Разработчик БД (баз данных)

Разработчик баз данных — это специалист, который занимается созданием баз данных, их отладкой, модернизацией, обслуживанием. Кстати, в 2021 году центр профориентации ПрофГид разработал точный тест на профориентацию. Он сам расскажет вам, какие профессии вам подходят, даст заключение о вашем типе личности и интеллекте.

Краткое описание
Серверные базы данных хранят множество важной информации, поэтому без них не может работать ни одна компания. Часто представители малого и среднего бизнеса обращаются к техническим разработчикам, которые умеют спроектировать базу данных, создать ее и обеспечить бесперебойную работу.
Представители этой профессии также сопровождают созданную серверную базу, занимаясь ее обслуживанием и модернизацией. Для работы в этой сфере необходимо высшее техническое образование, а также обязательно знание языка запросов SQL, без которого работать в этой сфере невозможно.
Особенности профессии
Специалисты, которые решили связать свою жизнь с этой профессией, выполняют следующие работы:
У этих специалистов могут заказывать модернизацию и последующее сопровождение уже имеющейся базы данных, чтобы повысить ее производительность и безопасность. На плечи этого сотрудника, если в штате компании нет системного администратора, может лечь работа с коллективом, во время которой он будет проводить консультации, обучение, принимать жалобы.
Стоит помнить, что работа с данными — это огромная ответственность, если сбой в системе или ошибка разработчика станет причиной потери информации, то владелец данных может понести колоссальные убытки. Представители этой профессии должны великолепно знать свою работу, уметь быстро устранять ошибки и нести ответственность в случае, если данные будут утеряны.
Плюсы и минусы профессии
Плюсы
Минусы

Важные личные качества
Разработчик баз данных должен отличаться высокой ответственностью, техническим складом ума, а также следующими важными качествами:
Специалист должен уметь контролировать свою работу, ведь каждая его ошибка ударит рублем по карману заказчика!
Обучение на разработчика базы данных
Эту техническую профессию абитуриенты могут освоить в высших учебных заведениях, на курсах при вузах или в частных школах. Для поступления абитуриент должен сдать такие предметы во время ЕГЭ:
Набор экзаменов может изменяться, что зависит от выбранного направления подготовки и вуза, в который абитуриент подает документы. Если вы решили осваивать профессию на курсах, то достаточно заполнить заявку, внести оплату и ожидать письмо-подтверждение с расписанием занятий.
Курсы
Центр «Специалист» при МГТУ им. Н. Э. Баумана
Эти курсы выпускают лучших специалистов в РФ, славясь высоким качеством обучения и множеством направлений подготовки. И здесь разработчики баз данных и люди, желающие узнать об этой профессии больше, смогут пройти курсы для повышения квалификации. Обучаться можно как очно, так и в режиме онлайн, выбирая удобный график!
Киевский учебный центр «Курсор»
Студенты этого учебного центра смогут получить знания о базах данных, математических моделях, языке запросов SQL. Программа курсов будет интересна для опытных специалистов и новичков, которые только начинают осваивать эту профессию.
«БД-шник любит структурировать и находить взаимосвязи»
Мы продолжаем цикл публикаций про ИТ-профессии. В этот раз мы поговорили с Марией, ведущим разработчиком баз данных в IBS. Она рассказала о том, кто такие БД-шники и почему выбрала именно это направление разработки; какими качествами должен обладать хороший специалист и как осваивать базы данных с нуля; а также о том, какие профессии могут быть лучше профессии программиста.
Разработчик баз данных — это специалист, который занимается их созданием, их отладкой, модернизацией, обслуживанием.
— Кто такой разработчик баз данных?
— Это человек, который любит все структурировать и находить взаимосвязи. Часто разработчиков баз данных называют data scientist. Но это просто модное слово, чаще нас называют БД-шниками.
Пользователю работа БД-шников обычно незаметна. Если мы посмотрим на приложение как на домик, то база данных будет составлять фундамент. Люди видят фасад — то есть фронт, само приложение. Хотя от того, как правильно будет построен «фундамент», насколько быстро будут организованы в нем процессы, многое зависит.
— В какой момент у ребят, которые обучаются в университете, появляется разработка баз данных как направление?
— Она появляется далеко не у всех. В университетах обычно учат все-таки объектно-ориентированному программированию. А базы идут, по-моему, у нас только на физфаке и мехмате на младших курсах, и то как факультативный предмет.
— А как ты тогда пришла к базам данных?
— Моя мама работала физиком-теоретиком в институте механики сплошных сред. Когда я была в 11 классе, посмотрела, с чем она работает, тогда это были Interbase и Visual FoxPro. Взяла ее книжки, мне стало интересно. Познакомилась с FreeBSD, с *Nix системами. Сначала это было хобби, параллельное основной работе, а потом занялась базами данных всерьез.
— Чем конкретно занимаются разработчики баз данных? Корректно ли будет сказать, что они пишут код?
— Да, мы пишем код. Причем у каждой СУБД есть свои диалекты.
Среди БД-шников есть несколько основных направлений. Первое, самое простое, непосредственно написание кода. Это обычно разработка с нуля, иногда переписывание существующих процедур, функций и так далее.
Второе более сложное, здесь берут существующую, запущенную в пром (промышленная эксплуатация) систему и ищут в ней слабые места. Затем переписывают код так, чтобы не сломался функционал и все работало быстро.
Третье направление — это DBA, администраторы и архитекторы баз данных. Они занимаются проектированием, настройкой и самих СУБД, и железа под них.
Я работаю во всех трех направлениях.
— И как это соотносится с backend, frontend и full stack разработкой?
— Это глубокий backend, база, основа. Потом идет backend, затем — frontend. Так из трех звеньев выстраивается домик. Бывает full stack разработка, когда специалист умеет писать все понемножку. Но база этого не прощает. И часто процессы после full stack разработки приходится переписывать. Потому что у специалистов разное мышление и разное отношение, как я понимаю.
— Три качества, которыми должен обладать хороший специалист.
— Назову четыре. Любопытство. Некоторая нудность. Желание видеть во всем закономерности и логику. И стремление выстраивать процессы. То есть ты видишь данные и должен научиться видеть в них логику.
— Можешь назвать преимущества своего направления?
— Это всегда что-то новое, если мы не говорим, конечно, про сопровождение, но и у него есть свои поклонники. В оптимизации ты погружаешься в абсолютно новый незнакомый проект. Тебе надо быстро все пройти, перелопатить огромный пласт. Вытащить зависимости и поправить их так, чтобы у бэка и у фронта ничего не поломалось, а все цифры остались теми же.
Второе преимущество: рука об руку с базами данных идет машинное обучение и data science. А если у тебя есть еще и R или Python, то можно делать клевые проекты — пусть даже для себя. Хороших БД-шников мало.
— Все сейчас в основном изучают объектно-ориентированное программирование. Кроме того, высокоуровневый БД-шник не нужен маленьким конторам — у них нет таких задач. Особенно если ты занимаешься, например, хранилищами данных. Так что умение работать с базами данных это и плюс и минус одновременно. Найти работу БД-шнику сложнее.
— Почему PostgreSQL набирает такую популярность?
— Postgres Pro Enterprise — это отечественный продукт. А Oracle, MySQL, MSSQL — иностранные, за ними стоят крупные корпорации. Поэтому сейчас, в рамках политики импортозамещения, стараются от них уйти. Ведь случись что и Oracle скажет: «Я с вами больше не работаю», бизнес сильно пострадает.
— Чем ты занимаешься на работе?
— Сейчас выполняю несколько ролей. Во-первых, я — технический архитектор на проекте. Во-вторых, разработчик БД. Занимаюсь переносом кода и архитектуры в приложение.
— Как вообще проходит твой день рабочий? Насколько плотно ты занята?
— Все зависит от музы. Муза пришла — я работаю. А если серьезно, обычно сажусь, включаю музыку и погружаюсь в работу. Но стараюсь делать перерывы и на обед, и кофе выпить. Если есть интересная задача, я ее и ночью думаю, в фоновом процессе. Решение оформляется, и я его воплощаю в жизнь.
— А какой стек технологий ты сейчас используешь?
— Сейчас у меня Postgres Pro Enterprise 10.3 и OpenJDK.
— Как ты считаешь, программиста круче других профессий? Или ты выделяешь какие-то другие, более интересные сферы?
— По-моему, самая клевая — это нейрохирург или, например, пилот самолета. А программиста — это просто клевая профессия. По образованию я инженер систем навигации. Пилотировать или быть диспетчером — тоже круто, потому что эти люди порой спасают много жизней.
— Без каких знаний разработчикам баз данных не обойтись?
— Смотря на каком уровне они хотят работать. Если просто с хорошими постановками писать код или выполнять рутинную работу, то необходимо только знание баз данных и SQL. Если человек хочет углубиться, то нужна и математика, и статистика, и другие знания, например администрирование никсовых систем.
— А где эти знания можно получить?
— Искать самому в интернете, ездить на конференции, спрашивать на форумах, читать книжки.
— Как часто бываешь на профессиональных мероприятиях: конференциях, форумах? На какие реально стоит ходить?
— Нужно ходить на конференции, где люди и комьюнити делятся знаниями. Из стоящих назову PgConf.Russia. Бывают постгресовые конференции, туда приезжают разработчики самого продукта. Они делятся опытом, своими наработками, которые еще не включены в общий пул. Недавно была на такой в Москве.
— А как ты повышаешь свою квалификацию?
— Читаю различные форумы. Например, SQL.Ru. И у меня нет ни одного сертификата, каюсь. Но сертификат не всегда гарантирует знание. Если уж получать его, то нужно как следует готовиться к сдаче не только для того, чтобы получить бумажку, а научиться. Например, если сравнивать с собаками, то общий курс дрессировки можно сдать, чтобы получить бумажечку. А можно подготовиться так, чтобы с собакой было комфортно жить в городе.
— Что можешь посоветовать тем, кто хочет стать разработчиками баз данных?
— В первую очередь определиться с диалектом, на котором хочешь работать, затем с любопытными тебе задачами. Подумать, что интереснее — нахрапом брать большие пласты или аккуратненько и ювелирно работать в сопровождении систем. И заниматься, читать. Начать с общих положений SQL и затем уже углубляться в нужный диалект и особенности выбранной СУБД. Есть курсы, например на udemy.com, или книги, которые есть в свободном доступе. Лучше начинать не просто с теоретической части, а взять себе задачу, самому придумать рабочий проект и постараться реализовать его.
— Расскажи про свои хобби.
— По выходным люблю немного мучить детей математикой, английским, французским, физикой. Учусь общаться с детьми и считаю, что это полезно. В основном стараюсь брать тех, кто учится параллельно в российских и английских частных школах, по двум программам. Ребята в большинстве своем живут и учатся в Лондоне, а в Пермь приезжают на контрольные, когда надо сделать интенсив.
— У меня есть собачка, и я занимаюсь с ней кинологическим спортом. И кошка сиамо-ориентальная, Сиаори.
— Распределенная команда или все в одном офисе?
— Это зависит от команды. Я и с теми работала, и с другими. И то и другое нормально. Все зависит от людей, они — главное.
— Рисование или полет в аэротрубе?
— А можно прыжок с парашютом? Когда я начинала работать в одной из пермских контор, к нам подошел директор департамента и говорит: «Ну, чего, кто со мной? Кто не прыгнул, тот не программист». Мы пошли. И я втянулась.
— Хорошо. Оупенспейс или кабинет?
— Кабинет. Не важно, сколько человек, главное — сидеть в уголочке где-нибудь, за стеночкой.
— Обучение с командировками в Москву или в родном городе?
— Смотря какое обучение. И то и другое, и можно без хлеба. Если есть крутой курс здесь, можно здесь. Если есть крутой курс там, можно и там.
Какие перспективы у профессий разработчик бд (oracle) и веб-разработчик? Что выбрать?
Сейчас стою на распутье и пытаюсь определиться в каком направлении дальше двигаться. В связи с чем хотелось услышать ваше мнение о перспективах таких направлений как веб-разработка и разработка БД.
Мой возраст 31 год. На данный момент работаю специалистом по внедрению биллинговой системы. Город Москва. Довольно большую часть времени занимает работа с бд oracle, написание сложных sql запросов и не очень сложных процедур и функций на pl/sql. Отсюда логично было бы двигаться в сторону pl/sql программиста, если не то обстоятельство, что мне также нравится веб-разработка. Я на джуниорском уровне знаю js, ноду, есть проект, который пишу. Также на базовом уровне знаю vue.js. Потратил на изучение этой области год.
Хотелось бы услышать мысли о перспективах этих двух направлений. В веб-разработке из минусов вижу большую конкуренцию, огромное количество джуниоров и ещё большее количество на подходе. Я состою в телеграм канале, где собрались люди, изучающие программирование и желающие устроиться в будущем джунами. Так вот из 150 человек где-то 120 хотят стать фрондентами и этот факт заставляет задуматься. Боюсь, в какой-то момент года через 1-3 может произойти дамп з/п и увеличится конкуренция уже не только среди джунов, но и мидлов, а может и синьоров.
Понятно, что нужно заниматься тем, что тебе нравится, но давайте опустим этот фактор, будем считать, что уровень «нравится» и там и там равнозначный. Давайте принимать во внимание только перспективы данных областей и порог входа.
Что такое Big data engineering, и как развиваться в этой сфере

Как отдельная Big Data Engineering появилась довольно недавно. И даже крупные компании очень часто путают, чем занимается этот специалист, каковы его компетенции и зачем он вообще в организации.
Поэтому в сегодняшней статье, специально к старту нового потока курса по Data Engineering, мы разберёмся, кто такой Big Data Engineer, чем он занимается и чем отличается от Data Analyst и Data Scientist. Этот гайд подойдёт людям, которые хотят работать с большими данными и присматриваются к профессии в целом. А также тем, кто просто хочет понять, чем занимаются инженеры данных.
Кто такой Big data engineer
Задачи, которые выполняет инженер больших данных, входят в цикл разработки машинного обучения. Его работа тесно связана с аналитикой данных и data science.
Главная задача Data engineer — построить систему хранения данных, очистить и отформатировать их, а также настроить процесс обновления и приёма данных для дальнейшей работы с ними. Помимо этого, инженер данных занимается непосредственным созданием моделей обработки информации и машинного обучения.
Инженер данных востребован в самых разных сферах: e-commerce, финансах, туризме, строительстве — в любом бизнесе, где есть поток разнообразных данных и потребность их анализировать.
К примеру, при разработке «умного» дома. Создание подобной системы требует считывания и обработки данных с IoT-сенсоров в режиме реального времени. Необходимо, чтобы данные обрабатывались с максимальной быстротой и минимальной задержкой. И даже при падении системы данные должны продолжать накапливаться, а затем и обрабатываться. Разработка системы, которая удовлетворяет этим требованиям, и есть задача инженера данных.
С технической стороны, наиболее частыми задачами инженера данных можно считать:
Разработка процессов конвейерной обработки данных. Это одна из основных задач BDE в любом проекте. Именно создание структуры процессов обработки и их реализация в контексте конкретной задачи. Эти процессы позволяют с максимальной эффективностью осуществлять ETL (extract, transform, load) — изъятие данных, их трансформирование и загрузку в другую систему для последующей обработки. В статичных и потоковых данных эти процессы значительно различаются. Для этого чаще всего используются фреймворки Kafka, Apache Spark, Storm, Flink, а также облачные сервисы Google Cloud и Azure.
Хранение данных. Разработка механизма хранения и доступа к данным — еще одна частая задача дата-инженеров. Нужно подобрать наиболее соответствующий тип баз данных — реляционные или нереляционные, а затем настроить сами процессы.
Обработка данных. Процессы структурирования, изменения типа, очищения данных и поиска аномалий во всех этих алгоритмах. Предварительная обработка может быть частью либо системы машинного обучения, либо системы конвейерной обработки данных.
Разработка инфраструктуры данных. Дата-инженер принимает участие в развёртывании и настройке существующих решений, определении необходимых ресурсных мощностей для программ и систем, построении систем сбора метрик и логов.

В иерархии работы над данными инженер отвечает за три нижние ступеньки: сбор, обработку и трансформацию данных.
Что должен знать Data Engineer
Структуры и алгоритмы данных;
Особенности хранения информации в SQL и NoSQL базах данных. Наиболее распространённые: MySQL, PostgreSQL, MongoDB, Oracle, HP Vertica, Amazon Redshift;
ETL-системы (BM WebSphere DataStage; Informatica PowerCenter; Oracle Data Integrator; SAP Data Services; SAS Data Integration Server);
Облачные сервисы для больших данных Amazon Web Services, Google Cloud Platform, Microsoft Azure;
Кластеры больших данных на базе Apache и SQL-движки для анализа данных;
Желательно знать языки программирования (Python, Scala, Java).
Стек умений и навыков инженера больших данных частично пересекается с дата-сайентистом, но в проектах они, скорее, дополняют друг друга.
Data Engineer сильнее в программировании, чем дата-сайентист. А тот, в свою очередь, сильнее в статистике. Сайентист способен разработать модель-прототип обработки данных, а инженер — качественно воплотить её в реальность и превратить код в продукт, который затем будет решать конкретные задачи.
Инженеру не нужны знания в Business Intelligence, а вот опыт разработки программного обеспечения и администрирования кластеров придётся как раз кстати.
Но, несмотря на то что Data Engineer и Data Scientist должны работать в команде, у них бывают конфликты. Ведь сайентист — это по сути потребитель данных, которые предоставляет инженер. И грамотно налаженная коммуникация между ними — залог успешности проекта в целом.
Плюсы и минусы профессии инженера больших данных
Плюсы:
Отрасль в целом и специальность в частности ещё очень молоды. Особенно в России и странах СНГ. Востребованность специалистов по BDE стабильно растёт, появляется всё больше проектов, для которых нужен именно инженер больших данных. На hh.ru, по состоянию на начало апреля, имеется 768 вакансий.
Пока что конкуренция на позиции Big Data Engineer в разы ниже, чем у Data Scientist. Для специалистов с опытом в разработке сейчас наиболее благоприятное время, чтобы перейти в специальность. Для изучения профессии с нуля или почти с нуля — тоже вполне хорошо (при должном старании). Тенденция роста рынка в целом будет продолжаться ближайшие несколько лет, и всё это время будет дефицит хороших спецов.
Задачи довольно разнообразные — рутина здесь есть, но её довольно немного. В большинстве случаев придётся проявлять изобретательность и применять творческий подход. Любителям экспериментировать тут настоящее раздолье.
Минусы
Большое многообразие инструментов и фреймворков. Действительно очень большое — и при подготовке к выполнению задачи приходится серьёзно анализировать преимущества и недостатки в каждом конкретном случае. А для этого нужно довольно глубоко знать возможности каждого из них. Да-да, именно каждого, а не одного или нескольких.
Уже сейчас есть целых шесть платформ, которые распространены в большинстве проектов.
Spark — популярный инструмент с богатой экосистемой и либами, для распределенных вычислений, который может использоваться для пакетных и потоковых приложений.
Flink — альтернатива Spark с унифицированным подходом к потоковым/пакетным вычислениям, получила широкую известность в сообществе разработчиков данных.
Kafka — сейчас уже полноценная потоковая платформа, способная выполнять аналитику в реальном времени и обрабатывать данные с высокой пропускной способностью. ElasticSearch — распределенный поисковый движок, построенный на основе Apache Lucene.
PostgreSQL — популярная бд с открытым исходным кодом.
Redshift — аналитическое решение для баз/хранилищ данных от AWS.
Без бэкграунда в разработке ворваться в BD Engineering сложно. Подобные кейсы есть, но основу профессии составляют спецы с опытом разработки от 1–2 лет. Да и уверенное владение Python или Scala уже на старте — это мастхэв.
Работа такого инженера во многом невидима. Его решения лежат в основе работы других специалистов, но при этом не направлены прямо на потребителя. Их потребитель — это Data Scientist и Data Analyst, из-за чего бывает, что инженера недооценивают. А уж изменить реальное и объективное влияние на конечный продукт и вовсе практически невозможно. Но это вполне компенсируется высокой зарплатой.
Как стать Data Engineer и куда расти
Профессия дата-инженера довольно требовательна к бэкграунду. Костяк профессии составляют разработчики на Python и Scala, которые решили уйти в Big Data. В русскоговорящих странах, к примеру, процент использования этих языков в работе с большими данными примерно 50/50. Если знаете Java — тоже хорошо.
Хорошее знание SQL тоже важно. Поэтому в Data Engineer часто попадают специалисты, которые уже ранее работали с данными: Data Analyst, Business Analyst, Data Scientist. Дата-сайентисту с опытом от 1–2 лет будет проще всего войти в специальность.
Фреймворками можно овладевать в процессе работы, но хотя бы несколько важно знать на хорошем уровне уже в самом начале.
Дальнейшее развитие для специалистов Big Data Engineers тоже довольно разнообразное. Можно уйти в смежные Data Science или Data Analytics, в архитектуру данных, Devops-специальности. Можно также уйти в чистую разработку на Python или Scala, но так делает довольно малый процент спецов.
Перспективы у профессии просто колоссальные. Согласно данным Dice Tech Job Report 2020, Data Engineering показывает невероятные темпы роста — в 2019 году рынок профессии увеличился на 50 %. Для сравнения: стандартным ростом считается 3–5 %.
В 2020 году темпы замедлились, но всё равно они многократно опережают другие отрасли. Спрос на специальность вырос ещё на 24,8 %. И подобные темпы сохранятся еще на протяжении минимум пяти лет.
Так что сейчас как раз просто шикарный момент, чтобы войти в профессию Data Engineering с нашим курсом Data Engineering и стать востребованным специалистом в любом серьёзном Data Science проекте. Пока рынок растёт настолько быстро, то возможность найти хорошую работу, есть даже у новичков.
Узнайте, как прокачаться и в других областях работы с данными или освоить их с нуля:
Работа с базами данных глазами разработчика

Когда вы разрабатываете новый функционал с использованием базы данных, цикл разработки обычно включает следующие этапы (но не ограничивается ими):
Написание SQL миграции → написание кода → тестирование → релиз → мониторинг.
В этой статье я хочу поделиться некоторыми практическими советами как можно сократить время этого цикла на каждом из этапов, при этом не снизив качество, а скорее даже повысив его.
Поскольку мы в компании работаем с PostgreSQL, а серверный код пишем на Java, то примеры будут основаны на этом стеке, хотя большинство идей не зависят от используемой БД и языка программирования.
SQL-миграция
Первый этап разработки после проектирования – это написание SQL-миграции. Основной совет – не проводите никаких ручных изменений схемы данных, а всегда делайте это через скрипты и храните их в одном месте.
У нас в компании разработчики сами пишут SQL-миграции, поэтому все миграции хранятся в репозитории с основным кодом. В некоторых компаниях изменением схемы занимаются администраторы БД, в таком случае реестр миграций находится где-то у них. Так или иначе такой подход приносит следующие преимущества:
Мы используем flyway, поэтому дальше будет немного информации о нем:
Когда Java-код устаревает, миграция может быть удалена, чтобы не плодить legacy (сам Java-класс миграции остаётся, но внутри он пустой). У нас это может произойти не ранее, чем через месяц после вывода миграции на production – мы считаем, что это достаточное время для того, чтобы все тестовые окружения и локальные среды разработчиков обновились. Стоит отметить, что поскольку Java-миграции используются только для DML, то их удаление никак не влияет на создание новых БД с нуля.
Важный нюанс для тех, кто использует pg_bouncer
Flyway во время проведения миграции накладывает блокировку для предотвращения одновременного выполнения нескольких миграций. Упрощенно это работает так:
Для решения этой проблемы мы используем отдельный небольшой пул соединений на pg_bouncer в сессионном режиме, который предназначен только для миграций. Со стороны приложения также есть отдельный пул, который содержит 1 соединение и оно закрывается по таймауту после проведения миграции, чтобы не удерживать ресурсы понапрасну.
Написание кода
Миграция создана, теперь пишем код.
Можно выделить 3 подхода для работы с БД со стороны приложения:
Но при этом важно отметить, что ORM, как и любой другой мощный инструмент, требует определенной квалификации при его использовании. Без должной настройки код, вероятнее всего, будет работать, но далеко не самым оптимальным образом.
Противоположный вариант – писать SQL вручную. Это позволяет полностью контролировать запросы – выполняется ровно то, что вы написали, никаких неожиданностей. Но, очевидно, что это увеличивает объём ручного труда и повышает требования к квалификации разработчиков.
DSL-библиотеки
Примерно посередине между этими подходами находится ещё один, который заключается в использовании DSL-библиотек (jOOQ, Querydsl и др.). Они, как правило, гораздо легковеснее, чем ORM, но более удобны, чем полностью ручная работа с БД. Использование DSL-библиотек не так распространено, поэтому в этой статье кратко рассмотрим именно этот подход.
Речь пойдёт про одну из библиотек — jOOQ. Что она предлагает:
При желании можно использовать plain sql:
Очевидно, что в таком случае корректность запроса и разбор результатов полностью лежат на ваших плечах.
jOOQ Record и POJO
BookRecord в примере выше является оберткой над строкой в таблице book и реализует паттерн active record. Поскольку этот класс являются частью слоя доступа к данным (к тому же конкретной его реализации), то вы, возможно, не хотели бы передавать его в другие слои приложения, а использовать какой-то свой pojo-объект. Для удобства конвертации record pojo jooq предлагает несколько механизмов: автоматические и ручной. В документации по ссылкам выше есть разнообразные примеры их использования при чтении, но нет примеров для вставки новых данных и обновления. Восполним этот пробел:
Как можно увидеть, все достаточно просто.
Этот подход позволяет скрывать детали реализации внутри класса слоя доступа к данным и избегать «протечки» в другие слои приложения.
Также jooq может генерировать DAO классы с набором базовых методов для упрощения работы с данными таблицы и уменьшения объема ручного кода (это очень похоже на Spring Data JPA):
Мы в компании не используем автогенерацию DAO-классов – генерируем только обертки над объектами БД, а запросы пишем сами. Генерация оберток происходит каждый раз при пересборке отдельного мавен-модуля, в котором хранятся миграции. Чуть далее будут детали о том, как это реализовано.
Тестирование
Написание тестов является важной составляющей процесса разработки – хорошие тесты гарантируют качество вашего кода и экономят время при его дальнейшей поддержке. При этом справедливо сказать, что и обратное утверждение верно – плохие тесты могут создавать иллюзию качественного кода, скрывать ошибки и замедлять процесс разработки. Таким образом недостаточно просто решить, что вы будете писать тесты, нужно делать это правильно. При этом понятие правильности тестов – весьма размытое и у всех немного свое.
Тоже самое касается и вопроса классификации тестов. В этой статье предлагается использовать следующий вариант разделения:
Интеграционные тесты в отличии от unit-тестов проверяют взаимодействие нескольких модулей между собой. Работа с БД – хороший пример, когда интеграционные тесты имеют смысл, потому что очень сложно качественно «замокать» БД, учитывая все её нюансы. Интеграционные тесты в большинстве случаев являются хорошим компромиссом между скоростью выполнения и гарантиями качества при тестировании БД в сравнении с другими видами тестирования. Поэтому в этой статье поговорим подробнее об этом виде тестирования.
Сквозное тестирование – самое масштабное. Для его проведения необходимо поднимать всё окружение. Оно гарантирует наибольший уровень уверенности в качестве продукта, но является самым медленным и дорогим.
Интеграционное тестирование
Когда речь заходит об интеграционном тестировании кода, работающего с БД, большинство разработчиков задаётся вопросами: как запускать БД, как инициализировать её состояние начальными данными и как делать это как можно быстрее?
Какое-то время назад достаточно распространённой практикой в интеграционном тестировании было использование h2. Это in-memory БД, написанная на Java, которая имеет режимы совместимости с большинством популярных БД. Отсутствие необходимости установки БД и универсальность h2 сделали её весьма удобной заменой настоящих БД, особенно если приложение не зависит от конкретной БД и использует только то, что входит в стандарт SQL (что бывает далеко не всегда).
Но проблемы начинаются в тот момент, когда вы используете какой-то хитрый функционал БД (или совсем новый из свежей версии), поддержка которого не реализована в h2. Да и в целом, поскольку это «симуляция» конкретной СУБД, то всегда могут быть некоторые отличия в поведении.
Ещё один вариант – использование embedded postgres. Это настоящий Postgres, поставляемый в виде архива и не требующий установки. Он позволяет работать как с обычной версией Postgres.
Есть несколько реализаций, самые популярные от Yandex и openTable. Мы в компании использовали версию от Yandex. Из минусов – он достаточно медленный при запуске (каждый раз происходит распаковка архива и запуск БД – занимает 2-5 секунд в зависимости от мощности компьютера), также есть проблема с отставанием от официальной релизной версии. Ещё сталкивались с проблемой, что после попытки остановки из кода происходила какая-нибудь ошибка и процесс Postgres оставался висеть в ОС – приходилось убивать его вручную.
testcontainers
Третий вариант – использование docker. Для Java существует библиотека testcontainers, которая предоставляет api для работы с docker-контейнерами из кода. Таким образом, любая зависимость в вашем приложении, которая имеет docker-образ, может быть заменена в тестах с помощью testcontainers. Также для для многих популярных технологий есть отдельные готовые классы, которые предоставляют более удобный api в зависимости от используемого образа:
Если для образа нет отдельного класса в testcontainers, то создание контейнера выглядит примерно так:
Если вы используете JUnit4, JUnit5 или Spock, то в testcontainers есть доп. поддержка для этих фреймворков, которая упрощает написание тестов.
Ускорение тестов с testcontainers
Несмотря на то, что переход с embedded postgres на testcontainers ускорил наши тесты за счёт более быстрого запуска Postgres, со временем тесты стали снова замедляться. Причиной этого послужило увеличение количества SQL-миграций, которые flyway выполняет при запуске. Когда количество миграций перевалило за сотню, время их выполнения было порядка 7-8 секунд, что значительно замедляло тесты. Это работало примерно так:
Пытаясь решить эту проблему, мы поняли, что миграции достаточно выполнять только один раз перед всеми тестами, сохранять состояние контейнера и затем использовать этот контейнер во всех тестах. Таким образом, алгоритм изменился:
Далее немного технических деталей о том, как это реализовать
Docker имеет встроенный механизм для создания нового образа на основе запущенного контейнера с помощью команды commit. Она позволяет кастомизировать образы, например, изменяя какие-либо настройки.
Важный нюанс, что команда не сохраняет данные примонтированных разделов. Но если взять официальный docker-образ Postgres, то директория PGDATA, в которой хранятся данные, располагается в отдельном разделе (чтобы после перезапуска контейнера данные не терялись), следовательно при выполнении commit состояние самой БД не сохраняется.
Решение простое – не использовать раздел для PGDATA, а держать данные в памяти, что для тестов вполне нормально. Есть 2 способа как добиться этого – использовать свой dockerfile (примерно вот такой) без создания раздела, либо переопределить переменную PGDATA при запуске официального контейнера (раздел останется, но использоваться не будет). Второй путь выглядит значительно проще:
Перед выполнением commit рекомендуется выполнить checkpoint для postgres, чтобы сбросить изменения из shared buffers на «диск» (который соответствует переопределенной переменной PGDATA):
Сам коммит выполняется примерно так:
Стоит отметить, что этот подход с использованием подготовленных образов может быть применим и со многими другими образами, что также позволит экономить время при запуске интеграционных тестов.
Еще пара слов об оптимизации времени сборки
Как уже было сказано ранее, при сборке отдельного мавен-модуля с миграциями помимо прочего выполняется генерация java-оберток над объектами БД. Для этого используется самописный мавен-плагин, который запускается перед компиляцией основного кода и выполняет 3 действия:
Плагин (метод «start»):
Методы save-state и stop реализованы аналогичным образом и поэтому здесь не представлены.
Релиз
Код написан и протестирован – пора релизить. В целом, сложность релиза зависит от следующих факторов:
Размер БД влияет на время миграции – чем больше база, тем больше вероятность, что вам потребуется провести длительную миграцию.
Бесшовность отчасти является результирующим фактором – если релиз проводится с выключением (downtime), то тогда первые 3 пункта не так важны и влияют только на время недоступности приложения.
Если говорить про наш сервис, то это:
Каждый сервер приложения при запуске сверяет версию БД с версиями скриптов, которые есть в исходном коде (в терминах flyway это называется validation). Если они различаются, сервер не будет запущен. Это гарантирует совместимость кода и базы данных. Не может возникнуть такая ситуация, когда, например, код работает с таблицей, которую еще не создали, потому что миграция находится в другой версии сервера.
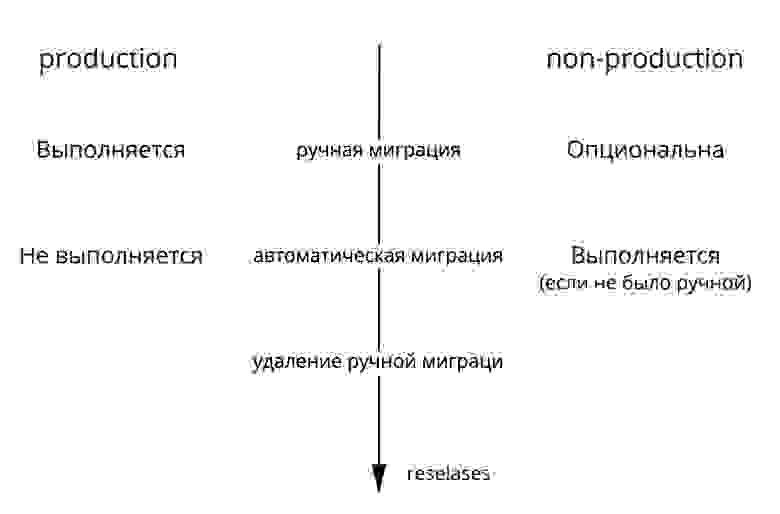
Но это конечно не решает проблемы, когда, например, в новой версии приложения есть миграция, удаляющая столбец в таблице, который может использоваться в старой версии сервера. Сейчас мы проверяем такие ситуации только на этапе ревью (оно обязательно), но по-хорошему необходимо внедрить доп. этап с такой проверкой в CI/CD-цикл.
Иногда миграции могут выполняться долго (например, при обновлении данных большой таблицы) и чтобы не замедлять при этом релизы, мы используем технику комбинированных миграций. Комбинированность заключается в ручном прогоне миграции на запущенном сервере (через панель администрирования, без flyway и, соответственно, без фиксирования в истории миграций), а затем «штатный» вывод такой же миграции в следующей версии сервера. На такие миграции накладываются следующие требования:
Мониторинг
После релиза цикл разработки не заканчивается. Чтобы понять работает ли новый функционал (и как он работает) необходимо «обкладываться» метриками. Их можно разделить на 2 группы: бизнесовые и системные.
Первая группа сильно зависит от предметной области: для почтового сервера полезно знать количество отправленных писем, для новостного ресурса – количество уникальных пользователей в сутки и т.п.
Метрики второй группы примерно одинаковы для всех – они определяют техническое состояние сервера: cpu, памяти, сети, БД и пр.
Что конкретно нужно мониторить и как это делать – это тема огромного множества отдельных статей и здесь она затрагиваться не будет. Хочется напомнить лишь самые базовые (даже капитанские) вещи:
определяйте метрики заранее
Необходимо определить перечень основных метрик. И сделать это стоит заранее, до релиза, а не после первого инцидента, когда вы не понимаете, что происходит с системой.
настраивайте автоматические алерты
Это ускорит время вашей реакции и сэкономит время на ручном мониторинге. В идеале, вы должны узнавать о проблемах раньше, чем их почувствуют пользователи и напишут вам.
собирайте метрики со всех узлов
Метрик, как и логов, много не бывает. Наличие данных с каждого узла вашей системы (сервер приложения, БД, пулер соединений, балансировщик и пр.) позволяет иметь полную картину о её состоянии, и в случае необходимости вы сможете быстрее локализовать проблему.
Простой пример: загрузка данных какой-либо веб-страницы начала тормозить. Причин может быть множество:



