Поиск текста в файлах Linux
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux всё это делается с помощью одной очень простой, но в то же время мощной утилиты grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим, как выполняется поиск текста в файлах Linux, подробно разберём возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Утилита grep решает множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [имя файла. ]
$ команда | grep [опции] шаблон
Возможность фильтровать стандартный вывод пригодится,например, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном отчёте утилиты ps.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
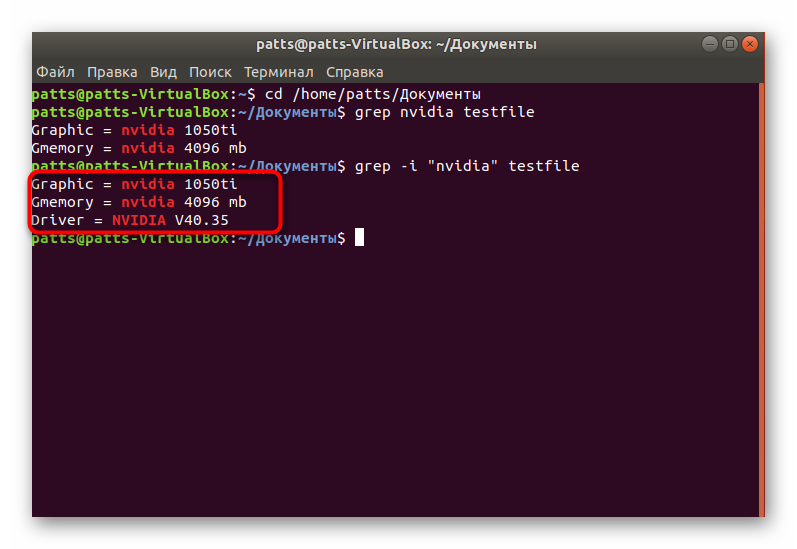
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
grep User /etc/passwd
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
grep «^Nov 10» messages.1
Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s
Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0), stratum 10
grep «terminating.$» messages
Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating.
Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
Найдём все строки, которые содержат цифры:
grep «5» /var/log/Xorg.0.log
Рекурсивное использование grep
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ServerName zendsite.localhost
DocumentRoot /var/www/localhost/htdocs/zendsite
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Поиск двух слов
Можно искать по содержимому файла не одно слово, а два сразу:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Цветной вывод в grep
Также вы можете заставить программу выделять другим цветом вхождения в выводе:

Выводы
Вот и всё. Мы рассмотрели использование команды grep для поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Что такое grep и с чем его едят
Эта заметка навеяна мелькавшими последнее время на хабре постами двух тематик — «интересные команды unix» и «как я подбирал программиста». И описываемые там команды, конечно, местами интересные, но редко практически полезные, а выясняется, что реально полезным инструментарием мы пользоваться и не умеем.
Небольшое лирическое отступление:
Года три назад меня попросили провести собеседование с претендентами на должность unix-сисадмина. На двух крупнейших на тот момент фриланс-биржах на вакансию откликнулись восемь претендентов, двое из которых входили в ТОП-5 рейтинга этих бирж. Я никогда не требую от админов знания наизусть конфигов и считаю, что нужный софт всегда освоится, если есть желание читать, логика в действиях и умение правильно пользоваться инструментарием системы. Посему для начала претендентам были даны две задачки, примерно такого плана:
— поместить задание в крон, которое будет выполняться в каждый чётный час и в 3 часа;
— распечатать из файла /var/run/dmesg.boot информацию о процессоре.
К моему удивлению никто из претендентов с обоими вопросами не справился. Двое, в принципе, не знали о существовании grep.

Поэтому… Лето… Пятница… Перед шашлыками немного поговорим о grep.
Зная местную публику и дабы не возникало излишних инсинуаций сообщаю, что всё нижеизложенное справедливо для
Это важно в связи с
Для начала о том как мы обычно grep’аем файлы.
Используя cat:
Но зачем? Ведь можно и так:
Или вот так (ненавижу такую конструкцию):
Зачем-то считаем отобранные строки с помощью wc:
Сделаем тестовый файлик:
И приступим к поискам:
Опция -w позволяет искать по слову целиком:
А если нужно по началу или концу слова?
Стоящие в начале или конце строки?
Хотите увидеть строки в окрестности искомой?
Только снизу или сверху?
А ещё мы умеем так
И наоборот исключая эти
Разумеется grep поддерживает и прочие базовые квантификаторы, метасимволы и другие прелести регулярок
Пару практических примеров:
Отбираем только строки с ip:
Работает, но так симпатичнее:
Уберём строку с комментарием?
А теперь выберем только сами ip
Вот незадача… Закомментированная строка вернулась. Это связано с особенностью обработки шаблонов. Как быть? Вот так:
Всё бы ничего, но строка «48798 2 S+ 0:00.00 grep ttyv» нам не нужна. Используем -v
Некрасивая конструкция? Потрюкачим немного:
Также не забываем про | (ИЛИ)
ну и тоже самое, иначе:
Ну и если об использовании регулярок в grep’e помнят многие, то об использовании POSIX классов как-то забывают, а это тоже иногда удобно.
Отберём строки с заглавными символами:
Плохо видно что нашли? Подсветим: 
Ну и ещё пару трюков для затравки.
Первый скорее академичный. За лет 15 ни разу его не использовал:
Нужно из нашего тестового файла выбрать строки содержащие six или seven или eight:
Пока всё просто:
А теперь только те строки в которых six или seven или eight встречаются несколько раз. Эта фишка именуется Backreferences
Ну и второй трюк, куда более полезный. Необходимо вывести строки в которых 504 с обеих сторон ограничено табуляцией.
Ох как тут не хватает поддержки PCRE…
Использование POSIX-классов не спасает:
На помощь приходит конструкция [CTRL+V][TAB]:
Что ещё не сказал? Разумеется, grep умеет искать в файлах/каталогах и, разумеется, рекурсивно. Найдём в исходниках код, где разрешается использование Intel’ом сторонних SFP-шек. Как пишется allow_unsupported_sfp или unsupported_allow_sfp не помню. Ну да и ладно — это проблемы grep’а:
Надеюсь не утомил. И это была только вершина айсберга grep. Приятного Вам чтения, а мне аппетита на шашлыках!
Ну и удачного Вам grep’a!
Команда Grep в Linux (Поиск текста в файлах)
Grep Command in Linux (Find Text in Files)

Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показывать только имя файла
Вывод будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Показать номера строк
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
Печать строк перед сопоставлением
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Что делает команда grep
Команда grep служит для поиска строк, содержащих заданный пользователем образец.
Причем обязательным для ввода является только ОБРАЗЕЦ, можно обойтись даже без имени файла (аргумента).
Команда grep без опций и аргумента.
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк. Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки. Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки. Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter. В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (\n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Работа с файлами
Команда grep может обрабатывать любое количество файлов одновременно. Создадим три файла:
Команда grep вовсе не ограничена одним выражением в качестве ОБРАЗЦА, можно задавать хоть целые фразы. Только их нужно заключать в кавычки (одинарные или двойные):
Возможности поиска при помощи команды grep могут быть значительно расширены применением групповых символов. Например, уже упоминавшийся астериск (звездочка) используется для представления любого символа или группы символов, если речь идет о тексте, и любого файла или группы файлов, если речь идет о директории.
Создадим директорию /example, в которую поместим файлы наших примеров: 123.txt, ast.txt, alice.txt и дадим команду:
То есть мы приказали просмотреть все файлы директории /example. Таким способом можно обследовать такие огромные директории как /usr, /dev, и любые другие.
Параметры grep
/boot/grub/grub.txt:Press the [Esc] key to return to the GRUB menu. /boot/grub/menu.lst:# GRUB configuration file ‘/boot/grub/menu.lst’. /boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
То есть в восьми строках файла /etc/group встречается сочетание символов root.
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
находит точное соответствие в файле alice.txt.
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
Немного хитростей
Если продолжить описание множества опций команды grep, то статья станет утомительной и нечитаемой. Поэтому, рассмотрев необходимый минимум опций, можно развлечься всякими хитростями при применении этой замечательной команды.
Хитрость первая
Как заставить grep указать в выводе имя файла, где найдено соответствие ОБРАЗЦУ? Например, мы хотим найти строку, содержащую выражение «красивая девочка» в файле alice.txt, да так, чтобы в выводе фигурировало имя файла (для отчета). Если просто дать команду:
То никакого имени файла там не будет. Но стоит добавить в аргументы еще один файл, как все заработает. Обычно, чтобы избежать неожиданностей, указывают файл /dev/null:
Хитрость вторая
Это был файл kot.txt целиком.
Эти начинаются на kot-.
А вот был «чистый» кот.
Прошу простить за транслитерацию, но с нашими буквами эта хитрость как-то не срабатывает, а с английскими словами не все поймут.
Хитрость третья
Как быть, если ОБРАЗЕЦ начинается с дефиса, ведь команда примет его за опцию?
Совсем другое дело.
Хитрость четвертая
Как посмотреть соседние строчки?
Требуется соблюсти следующие условия:
Просмотр вверх и вниз на две строки.
Просмотр вниз на одну строку.
Требуется соблюсти следующие условия:
Просмотр вверх на одну строку.
Хитрость пятая
Что означают сообщения в первых двух строках вывода?
Хитрость шестая
Как искать строки, содержащие несколько ОБРАЗЦОВ?
Применить программный канал, канализируя вывод одной команды grep с вводом следующей команды grep.
Хитрость седьмая
Можно ли искать одновременно в стандартном вводе и в файле?. Можно, если перед именем файла поставить дефис:
Внимание: Если перед дефисом и после него не будет пробелов, то команда не сработает.
Но настало время вернуться к опциям команды grep.
Пока я занимался хитростями, успел позабыть, какие из опций уже описал, а какие нет. Поэтому я дал команду:
и получил файл option.txt, в котором перечислены все фигурирующие в файле grep-ru.txt опции.
Общее количество опций программы подавляет, поэтому пойдем по алфавиту, пропуская те, что я уже описал.
Весьма полезная опция, когда нужно искать несколько ОБРАЗЦОВ, причем не в одной строке, как мы делали в шестой Хитрости, а в разных. Для того чтобы воспользоваться этой опцией, нужно составить файл, в котором поместить искомые ОБРАЗЦЫ по одному на строчке:
А затем дать команду:
Возвращает не всю строку, где найдено соответствие ОБРАЗЦУ, а только совпадающую с ОБРАЗЦОМ часть строки.
$ grep ‘английскими’ grep-ru.txt
Прошу простить за транслитерацию, но с нашими буквами как-то эта хитрость не срабатывает, а с английскими словами не все поймут.
Подавляет сообщения о несуществующих или нечитаемых файлах.
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
При рекурсивном исследовании директорий пропускать файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Команда grep и регулярные выражения
Тема регулярных выражений настолько обширна, что требует для своего освещения отдельной статьи; в данной статье мы не будем ее подробно разбирать. Скажу лишь, что существует несколько версий синтаксиса регулярных выражений: Базовый (basic) BRE, Расширенный (extended) ERE и регулярные выражения языка Perl.
Рассматривает ОБРАЗЕЦ как базовое регулярное выражение. Эта опция используется по умолчанию.
Рассматривает ОБРАЗЕЦ как расширенное регулярное выражение.
Рассматривает ОБРАЗЕЦ как регулярное выражение языка Perl.
Команда grep и символы кириллицы.
Читая эту статью, вы не могли не заметить, что большинство примеров составлено на русском языке. Я еще не встречал консольных команд, столь хорошо «владеющих русским». Теперь, когда я разобрался с этой командой, то уже не понимаю, как мог обходиться без нее при написании статей (по-русски, разумеется). Лишь некоторые опции «дают прокол» при обработке символов кириллицы.
Резюме команды grep
Команда grep настолько полезна, многофункциональна и проста в употреблении, что, однажды познакомившись с ней, невозможно представить себе работы без нее. Особенно полезна эта команда в качестве фильтра в составе программных каналов (pipes).
Что такое grep и с чем его едят – примеры команды grep в Linux
Команда grep (расшифровывается как global regular expression print) – одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле.
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
grep user /etc/mysql/my.cnf
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если
исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Использование egrep в Linux
Есть возможность поиска по нескольким файлам и в подобном случае перед строкой выводится имя файла.
А следующий запрос выводит весь код, исключая строки, содержащие только комментарии:
В виде egrep, даже если вы не избегаете метасимволы, команда будет относиться к ним как к специальным символам и заменять их своим особым значением вместо того, чтобы рассматривать их как часть строки
Использование fgrep в Linux
Fgrep ищет полную строку и не распознает специальные символы как часть непрерывного выражения, несмотря на то экранированы символы или нет.
Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Может быть использовать его для удаления строк (удаление всех пустых строк):
Основным инструментом работы с sed является выражение типа:
Так, образчик, если выполнить команду:
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
Синтаксис для команды grep
Как использовать команду Grep?
Принадлежащая к семейству Unix команда grep является одним из самых универсальных и полезных инструментов. Эта утилита выполняет поиск в текстовом файле за заданным нами паттерном. Другими словами, с помощью grep вы можете найти необходимое вам слово или значение. А содержащие ваш запрос строки или строка будут выведены в терминал.
На первый взгляд, может показаться, что эта утилита имеет слишком узкое применение. Однако она способна значительно облегчить жизнь системным администраторам, которым приходится обрабатывать множество служб с различными файлами конфигурации. С помощью команды они могут быстро найти необходимые им строки в этих файлах.
Сначала давайте подключимся к VPS с помощью SSH. Вот статья, в которой показано, как это сделать с помощью PuTTY SSH.
Если на вашем компьютере вы используете Linux, просто откройте терминал.
Синтаксис команды grep при поиске в одном файле выглядит следующим образом:
Вы можете просмотреть документацию и пояснения к различным опциям команды, введя в командной строке:
Как видите, команда предлагает нам множество опций. Однако наиболее важными и часто используемыми являются параметры:
Подготовительные работы
Все дальнейшие действия будут производиться через стандартную консоль, она же позволяет открывать файлы только путем указания полного пути к ним либо если «Терминал» запущен из необходимой директории. Узнать родительскую папку файла и перейти к ней в консоли можно так:
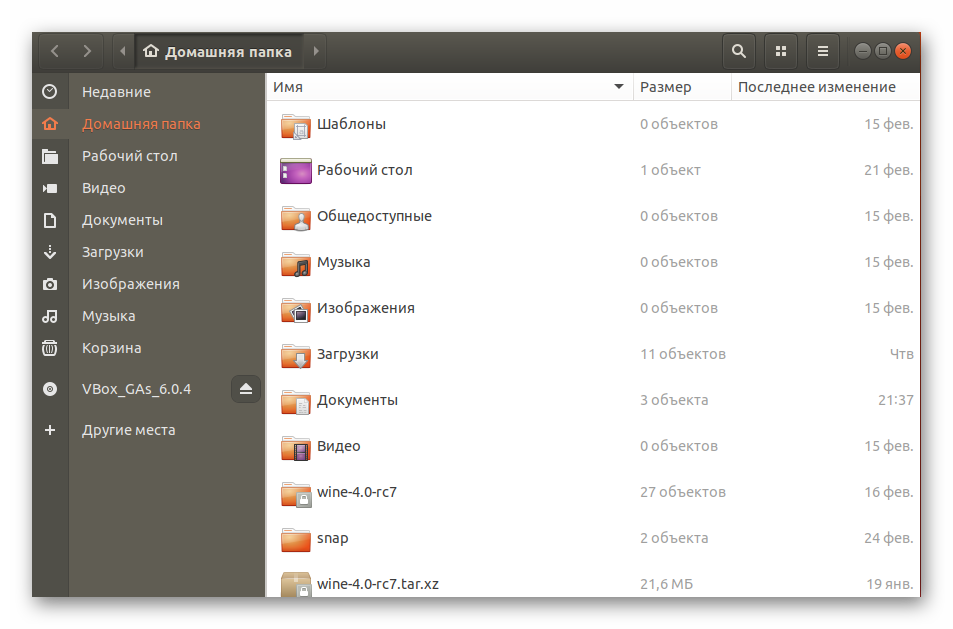
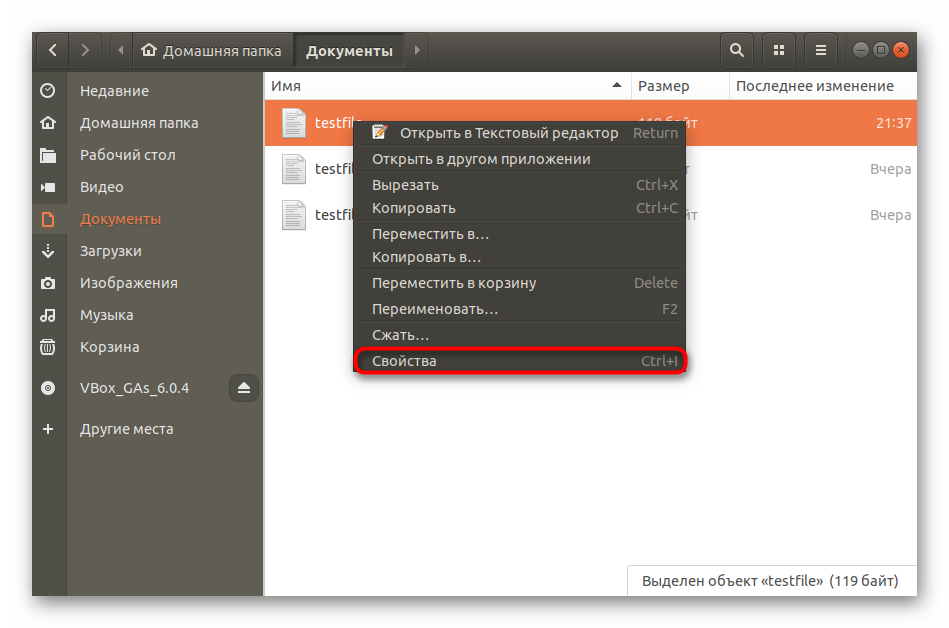
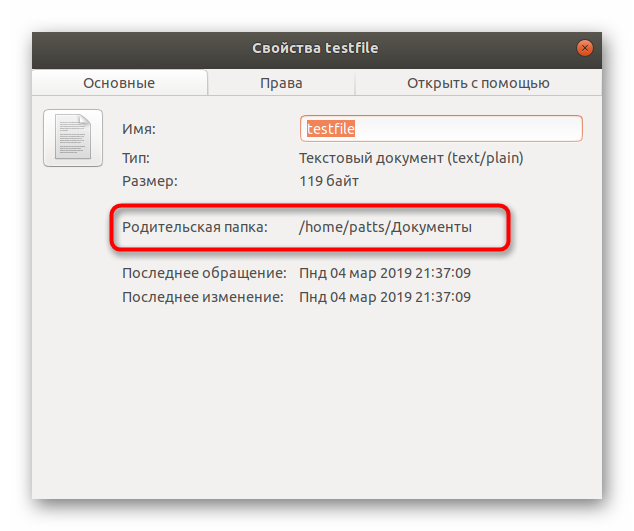
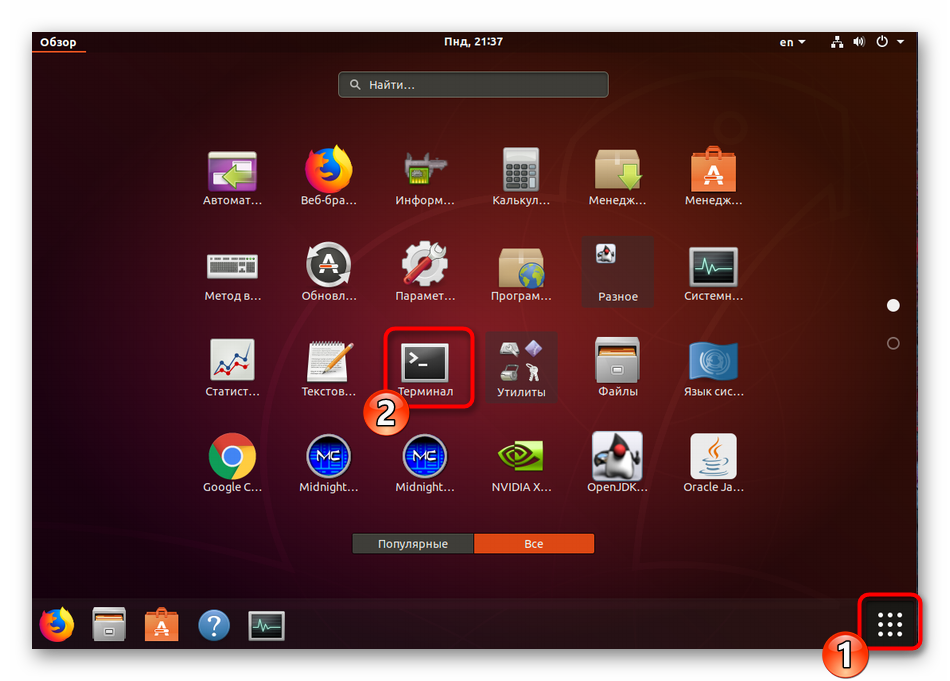
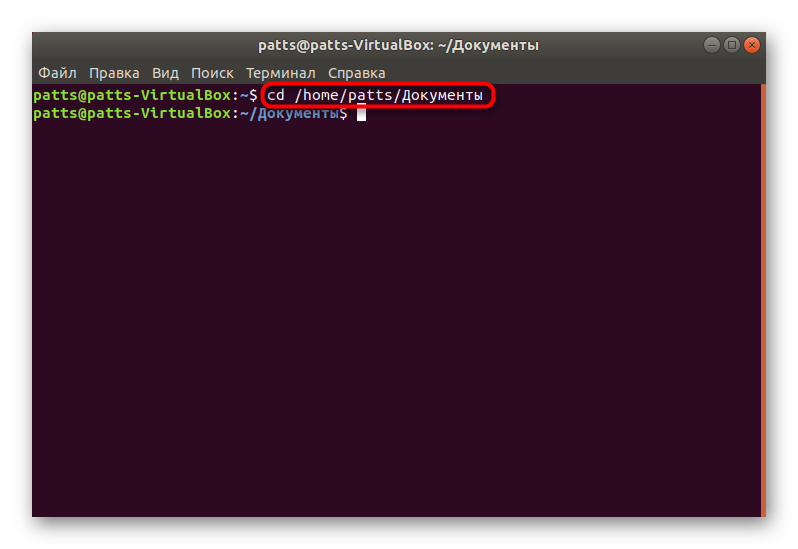
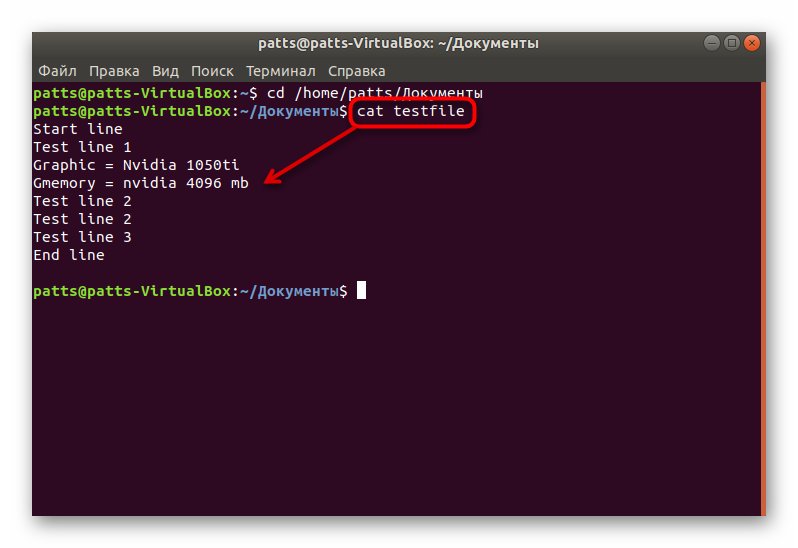
Задействуйте команду cat + название файла, если хотите просмотреть полное содержимое. Детальные инструкции по работе с этой командой ищите в другой нашей статье по ссылке ниже.
Благодаря выполнению приведенных выше действий вы можете использовать grep, находясь в нужной директории, без указания полного пути к файлу.
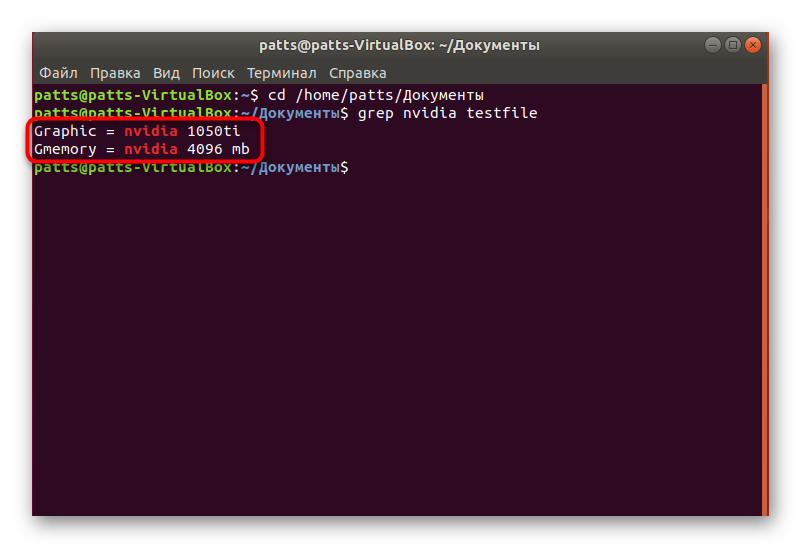
Стандартный поиск по содержимому
Прежде чем переходить к рассмотрению всех доступных аргументов, важно отметить и обычный поиск по содержимому. Он будет полезен в тех моментах, когда необходимо найти простое совпадение по значению и вывести на экран все подходящие строки.
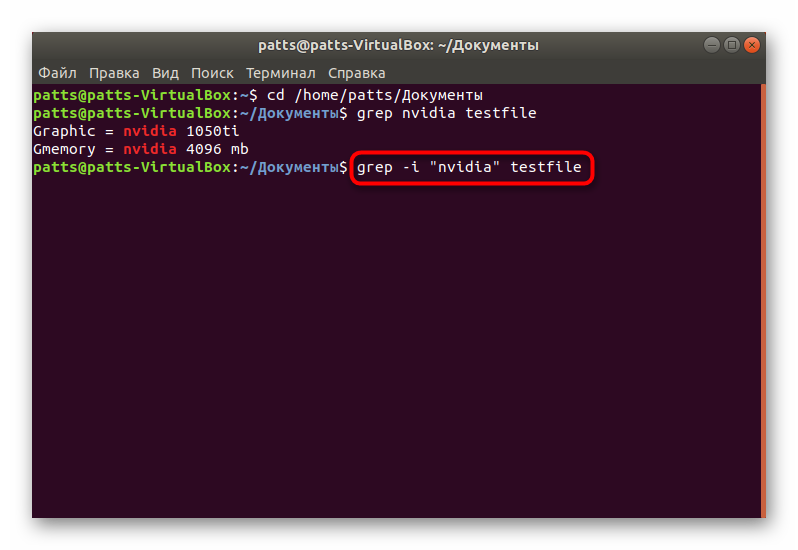
Пример использования
Допустим, требуется быстро найти фразу «our products» в HTML-файлах на компьютере. Начнем с поиска в одном из них. В данном случае ШАБЛОН – это «our products», а ФАЙЛ – product-listing.html
$ grep “our products” product-listing.html
You will find that all of our products are impeccably designed and meet the highest manufacturing standards available anywhere.
Была найдена одна строка, содержащая указанный шаблон, и grep выводит всю соответствующую строку на терминал. Строка длиннее ширины окна терминала, поэтому текст переносится на следующие строки, но данный вывод соответствует ровно одной строке в файле.
Важно: ШАБЛОН интерпретируется grep как регулярное выражение. В рассмотренном выше примере все использованные символы (буквы и пробел) интерпретируются в регулярных выражениях буквально, поэтому выполняется только поиск точной фразы. Однако, у других символов, например, некоторых знаков препинания, может быть особое значение.
1. Простой поиск в файле
Давайте рассмотрим пример в файле “/etc/passwd” для поиска строки в файле. Чтобы найти слово “system” при помощи команды grep, используйте команду:
]# cat /etc/passwd|grep system
systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin
2. Подсчет появления слов.
В приведенном выше примере мы имеем в системе поиск слов в файл
е “/etc/passwd”. Если мы хотим знать количество или число появлений слова в файле, то используйте опцию ниже:
Выше указанно, что слово появилось два раза в файле “/etc/passwd”.
3. Игнорировать регистрозависимые слова
Команда grep чувствительна к регистру, это означает, что он будет искать только данное слово в файле. Чтобы проверить эту функцию, создайте один файл с именем «test.txt» и с содержанием, как показано ниже:
[root@destroyer tmp]# cat test.txt AndreyEx andreyex ANDREYEX Andreyex [root@destroyer tmp]#
Теперь, если вы попытаетесь найти строку «andreyex», то команда не будет перечислять все слова «andreyex» с разными вариантами, как показано ниже:
[root@destroyer tmp]# grep andreyex test.txt andreyex [root@destroyer tmp]#
Этот результат подтверждает, что только один вариант будет показан, игнорируя остальную часть слова «andreyex» с разными вариантами. И если вы хотите игнорировать этот случай, вам нужно использовать параметр «-i» с grep, как показано ниже:
4. Две разные строки внутри файла с командой grep
Теперь, если вы хотите найти два слова или строки с помощью команды grep, то вы должны задать расширенные. В следующей команде мы находим две строки «system» и «nobody» в файле /etc/passwd.
]# grep ‘system|nobody’ /etc/passwd nobody:x:89:89:Nobody:/:/sbin/nologin systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin [root@destroyer
5. Рекурсивный поиск
В выводе выше мы можем иметь возможность видеть имя файла, в котором мы нашли строку, и если вы хотите убрать имя файла в конечном результате, то используйте опцию «-h», как показано ниже:
6. Вывод команды grep.
Если вы хотите найти строку или слово в любом выводе команды, то вы должны использовать оператор «|», а затем в grep. Допустим, вы хотите найти в памяти, связанные слова вывода команды dmesg, то используйте следующую команду.
]# dmesg |grep memory [ 0.000000] Base memory trampoline at [ffff880000098000] 98000 size 19456 [ 0.000000] init_memory_mapping: [mem 0x00000000-0x000fffff] [ 0.000000] init_memory_mapping: [mem 0x3fe00000-0x4fffffff] [ 0.000000] init_memory_mapping: [mem 0x3c000000-0x4fdfffff] [ 0.000000] init_memory_mapping: [mem 0x00100000-0x4bffffff] [ 0.000000] kexec: crashkernel=auto resulted in zero bytes of reserved memory. [ 0.000000] Early memory node ranges [ 0.000000] PM: Registered nosave memory: [mem 0x0003e000-0x0003ffff] [ 0.000000] PM: Registered nosave memory: [mem 0x000a0000-0x000dffff] [ 0.000000] PM: Registered nosave memory: [mem 0x000e0000-0x000fffff] [ 0.000000] please try ‘cgroup_disable=memory’ option if you don’t want memory cgroups [ 0.030181] Initializing cgroup subsys memory [ 0.862358] Freeing initrd memory: 23532k freed [ 1.064599] Non-volatile memory driver v1.3 [ 1.069351] crash memory driver: version 1.1 [ 1.186673] Freeing unused kernel memory: 1430k freed [ 5.567780] [TTM] Zone kernel: Available graphics memory: 480345 kiB [root@destroyer
7. Инвертирование с помощью команды grep в Linux
Допустим, если вы хотите отобразить все слова в файле, который не содержит какое-либо конкретное слово, то используйте опцию «-v». Это позволяет создать один файл с содержимым, как показано ниже:
[root@destroyer tmp]# cat test.txt Andreyex12 Andreyex454 Andreyex34343 Andreyex LinuxRoutes Linux [root@destroyer tmp]#
Если мы не хотим печатать строки, содержащие слово Linux, то используйте следующую команду.
8. Точное совпадение слова
В соответствии с примером, приведенным в пункте 7, если мы ищем Andreyex, то он будет печатать все вхождение Andreyex как «Andreyex12», «Andreyex454», «Andreyex34343», а также «Andreyex», как показано ниже:
[root@destroyer tmp]# grep Andreyex test.txt Andreyex12 Andreyex454 Andreyex34343 Andreyex [root@destroyer tmp]#
тогда, если мы хотим найти точное слово «Andreyex» вместо этого, чтобы перечислить весь вывод выше, то используйте опцию «-w», как показано ниже:
Количество совпадающих линий
Инвертирование совпадений в команде Grep
Чтобы отобразить строки, которые не совпадают со строкой Linuxvsem в файле names.txt, выполните следующую команду.
Строка поиска в стандартном выводе
Если необходимо найти строку в выводе команды — это можно сделать, комбинируя команду grep с другой командой.
Например, чтобы найти строку inet6 в выводе команды, ifconfig выполните следующую команду:
ifconfig | grep inet6
Рекурсивный поиск
В приведенном ниже примере строка «Linuxvsem» будет найдена во всех файлах внутри каталога linux:
Для поиска строки во всех каталогах вы можете запустить следующую команду:
Просмотр номеров строк, содержащих совпадения
Еще полезнее может быть информация о месторасположении строки с совпадением в файле. Если указать опцию –n, grep перед каждой содержащей совпадение строкой будет выводить ее номер в файле:
Перед содержащей соответствие строкой выведено «18:», что соответствует 18-й строке.
Выполнение поиска без учета регистра
Допустим, фраза «string search» расположена в начале предложения или набрана в верхнем регистре. Для поиска без учета регистра можно указать опцию –i:
You will find that all of string search are impeccably designed and meet the highest manufacturing standards available anywhere.
String search are manufactured using only the finest top-grain leather.



