фортран. Отличие состоит в синтаксисе подключения include файла:
В рассмотренном примере используется функция printf, находящаяся в стандартной библиотеке с именем libc. Для программ на языке С эта библиотека автоматически подключается к любой программе, поэтому не потребовалось подключать ее с помощью опций. В тех случаях, когда в программе используются функции входящие в другие библиотеки, то эти библиотеки необходимо указывать компоновщику, иначе компоновщик не сможет собрать исполнимый файл. Рассмотрим следующий пример.
Попробуем скомпилировать программу командой:
В результате получим следующие сообщение об ошибке:
/tmp/ccgSk9AB.o(.text+0x49): In function `main’:
ex2.c: undefined reference to `pow’
collect2: ld returned 1 exit status
Это сообщение говорит, что в функции main, файла ex2.c вызывается функция pow, для которой не найден машинный код на этапе сборки программы. Для того чтобы программа скомпоновалась, необходимо указать компилятору в какой библиотеке следует искать объектный код функции pow. Правильная строка компиляции будет выглядеть следующим образом.
В результате будет создана программа с именем ex2, которая при запуске напечатает:
Подключение библиотеки было выполнено с помощью опции -lm. Файл этой библиотеки находится в каталоге /usr/lib. Полное его название libm, имена файлов библиотек подпрограмм всегда начинаются с префикса lib, за которым идет название библиотеки. При подключении библиотеки к программе в строке компилятора префикс lib заменяется на -l. Таким образом, подключение библиотеки libm осуществляется опцией -lm. Поскольку библиотека стандартная, находится в специальном каталоге, то нет необходимости указывать путь поиска файла библиотеки математических подпрограмм с помощью опции -L. Компилятор сам найдет его в директории /usr/lib. Работа с библиотеками имеет ряд аспектов, которые нуждаются в более подробном рассмотрении.
Динамические библиотеки, называемые также библиотеками общего пользования или разделяемыми библиотеками (shared library), загружаются на этапе выполнения программы. Код вызываемых функций не встраивается внутрь исполняемой программы, а вызывается по мере необходимости при запуске программы на исполнение. Такой подход позволяет создавать программы значительно меньшего объема. Динамические библиотеки хранятся обычно в определенном месте и имеют стандартное расширение. В ОС Windows файлы библиотек общего пользования имеют расширение .dll, а в UNIX-подобных системах .so. Если на этапе загрузки программы система не смогла найти необходимый код, то программа не запустится. Будет выдано сообщение об ошибке:
error while loading shared libraries: libxxx.so: cannot open shared object file: No such file or directory
Статические библиотеки в виде пакетов объектных файлов, присоединяются (линкуются) к исполнимой программе на этапе компиляции (в Windows такие файлы имеют расширение .lib, а в UNIX-подобных .a). В результате этого программа включает в себя все необходимы функции, что делает её автономной, хорошо переносимой, но увеличивает размер.
Статическая библиотека создается специальной командой:
ar rc libимя.a список_объектных_файлов
Объектные файлы создаются компиляцией функций с опцией -c. Рекомендуется каждую функцию (или подпрограмму в Фортране) оформлять в отдельном файле.
Динамическая библиотека создаются компилятором:
Для создания исполнимого файла со статической библиотекой потребуется команда:
Мы создали две версии программы: с использованием динамической и статической библиотек. Во втором случае использовалась опция -static, чтобы компилятор использовал статическую библиотеку libmy.a. Если бы динамической версии библиотеки не было, то эту опцию можно было бы не указывать. Компилятор, не найдя динамической библиотеки автоматически подключает статическую библиотеку. Опция -I
/lib указывает компилятору, что при сборке программы, помимо стандартных путей, следует искать библиотеки и в директории lib домашнего каталога пользователя.
При запуске на исполнение разные версии программы, скорее всего, поведут себя по-разному:
Дело в том, что в момент загрузки программы, система ищет необходимые для запуска программы разделяемые библиотеки, чтобы собрать исполнимую программу. Поиск идет по заранее установленному списку директорий. Имена директорий перечислены в системном файле /etc/ld.so.conf. Очевидно, что в этот файл невозможно занести все индивидуальные каталоги пользователей. В этой ситуации на помощь приходят переменные окружения. Как уже говорилось ранее, в UNIX системах существует специальная переменная LD_LIBRARY_PATH, в которой каждый пользователь может перечислить директории для поиска разделяемых библиотек. Добавим к переменной LD_LIBRARY_PATH путь к директории lib, где находится библиотека libmy.so. Делается это командой
Данной командой мы к ранее установленному значению добавили путь к персональному каталогу пользователя с библиотечными файлами. Если теперь запустить программу
./prog_shared
то она сработает корректно.
При использовании большого количества библиотек и include файлов команда компиляции может оказаться довольно длинной. Чтобы упростить компиляцию, часто используют командные файлы (скрипты), выступающих в качестве интерфейсов к стандартным компиляторам. Такой подход используется в пакете MPI. При сборке библиотек формируются командные файлы для вызова тех или иных компиляторов. Компиляция параллельных MPI-программ выполняется командами:
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Компилятор
Содержание
Виды компиляторов
Виды компиляции
Структура компилятора
Процесс компиляции состоит из следующих этапов:
В конкретных реализациях компиляторов эти этапы могут быть разделены или, наоборот, совмещены в том или ином виде.
Генерация кода
Генерация машинного кода
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Результат компиляции — исполнимый модуль — обладает максимальной возможной производительностью, однако привязан к определённой операционной системе и процессору (и не будет работать на других).
Для каждой целевой машины (IBM, Apple, Sun и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС генерировать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут оптимизировать код под разные модели из одного семейства процессоров (путём поддержки специфичных для этих моделей особенностей или расширений наборов инструкций). Например, код, скомпилированный под процессоры семейства Pentium, может учитывать особенности распараллеливания инструкций и использовать их специфичные расширения — MMX, SSE и т. п.
Некоторые компиляторы переводят программу с языка высокого уровня не прямо в машинный код, а на язык ассемблера (примером может служить PureBasic, транслирующий бейсик-код в ассемблер FASM). Это делается для упрощения части компилятора, отвечающей за кодогенерацию, и повышения его переносимости (задача окончательной генерации кода и привязки его к требуемой целевой платформе перекладывается на ассемблер), либо для возможности контроля и исправления результата компиляции программистом.
Генерация байт-кода
Некоторые реализации интерпретируемых языков высокого уровня (например, Perl) используют байт-код для оптимизации исполнения: затратные этапы синтаксического анализа и преобразование текста программы в байт-код выполняются один раз при загрузке, затем соответствующий код может многократно использоваться без промежуточных этапов.
Динамическая компиляция
Из-за необходимости интерпретации байт-код выполняется значительно медленнее машинного кода сравнимой функциональности, однако он более переносим (не зависит от операционной системы и модели процессора). Чтобы ускорить выполнение байт-кода, используется динамическая компиляция, когда виртуальная машина транслирует псевдокод в машинный код непосредственно перед его первым исполнением (и при повторных обращениях к коду исполняется уже скомпилированный вариант).
Декомпиляция
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а такие программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Adobe Flash. Разновидностью декомпилирования является дизассемблирование машинного кода в код на языке ассемблера, который почти всегда выполняется успешно (при этом сложность может представлять самомодифицирующийся код или код, в котором собственно код и данные не разделены). Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически взаимно-однозначное соответствие.
Раздельная компиляция
Раздельная компиляция (англ. separate compilation ) — трансляция частей программы по отдельности с последующим объединением их компоновщиком в единый загрузочный модуль.
Исторически особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он производил как трансляцию, так и компоновку, при этом компилятор мог порождать сразу машинный код. Однако позже, с ростом сложности и размера программ (и увеличением времени, затрачиваемого на перекомпиляцию), возникла необходимость разделять программы на части и выделять библиотеки, которые можно компилировать независимо друг от друга. При трансляции каждой части программы компилятор порождает объектный модуль, содержащий дополнительную информацию, которая потом, при компоновке частей в исполнимый модуль, используется для связывания и разрешения ссылок между частями.
Появление раздельной компиляции и выделение компоновки как отдельной стадии произошло значительно позже создания компиляторов. В связи с этим вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами» [6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
KNZSOFT Разработка ПО, консультации, учебные материалы
Князев Алексей Александрович. Независимый программист и консультант.
С++ для начинающих. Урок 1. Компиляция
Обзор компиляторов
Существует множество компиляторов с языка C++, которые можно использовать для создания исполняемого кода под разные платформы. Проекты компиляторов можно классифицировать по следующим критериям.
Если на использование коммерческих компиляторов нет особых причин, то имеет смысл использовать компилятор с языка C++ из GNU коллекции компиляторов (GNU Compiler Collection). Этот компилятор есть в любом дистрибутиве Linux, и, он, также, доступен для платформы Windows как часть проекта MinGW (Minumum GNU for Windows). Для работы с компилятором удобнее всего использовать какой-нибудь дистрибутив Linux, но если вы твердо решили учиться программировать под Windows, то удобнее всего будет установить некоммерческую версию среды разработки QtCreator вместе с QtSDK ориентированную на MinGW. Обычно, на сайте производителя Qt можно найти инсталлятор под Windows, который сразу включает в себя среду разработки QtCreator и QtSDK. Следует только быть внимательным и выбрать ту версию, которая ориентирована на MinGW. Мы, возможно, за исключением особо оговариваемых случаев, будем использовать компилятор из дистрибутива Linux.
GNU коллекция компиляторов включает в себя несколько языков. Из них, группу языков Си составляет три компилятора.
Этапы компиляции
Процесс обработки текстовых файлов с кодом на языке C++, который упрощенно называют «компиляцией», на самом деле, состоит из четырех этапов.
Рассмотрим подробнее упомянутые выше стадии обработки текстовых файлов на языке C++.
Препроцессинг
Препроцессинг, это процедура ставшая традиционной для многих обработчиков разного рода описаний, в том числе и текстов с кодами программ. В общем случае, везде, где возникает необходимость в предварительной обработке текстов реализуется некоторый язык препроцессинга элементы которого ищутся препроцессором при обработке файла.
Основными элементами языка препроцессора являются директивы и макросимволы. Директивы вводятся с помощью символа «решетка» (#) в начале строки. Все, что следует за символом решетки и до конца строки считается директивой препроцессора. Директива препроцессора define вводит специальные макросимволы, которые могут быть использованы в следующих выражениях языка препроцессора.
На входе препроцессора мы имеем исходный файл с текстом на языке C++ включающим в себя элементы языка препроцессора.
На выходе препроцессора получаются так называемые компиляционные листы, состоящие исключительно из выражений языка C++, которых должно быть достаточно для создания объектных файлов на следующих этапах обработки. Последнее означает, что на момент использования каких-либо символов языка из других файлов, объявления этих символов должны присутствовать в компиляционном листе выше. Именно такие подстановки и призван осуществлять препроцессор. Часто, на вход препроцессора поступает файл размером в несколько десятков строк, а на выходе получается компиляционный лист из десятков тысяч строк.
Ассемблирование
Процесс ассемблирования с одной стороны достаточно прост для понимания и с другой стороны является наиболее сложным в реализации. По своей сути это процесс трансляции выражений одного языка в другой. Более конкретно, в данном случае, мы имеем на входе утилиты ассемблера файл с текстом на языке C++ (компиляционный лист), а на выходе мы получаем файл с текстом на языке Ассемблера. Язык Ассемблера это низкоуровневый язык который практически напрямую отображается на коды инструкций процессора целевой системы. Отличие только в том, что вместо числовых кодов инструкций используется англоязычная мнемоника и кроме непосредственно кодов инструкций присутствуют еще директивы описания сегментов и низкоуровневых данных, описываемых в терминологии байтов.
Ассемблирование не является обязательным процессом обработки файлов на языке C++. В данном случае, мы наблюдаем лишь общий подход в архитектуре проекта коллекции компиляторов GNU. Чтобы максимально объеденить разные языки в одну коллекцию, для каждого из языков реализуется свой транслятор на язык ассемблера и, при необходимости, препроцессор, а компилятор с языка ассемблера и линковщик делаются общими для всех языков коллекции.
Компиляция
В данном случае, мы имеем компилятор с языка ассемблера. Результатом его работы является объектный файл полученный на основе всего того текста, что был предоставлен в компиляционном листе. Поэтому можно говорить, что каждый объектный файл проекта соответствует одному компиляционному листу проекта.
Объектный файл — это бинарный файл, фактически состоящий из набора функций. Однако в исходном компиляционном листе не все вызываемые функции имели реализацию (или определение — definition). Не путайте с объявлением (declaration). Чтобы компиляционный лист можно было скомпилировать, необходимо, чтобы объявления всех вызываемых функций присутствовали в компиляционном листе до момента их использования. Однако, объявление, это не более чем имя функции и параметры ее вызова, которые позволяют во время компиляции правильно сформировать стек (передать переменные для вызова функции) и отметить, что тут надо вызвать функцию с указанным именем, адрес реализации которой пока не известен. Таким образом, объектные файлы сплошь состоят из таких «дыр» в которые надо прописать адреса из функций, которые реализованы в других объектных файлах или даже во внешних библиотеках.
Вообще, между объявлением (declaration) и определением (definition) состоит в том, что объявление (declaration) говорит об имени сущности и описывает ее внешний вид — например, тип объекта или параметры функции, в то время как определение (definition) описывает внутреннее устройство сущности: класс памяти и начальное значение объекта, тело функции и пр.
Исходя из этих определений, в компиляционном листе перед компиляцией должны существовать все объявления (declaration) всех тех сущностей, что используются в этом компиляционном листе. Причем их объявления должны находится до момента использования этих сущностей. Иначе, компилятор не сможет подготовить обращение к соответствующей сущности. Например, не сможет оформить передачу параметров через стек вызова функции и подготовиться к приему возвращаемого функцией значения.
Линковка
На этапе линковки выполняется объединение всех объектных файлов проекта, откомпилированных по соответствующим компиляционным листам проекта в единую сущность. Это может быть приложение, статическая или динамическая библиотека. Разница в бинарных заголовках целевых файлов и несколько различной внутренней организацией. Первичной задачей линковки следует назвать задачу по подстановке адресов вызова внешних объектов, которые были образованы в объектных файлах проекта. Соответствующие реализации сущностей с адресами их размещения должны находится в видимости линковщика. Эти сущности должны быть либо в объектных файлах, тогда они должны быть указаны в списке линковки, либо во внешних библиотеках функций, статических или динамических, тогда они должны быть указаны в списке внешних библиотек.
Средства сборки проекта
Традиционно, программа на языке C++ собирается средствами утилиты make исполняющей сценарий из файла Makefile. Сценарий сборки можно писать самостоятельно,
а можно создавать его автоматически с помощью всевозможных средств организации проекта. Среди наиболее известных средств организации проекта можно указать следующие.
Современные версии QtCreator могут работать с проектами, которые используют как систему сборки QMake, так и систему сборки CMake.
Простой пример компиляции
Рассмотрим простейший проект «Hello world» на языке C++. Для его компиляции мы будет использовать консоль, в которой будем писать прямые команды компиляции. Это позволит нам максимально прочувствовать описанные выше этапы компиляции. Создадим файл с именем main.cpp и поместим в него следующий текст программы.
В представленом примере выполнена нумерация строк, чтобы упростить пояснения по коду. В реальном коде нумерации не должно быть, так как она не входит в синтаксическое описание конструкций языка C++.
В первой строке кода записана директива включения файла с именем iostream в текст проекта. Как уже говорилось, все строки, которые начинаются со знака решетки (#) интерпретируются в языках C/C++ как директивы препроцессора. В данном случае, препроцессор, обнаружив директиву включения файла в текст программы, директиву include, выполнит включение всех строк указанного в директиве файла в то место программы, где стоит инструкция include. В результате этого у нас получится большой компиляционный лист, в котором будут присутствовать множество символов объявленных (declaration) в указанном файле. Включаемые файлы, содержащие объявления (declaration) называют заголовочными файлами. На языке жаргона можно услышать термины «header-файлы» или «хидеры».
В третьей строке программы описана функция main(). В контексте операционной системы, каждое приложение должно иметь точку входа. Такой точкой входа в операционных системах *nix является функция main(). Именно с нее начинается исполнение приложения после его загрузки в память вычислительной системы. Так как операционная система Windows имеет корни тесно переплетенные с историей *nix, и, фактически, является далеким проприентарным клоном *nix, то и для нее справедливо данное правило. Поэтому, если вы пишете приложение, то начинается оно всегда с функции main().
При вызове функции main(), операционная система передает в нее два параметра. Первый параметр — это количество параметров запуска приложения, а второй — строковый массив этих параметров. В нашем случае, мы их не используем.
В пятой строке мы обращаемся к предопределенному объекту cout из пространства имен std, который связан с потоком вывода приложения. Используя синтаксис операций, определенных для указанного объекта, мы передаем в него строку «Hello world» и символ возврата каретки и переноса строки.
В седьмой строке мы возвращаем код 0, как код возврата функции main(). В организации процессов в операционной системы, это число будет восприниматься как код возврата приложения.
Выполнив остановку компиляции после этапа ассемблирование, возможно будет интересно выполнить остановку компиляции и после этапа, который собственно, и выполняет компиляцию, т.е. превращение ассемблерного кода в объектный файл, который впоследствии надо будет слинковать с библиотеками, в которых будет найдено реализация объекта cout, который используется в нашей программе как некий библиотечный объект.
Наконец, если нас не интересуют эксперименты с остановками компиляции на разных этапах и если мы просто хотим получить из нашего файла на языке C++ исполняемую программу, то следует выполнить следующую команду.
В результате исполнения этой команды появится файл a.out который и представляет собой результат компиляции — исполняемый файл программы. Запустим его и посмотрим на результат выполнения. При работе в операционной системе Windows, результатом компиляции будет файл с расширением exe. Возможно, он будет называться main.exe.
Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.



