Transact-SQL группировка данных GROUP BY
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.

И для вступления небольшая теория.
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
Я ее заполнил следующими данными:
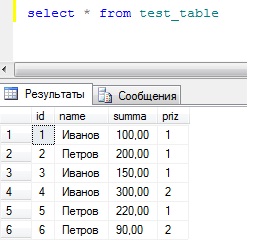
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
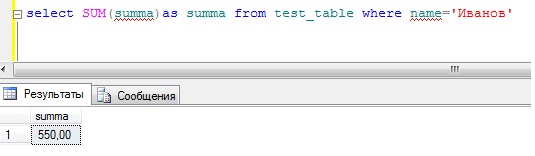
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
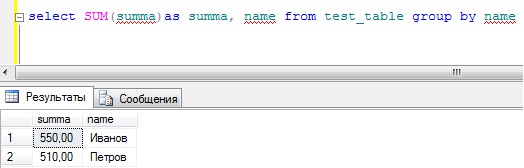
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
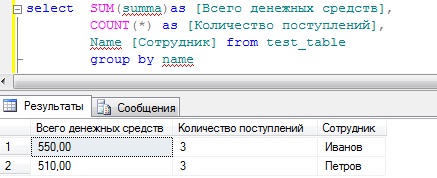
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
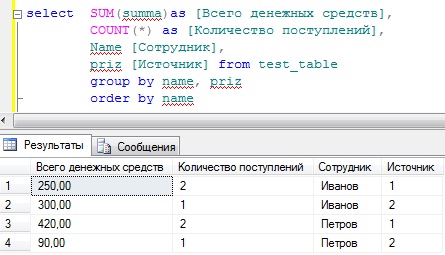
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
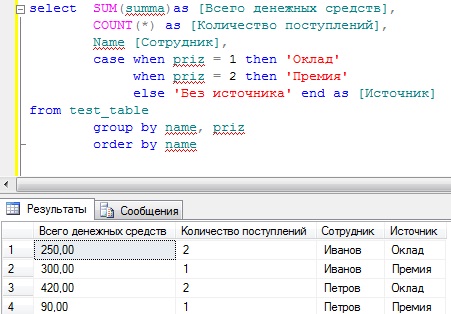
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
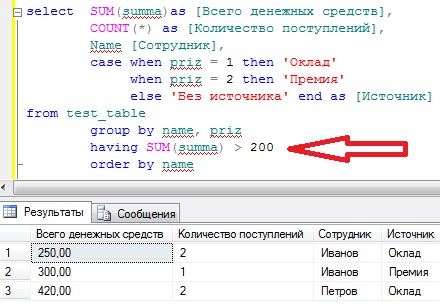
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
GROUP BY в SQL

Одной из важных команд в SQL является GROUP BY. Данная конструкция создана для выборки отдельных групп строк из таблицы, к каждой из которых применяются функции, указанные в SELECT (например, COUNT(), MIN() и так далее). Давайте разберём GROUP BY в SQL на конкретных примерах.
Допустим, у нас есть таблица супермаркетов:
Нам необходимо узнать среднюю цену на молоко у каждого супермаркета. Обратите внимание, что shop_id может повторяться (ведь есть сети супермакетов). Поэтому нам необходимо сделать группу по shop_id, и для каждой строки в этой группе вычислить среднюю цену.
Исходная таблица выглядит следующим образом:
| id | shop_id | price |
| 1 | 1 | 40 |
| 2 | 2 | 36 |
| 3 | 1 | 35 |
| 4 | 3 | 38 |
| 5 | 4 | 39 |
| 6 | 3 | 38 |
| 7 | 3 | 35 |
Для решения нашей задачи мы используем GROUP BY:
SELECT `shop_id`, AVG(`price`) FROM `table` GROUP BY `shop_id`
В результате получится следующее:
| shop_id | AVG(`price`) |
| 1 | 37.5 |
| 2 | 36.0 |
| 3 | 37.0 |
| 4 | 39.0 |
Таким образом, мы узнали среднюю цену в конкретной сети супермаркетов (или в одиночном магазине).
Ещё одним очень частым применением GROUP BY в SQL является выборка уникальных записей из таблиц. В предыдущем примере Вы заметили, что в результирующей выборке нет повторяющихся shop_id, тогда как в исходной таблице они были.
Допустим, у нас есть таблица с пользователями:
Таким образом, нам надо выбрать все записи с уникальным hash. Для этого опять же используется GROUP BY:
SELECT * FROM `table` GROUP BY `hash`
В результате, будут извлечены только уникальные hash, то есть 2 одинаковых hash в результирующей выборке Вы не увидите.
Вот таких два практических примера использования GROUP BY в SQL мы разобрали.

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Комментарии ( 6 ):
У вас пропущена запятая в строке: «Допустим у нас есть таблица с пользователями:» Хорошие статьи. Пишите по SQL по-больше! Там много всяких встроенных функций, про которые не плохо бы рассказать
Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Базы данных
SQL оператор GROUP BY
В этом учебном материале вы узнаете, как использовать SQL оператор GROUP BY с синтаксисом и примерами.
Описание
SQL оператор GROUP BY можно использовать в операторе SELECT для сбора данных по нескольким записям и группировки результатов по одному или нескольким столбцам.
Синтаксис
Синтаксис оператора GROUP BY в SQL:
Параметры или аргументы
Давайте посмотрим, как использовать GROUP BY с функцией SUM в SQL.
В этом примере у нас есть таблица employees со следующими данными:
| employee_number | first_name | last_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Justin | Bieber | 62000 | 500 |
| 1002 | Selena | Gomez | 57500 | 500 |
| 1003 | Mila | Kunis | 71000 | 501 |
| 1004 | Tom | Cruise | 42000 | 501 |
Введите следующий SQL оператор:
Будет выбрано 2 записи. Вот результаты, которые вы получите:
| dept_id | total_salaries |
|---|---|
| 500 | 119500 |
| 501 | 113000 |
Давайте посмотрим, как использовать предложение GROUP BY с функцией COUNT в SQL.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Введите следующий SQL оператор:
Будет выбрано 3 записи. Вот результаты, которые вы должны получить:
| category_id | total_products |
|---|---|
| 25 | 1 |
| 50 | 4 |
| 75 | 1 |
Давайте теперь посмотрим, как использовать предложение GROUP BY с функцией MIN в SQL.
В этом примере мы снова будем использовать таблицу employees со следующими данными:
SQL Group By: Полное руководство

Оператор SQL GROUP BY появляется в агрегатных функциях. Он используется для сопоставления данных, выбранных вами из запроса, по определённому столбцу. Вы можете указать несколько столбцов, которые будут сгруппированы с помощью оператора GROUP BY.
Когда вы работаете с агрегатными функциями в SQL, часто бывает необходимо сгруппировать строки по общим значениям столбцов.
Например, предположим, что вы хотите получить список названий филиалов вашего бизнеса. Помимо этой информации вы хотите увидеть количество сотрудников, работающих в этих филиалах. Вам нужно будет использовать агрегатную функцию и сгруппировать по имени ветки.
Вот здесь-то и появляется предложение SQL GROUP BY. В этом руководстве мы собираемся обсудить, как использовать предложение GROUP BY.
Обновление агрегатных функций
Часто — когда вы работаете с базой данных — вы не хотите видеть фактические данные в базе данных. Вместо этого вам может потребоваться информация о данных. Например, вы можете узнать количество уникальных продуктов, которые продаёт ваш бизнес, или максимальный балл в таблице лидеров.
В SQL есть несколько встроенных функций, которые позволяют получить эту информацию. Они называются агрегатными функциями.
Например, предположим, что вы хотите узнать, сколько сотрудников являются торговыми партнёрами, вы можете использовать функцию COUNT. Функция COUNT подсчитывает и возвращает количество строк, соответствующих определённому набору критериев. Другие агрегатные функции включают SUM, AVG, MIN и MAX.
SQL Group By
Предложение SQL GROUP BY сопоставляет строки. Предложения GROUP BY часто встречаются в запросах, использующих агрегатные функции, такие как MIN и MAX. Оператор GROUP BY сообщает SQL, как агрегировать информацию в любом неагрегированном столбце, который вы запросили.
Синтаксис оператора GROUP BY:
SELECT COUNT(column1_name), column2_name
FROM table1_name
GROUP BY column2_name;
Мы использовали агрегатную функцию в нашем запросе и указали другой столбец.
В любом запросе это так, нам нужно использовать оператор GROUP BY. Оператор GROUP BY сообщает SQL, как отображать данные ветки, даже если они находятся за пределами агрегатной функции. Вам нужно сгруппировать по таблице, которой нет в агрегатной функции.
Предложение GROUP BY используется только в операторах SQL SELECT.
Давайте посмотрим на пример предложения GROUP BY в SQL.
Пример SQL Group By
Допустим, мы хотим найти общее количество сотрудников с каждым названием, присвоенным рабочей силе. Другими словами, мы хотим знать, сколько у нас торговых партнёров, сколько у нас директоров по маркетингу и так далее.
Мы могли бы использовать следующий запрос для получения этой информации:
SELECT title, COUNT(title)
FROM employees
GROUP BY title;
Запрос возвращает несколько записей:
| заглавие | считать |
| Старший специалист по продажам | 1 |
| Сотрудник по продажам | 4 |
| Вице-президент по продажам | 1 |
| Директор по маркетингу | 1 |
Наш запрос GROUP BY вернул список уникальных титулов, которыми владеют сотрудники. Рядом с каждым титулом мы можем увидеть количество сотрудников, имеющих это звание.
Когда следует использовать GROUP BY в SQL?
Предложение GROUP BY необходимо только тогда, когда вы хотите получить больше информации, чем-то, что возвращает агрегатная функция. Мы обсуждали это чуть раньше.
Если вы хотите узнать количество ваших клиентов, вам нужно всего лишь выполнить обычный запрос. Вот пример запроса, который вернёт эту информацию:
Наш запрос группирует результат и возвращает:
Если вы хотите узнать, сколько клиентов входит в каждый из ваших планов лояльности, вам нужно будет использовать оператор GROUP BY. Вот пример запроса, который может получить список планов лояльности и количество клиентов по каждому плану:
SELECT loyalty_plan, COUNT(loyalty_plan)
FROM customers
GROUP BY loyalty_plan;
Наш запрос собирает данные. Затем наш запрос возвращает:
SQL Group By по нескольким столбцам
Если бы мы хотели, мы могли бы выполнить GROUP BY для нескольких столбцов. Например, предположим, что мы хотели получить список сотрудников с определёнными должностями в каждом филиале. Мы могли бы получить эти данные, используя следующий запрос:
SELECT branch, title, COUNT(title)
FROM employees
GROUP BY branch, title;
Наш набор результатов запроса показывает:
| ответвляться | заглавие | считать |
| Стэмфорд | Сотрудник по продажам | 1 |
| Олбани | Вице-президент по продажам | 1 |
| Сан-Франциско | Сотрудник по продажам | 1 |
| Сан-Франциско | Старший специалист по продажам | 1 |
| Олбани | Директор по маркетингу | 1 |
| Бостон | Сотрудник по продажам | 2 |
Наш запрос создаёт список титулов, которыми владеет каждый сотрудник. Мы видим количество людей, обладающих этим титулом. Наши данные сгруппированы по отраслям, в которых работает каждый сотрудник, и их должностям.
Вывод
Предложение SQL GROUP BY необходимо в любом операторе, где используется агрегатная функция и запрашивается дополнительная таблица. Вы должны сгруппировать по столбцу, не упомянутому в агрегатной функции.
Вы ищете вызов? Напишите выписку, в которой узнайте, сколько сотрудников работает в каждом филиале.
Таблица называется «сотрудники», а столбец, в котором хранятся названия веток, называется «ветвь». Вернитесь к руководству выше и посмотрите, имеет ли ваш запрос смысл, исходя из того, что мы обсуждали.
Руководство по предложению GROUP BY в SQL
Перевод статьи « SQL Group By Tutorial: Count, Sum, Average, and Having Clauses Explained».

Предложение GROUP BY это очень мощный параметр, но и непростой. Даже спустя восемь лет его использования я все еще каждый раз задумываюсь, что, собственно, я делаю.
Мы рассмотрим следующие темы:
Подготовительный этап с описанием программного обеспечения и созданием базы данных мы рассматривали в двух предыдущих статьях:
Эти разделы совершенно идентичны, так что можете почитать в любой из двух статей.
Создание таблицы с данными
Для нашего примера мы создадим таблицу, в которой будут храниться записи о продажах различных продуктов в разных точках.
Давайте создадим нашу таблицу и внесем в нее кое-какие данные о продажах:
У нас были продажи сегодня, вчера и позавчера.
Как работает GROUP BY?
Представьте, что у нас есть комната, в которой находится много людей. Эти люди родились в разных странах.
Если мы хотим найти средний рост людей, находящихся в этой комнате, в разрезе по странам, мы сначала попросим их разделиться на группы по стране рождения.
Когда люди сгруппируются по месту рождения, мы сможем высчитать средний рост в каждой группе.
Множественные группы
Мы можем группировать данные в любое количество групп и подгрупп.
Например, когда люди разделились по странам, мы можем попросить их в каждой группе разделиться на подгруппы по цвету глаз.
Таким образом мы получим группы людей, родившихся в одной стране и имеющих одинаковый цвет глаз.
После этого мы можем высчитать средний рост в каждой такой маленькой группе и получить более специфический результат. Например, средний рост голубоглазых людей, родившихся во Франции.
Предложения GROUP BY часто используются в случаях, когда можно использовать обороты по чему-то или в каждом(ой):
Написание предложений GROUP BY
Предложение GROUP BY пишется очень просто. Мы используем ключевые слова GROUP BY и указываем поля, по которым должна происходить группировка:
Очевидно, что нам нужно сделать выборку локации. Мы группируем данные по этому столбцу и как минимум хотим увидеть имена созданных групп:
Результатом будут три наши локации:
А как насчет остальных столбцов таблицы?
мы получим вот такую ошибку:
Проблема в том, что мы взяли восемь строк и попытались втиснуть их в три.
Мы не можем просто возвращать оставшиеся столбцы, как обычно, потому что раньше у нас было восемь строк, а теперь их только три.
Что делать с оставшимися пятью строками данных? Какие данные из восьми строк должны быть отображены в трех строках?
На эти вопросы нет четкого и ясного ответа.
Чтобы использовать остальные данные таблицы, мы должны выделить данные из оставшихся столбцов в наши три локационные группы.
Это означает, что мы должны агрегировать эти данные или осуществить какие-то вычисления, чтобы получить некую итоговую информацию об оставшихся данных.
Агрегатные функции (COUNT, SUM, AVG)
Если мы решили сгруппировать данные, мы можем агрегировать данные оставшихся столбцов. например, мы можем посчитать число строк в каждой группе, суммировать отдельные значения в группе или вывести некое среднее значение (тоже по группе).
Для начала давайте найдем количество продаж по каждой локации.
Поскольку каждая запись в таблице sales это запись об одной продаже, число продаж по локации будет равно числу строк в каждой группе (при группировке по локациям).
Чтобы получить нужный результат, нам нужно применить агрегатную функцию COUNT() — так мы вычислим количество строк в каждой группе.
( COUNT() также работает с выражениями, но при этом имеет несколько другое поведение).
Вот как база данный выполняет наш запрос:
Локация 1st Street имеет две продажи, HQ — четыре, а Downtown — две.
Как видно, здесь мы взяли данные столбца, по которому не делали группировку, и из восьми отдельных строк вычленили полезную итоговую информацию по каждой локации, а именно — число продаж.
Вместо подсчета числа строк в группе мы могли бы суммировать информацию по группе. Например, получить общее количество вырученных денег по каждой локации.
Для этого мы будем использовать функцию SUM() :
Вместо подсчета числа строк в каждой группе мы сложили количество долларов, полученных в результате каждой продажи, и вывели общий доход по локациям:
Функция AVG() позволяет находить среднее значение (AVG от Average — среднее). Давайте найдем среднюю сумму выручки по локациям. Для этого просто заменим функцию SUM() на функцию AVG() :
Работа с несколькими группами
Пока что мы работали с одной группировкой — по локациям. Что, если нам нужно разбить полученные группы на подгруппы?
Для этого нам нужно добавить к нашему предложению GROUP BY второе группирующее условие:
(Для облегчения чтения я добавил в запрос также предложения ORDER BY ).
В результатах нашего нового группирования мы видим уникальные комбинации локаций и продуктов:
Ну хорошо, у нас есть наши группы, а что мы будем делать с данными остальных столбцов?
Мы можем найти число продаж определенного продукта в каждой локации, используя все те же агрегатные функции:
(Задание «со звездочкой»: найдите общую выручку (сумму) за каждый продукт в каждой локации).

Использование функций в GROUP BY
Давайте попытаемся найти общее число продаж в день.
мы можем ожидать, что каждая группа будет уникальным днем, но вместо этого видим следующее:
Похоже, наши данные вообще не сгруппировались: мы получили каждую строку отдельно.
Но на самом деле наши данные сгруппированы! Проблема в том, что sold_at каждой строки является уникальным значением, поэтому каждая строка образует собственную группу!
GROUP BY работает правильно, однако это не тот результат, который нам нужен.
Виной всему уникальная информация временной метки (часы/минуты/секунды).
Все эти временные метки разные, поэтому записи разбрасываются по разным группам.
Нам нужно конвертировать значения даты и времени для каждой записи в просто дату:
После этого все записи о продажах, сделанных в один день, будут иметь одинаковое значение даты и, следовательно, попадут в одну группу.
Для этого мы сведем значение временной метки sold_at к дате:
В запросе SELECT мы возвращаем то же выражение и даем ему псевдоним для более красивого вывода.
Вот результат числа продаж за день, который мы хотели увидеть:
Фильтрация групп при помощи HAVING
Давайте теперь разберем, как можно фильтровать наши сгруппированные строки. Например, попробуем найти дни, в которые у нас было больше одной продажи.
Имея группы, мы можем попробовать отфильтровать наши группы по числу строк…
К сожалению, это не сработало и мы получили ошибку:
Это предложение HAVING отфильтровывает все строки, если число строк в группе не больше одной. Вот результат:
Чисто для полноты картины вот вам порядок выполнения всех предложений SQL:
Агрегации со скрытым группированием
Последняя тема, которую мы затронем, это агрегации без GROUP BY или, если выражаться более точно, агрегации со скрытым группированием.
Эти агрегации полезны в сценариях, где вы хотите найти одну конкретную агрегацию из таблицы. Например, общую выручку или наибольшее/наименьшее значение столбца.
Мы могли бы найти общую выручку по всем локациям, просто выбрав сумму по всей таблице:
Еще один полезный сценарий — запросить первое или последнее что-нибудь.
Например, дату самой первой продажи.
Чтобы ее найти, мы моем применить функцию MIN() :
(Для поиска даты последней продажи нужно всего лишь заменить MIN() на MAX() ).
Использование MIN / MAX
Хотя эти простые запросы могут быть полезны сами по себе, они часто являются составляющими более длинных запросов.
Например, давайте попробуем найти общую выручку в последний день, когда у нас вообще были продажи.
Мы можем написать запрос так:
Этот запрос сработает, но мы захардкодили дату 2020-09-01. А ведь дата последней продажи будет постоянно меняться. Нам нужно динамическое решение.
Для этого нам нужно скомбинировать этот