Зачем нужны связи между таблицами в Power BI
О продвинутых техниках в Power BI есть много статей. Однако об основах работы с этим инструментом информации гораздо меньше. Закрываем эти пробелы.



Руководитель отдела маркетинга интерактивного агентства «Космос-Веб».
Аналитик-визуализатор. Любит маму, гардемаринов и BI-системы, сторонник автоматизации процессов. Адепт систематизации и структуризации — иногда пугает неокрепшие души словами Agile и Scrum.
Опираясь на подробный разбор зарубежного портала RADACAD Blog и дополнив его собственным опытом, я хочу рассказать о о связях (Relationships) между таблицами. Мы выясним, что такое связи, зачем они нужны и как с ними работать.
Что такое связи в Power BI?
Давайте рассмотрим на примере. Предположим, у нас есть таблица с информацией о магазинах, и мы хотим проанализировать ее в Power BI. Таблица выглядит следующим образом:

Если в отчете построить визуализацию по количеству магазинов и сделать разбивку по географии, то получится следующее:
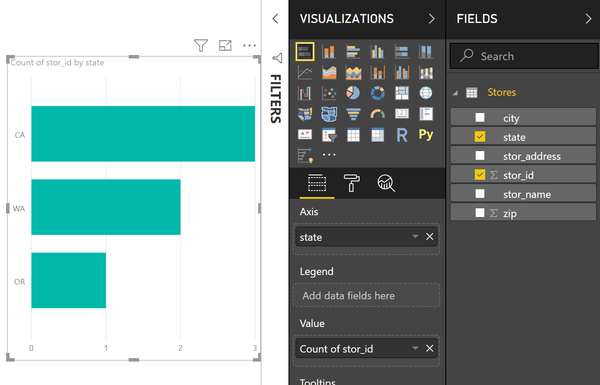
Как видим, данный отчет фильтрует таблицу и наглядно отображает количество записей для каждого штата. Вот визуализация этого фильтра в таблице:

А что, если у меня больше одной таблицы?
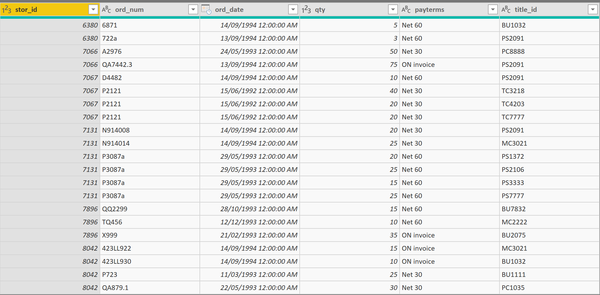
Что ж, давайте посмотрим, что будет в этом случае. Предположим, что у нас еще есть таблица с данными по продажам для каждого из магазинов. Таблица содержит следующие столбцы:
Чтобы изучить, как работают связи, я рекомендую вам отключить (на время!) автоопределение связей в Power BI. Делается это следующим образом (я обычно использую англоязычную версию, поэтому скрины все будут на английском):
Если мы загрузим обе таблицы, то увидим такую картину:
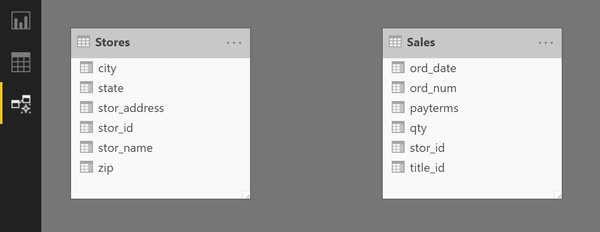
Между таблицами нет никаких связей. Теперь, если мы захотим отфильтровать и узнать общее количество книг, проданных в том или ином магазине, то сможем сделать это с помощью визуализации:
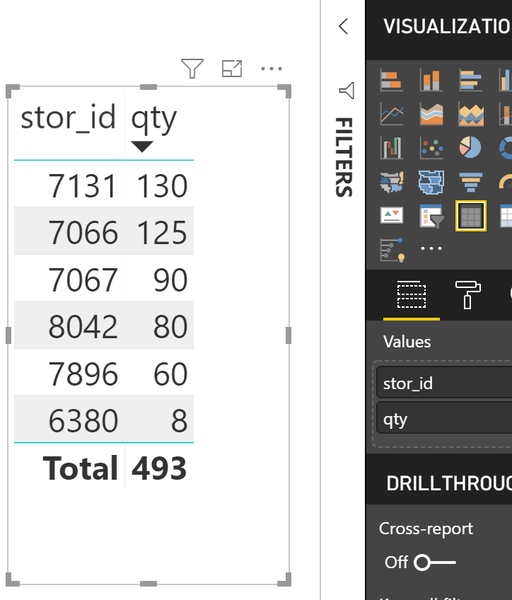
Данный отчет похож на предыдущий, и если теперь раскрасить нашу таблицу с учетом фильтра, то получим:
Построим визуализацию по продажам в каждом из штатов:
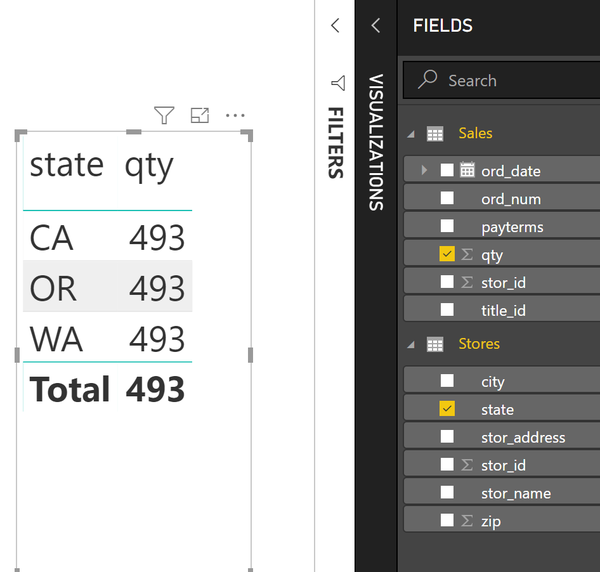
Наблюдаем странную картину: в каждом штате продано по 493 книги. Кажется, что-то пошло не так. Фильтр не работает так, как должен. Произошло это потому, что в таблице по продажам нет информации по штату, но есть ID магазина.
При этом в самой таблице по магазинам нет информации о проданных товарах и их количестве. Но чтобы составить полноценный отчет, нам нужны обе таблицы.
Общим полем для обеих таблиц является поле stor_id, по которому мы и можем сопоставить информацию о наших филиалах и продажах в каждом из них.

Давайте рассмотрим пример:

В другой таблице мы видим количество продаж в магазине с ID, равным 7066.
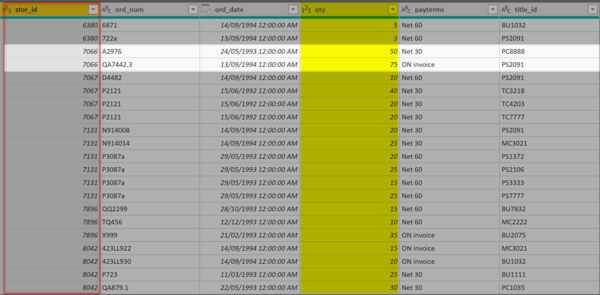
Таким образом получается, что мы можем связать обе таблицы с помощью столбца stor_id.
Связи (Relationships)
Если вы хотите запросить данные сразу из двух таблиц и эти данные должны быть связаны между собой, то нужно создать связь между таблицами через какое-либо общее поле (если эти таблицы не связаны через другие таблицы). Для этого в окне редактирования связей надо просто наложить поле из одной таблицы в другую (при этом у них могут быть разные названия).
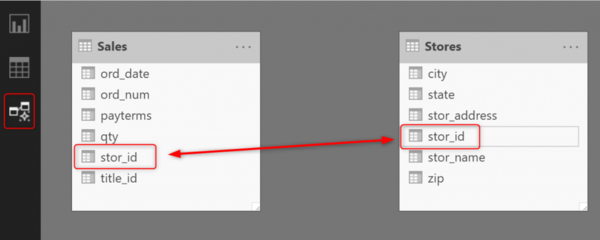
После этого действия должна появиться линия между обеими таблицами. Она означает связь между ними.
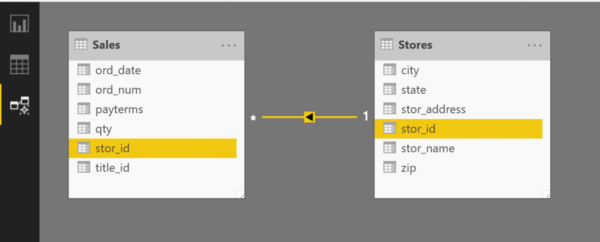
Разные названия
Как я уже написал, оба столбца могут иметь одинаковые имена, что и позволяет системе автоматически обнаруживать связи между таблицами. Ранее мы отключили данную функцию, чтобы сделать процесс нагляднее. По умолчанию в Power BI данная опция включена, и связь между таблицами по полю stor_id построилась бы без вашего участия.
Связи между таблицами в модели данных

Чтобы сделать анализ данных более емким, создайте связи в разных таблицах. Связь — это соединение между двумя таблицами, которые содержат данные: один столбец в каждой таблице является основой для связи. Чтобы понять, чем полезны связи, представим, что отслеживаются данные для заказов клиентов в бизнесе. Вы можете отслеживать все данные в одной таблице с такой структурой:
Однообъективный зеркальный фотоаппарат
Этот подход может быть эффективным, но он подразумевает хранение множества избыточных данных, таких, как адрес электронной почты клиента для каждого заказа. Хранение данных обходится дешево, но если адрес электронной почты изменился, необходимо убедиться, чтоб была обновлена каждая строка для этого клиента. Одним из решений этой проблемы является разбиение данных на несколько таблиц и задание связей между этими таблицами. Этот подход используется в реляционных базах данных таких, как SQL Server. Например, импортированная база данных может представлять данные заказа, используя три связанные таблицы.
Однообъективный зеркальный фотоаппарат
Связи существуют в модели данных ( та, которую вы создали явным образом или которая Excel автоматически создается от вашего имени при одновременном импорте нескольких таблиц. Кроме того, вы можете воспользоваться надстройкой Power Pivot для создания модели и управления ею. Дополнительные сведения см. в статье Создание модели данных в Excel.
Во время импорта таблицы из одной базы данных с помощью надстройки Power PivotPower Pivot может обнаруживать связи между таблицами, основанными на столбцах, заключенных в [квадратные скобки], и воспроизводить эти связи в модели данных, создаваемой в фоновом режиме. Дополнительные сведения см. в разделе Автоматическое обнаружение и вывод связей этой статьи. Если таблицы импортируются из нескольких источников, можно вручную создать связи, как это описано в статье Создание связей между двумя таблицами.
Связи основываются на столбцах в каждой таблице, содержащих одинаковые данные. Например, можно связать таблицу «Клиенты» с таблицей «Заказы», если каждая из них содержит столбец с ИД клиента. В данном примере имена столбцов одинаковы, но это не является обязательным условием. Один столбец может называться CustomerID, а другой — CustomerNumber, при условии, что все строки в таблице Orders содержат идентификатор, который также хранится в таблице Customers.
В реляционной базе данных существует несколько типов ключей. Ключ обычно является столбцом со специальными свойствами. Знание назначения каждого ключа помогает в управлении моделью данных с несколькими таблицами, предоставляющей данные для сводной таблицы, сводной диаграммы или отчета Power View.
Хотя существует множество типов ключей, они являются самыми важными в нашем предназначении:
Первичный ключ: однозначно определяет строку в таблице, например CustomerID в таблице Customers.
Альтернативный ключ (или первичный ключ): уникальный столбец, который не является первичным ключом. Например, таблица Employees может хранить идентификатор работника и номер карточки социального страхования, при том что оба они являются уникальными.
Внешнее ключ: столбец, который ссылается на уникальный столбец другой таблицы, например CustomerID в таблице Orders, который ссылается на CustomerID в таблице Customers.
В модели данных первичный или резервный ключ называется связанным столбцом. Если таблица содержит первичный и резервный ключ, любой из них можно использовать как основу для связи между таблицами. Внешний ключ называется исходным столбцом или просто столбцом. В нашем примере связь между customerID в таблице Orders (столбцом) и CustomerID в таблице Customers (столбцом подытов) будет определена. Если данные импортируются из реляционной базы данных, по умолчанию Excel выбирает внешний ключ из одной таблицы и соответствующий первичный ключ из другой таблицы. Тем не менее для столбца подстановки можно использовать любой столбец, содержащий уникальные значения.
Связь между клиентом и заказом является связью «один-к-многим». Каждый клиент может иметь несколько заказов, однако ни один из заказов не может иметь несколько клиентов. Еще одна важная связь между таблицами — «один к одному». В нашем примере таблица CustomerDiscounts, которая определяет единую ставку дисконтирования для каждого клиента, имеет отношение «один-к-одному» с таблицей Customers.
В этой таблице показаны связи между тремя таблицами (Customers, CustomerDiscountsи Orders):
Примечание: Связи «многие ко многим» не поддерживаются в модели данных. Примером связи «многие ко многим» является прямая связь между таблицами Products и Customers, в которой заказчик может купить много продуктов и одинаковый продукт может быть одновременно куплен несколькими заказчиками.
После создания связи необходимо Excel пересчет всех формул, которые используют столбцы из таблиц в созданной связи. Обработка может занять некоторое время в зависимости от объема данных и сложности связей. Дополнительные сведения см. в теме Пересчет формул.
Модель данных может содержать несколько связей между двумя таблицами. Для точного вычисления Excel требуется один путь от одной таблицы к другой. Поэтому одновременно активной может быть только одна связь между каждой парой таблиц. Хотя другие неактивны, вы можете указать неактивное отношение в формулах и запросах.
В представлении диаграммы активная связь является сплошной линией, а неактивные — пунктирными линиями. Например, в таблице AdventureWorksDW2012 таблица DimDate содержит столбец DateKey, связанный с тремя разными столбцами в таблице FactInternetSales: OrderDate, DueDateи ShipDate. Если есть активная связь между столбцами DateKey и OrderDate, эта связь и будет использоваться по умолчанию в формулах, если не указано иное.
Связь можно создать, если выполняются следующие требования.
Уникальный идентификатор для каждой таблицы
Каждая таблица должна иметь один столбец, однозначно определяющий каждую строку в этой таблице. Такой столбец часто именуется первичным ключом.
Уникальные столбцы подстановки
Значения данных в столбце подстановки должны быть уникальными. Другими словами, столбец не может содержать дубликаты. В модели данных нули и пустые строки эквивалентны пустому полю, которое является самостоятельным значением данных. Это значит, что столбец подстановки не может содержать несколько значений NULL.
Совместимые типы данных
Типы данных в исходном столбце и в столбце подстановки должны быть совместимыми. Дополнительные сведения о типах данных см. в теме Типы данных, поддерживаемые в моделях данных.
В модели данных нельзя создать связь между таблицами, если ключ является составным. Также существует ограничение на создание связей «один к одному» и «один ко многим». Другие типы связей не поддерживаются.
Составные ключи и столбцы подстановки
Составной ключ состоит из нескольких столбцов. Модели данных не могут использовать составные ключи: таблица должна всегда иметь ровно один столбец, однозначно определяя каждую строку в таблице. При импорте таблиц, имеющих существующую связь на основе составного ключа, мастер импорта таблиц в Power Pivot не будет учитывать эту связь, так как ее нельзя создать в модели.
Для создания связи между двумя таблицами, имеющими несколько столбцов, в которых определены первичный и внешние ключи, сначала объедините значения для создания единого ключевого столбца. Это можно сделать перед импортом данных или путем создания вычисляемого столбца в модели данных с помощью надстройки Power Pivot.
Связи «многие ко многим»
Самосоединения и циклы
В модели данных не разрешается использование самосоединений. Самосоединение — это рекурсивная связь таблицы с самой собой. Самосоединения часто используются для определения иерархий типа «родители-потомки». Например, можно настроить самосоединение для таблицы Employees, чтобы создать иерархию, показывающую цепочку управления на предприятии.
Excel не позволяет создавать циклы среди связей в книге. Иными словами, следующий набор связей запрещается.
Таблица 1, столбец «а» к Таблице 2, столбец «f»
Tаблица 2, столбец «f» к Таблице 3, столбец «n».
Таблица 3, столбец «n» к Таблице 1, столбец «a».
При попытке создания связи, которая приведет к образованию цикла, выдается ошибка.
Одно из преимуществ импорта данных с помощью надстройки Power Pivot заключается в том, что Power Pivot иногда может обнаруживать связи и создавать новые связи в модели данных, создаваемой в Excel.
При импорте нескольких таблиц Power Pivot автоматически определяет все существующие связи между ними. Кроме того, при создании сводной таблицы Power Pivot анализирует данные в таблицах. Он обнаруживает возможные связи, которые не были определены, и предлагает столбцы, которые можно включить в них.
Алгоритм обнаружения на основании статистических данных о значениях и метаданных столбцов формирует выводы о вероятности связей.
Типы данных во всех связанных столбцах должны быть совместимыми. Для автоматического обнаружения поддерживаются только целочисленные и текстовые типы данных. Дополнительные сведения о типах данных см. в разделе Типы данных, поддерживаемые вмоделях данных.
Для успешного обнаружения связи количество уникальных ключей в столбце подстановки должно превышать количество значений в таблице на стороне «многие». Другими словами, ключевой столбец на стороне «многие» связи не должен содержать значений, не содержащихся в ключевом столбце таблицы подстановки. Например, предположим, что имеется таблица, в которой перечислены продукты и их идентификаторы (таблица подстановки), а также таблица продаж, содержащая данные продаж всех продуктов (сторона «многие» связи). Если записи продаж содержат идентификатор продукта, не имеющего соответствующий идентификатор в таблице Products, связь нельзя создать автоматически, но можно создать вручную. Для обеспечения обнаружения связи с помощью Excel необходимо сначала обновить таблицу подстановки Product с использованием идентификаторов недостающих продуктов.
Убедитесь, что имя ключевого столбца на стороне «многие» совпадает с именем ключевого столбца в таблице подстановки. Имена не должны быть абсолютно идентичны. Например, в бизнес-параметрах часто имеются варианты имен столбцов, которые содержат фактически одинаковые данные: «ИД сотрудника», «ИД сотрудника», «ИД сотрудника», «EMP_ID»и так далее. Алгоритм выявляет похожие имена и задает более высокие значения вероятности столбцам, имена которых похожи или полностью совпадают. Поэтому, чтобы увеличить вероятность создания связи, можно попытаться переименовать столбцы в импортируемых данных, подобрав имена чем-то похожие на имена строк в существующих таблицах. Если Excel находит несколько возможных связей, связь не создается.
Эти сведения помогают понять, почему не удалось выявить все связи и какие изменения в метаданных (именах полей и типах данных) могут повысить эффективность автоматического обнаружения связей. Дополнительные сведения см. в разделе Устранение неполадок в связях.
Автоматическое обнаружение именованных наборов
Связи между именованными наборами и связанными полями в сводной таблице не обнаруживаются автоматически. Такие связи можно создать вручную. При необходимости использования автоматического обнаружения связей удалите каждый именованный набор и добавьте отдельные поля из именованного набора непосредственно в сводную таблицу.
В некоторых случаях связи между таблицами автоматически объединяются в цепочки. Например, если создать связь между первыми двумя наборами таблиц, указанных ниже, то определяется наличие связи между другими двумя таблицами и эта связь устанавливается автоматически.
Products и Category — связь создается вручную
Category и SubCategory — связь создается вручную
Products и SubCategory — связь определяется автоматически
Для автоматического объединения связей в цепочки эти связи должны идти в одном направлении, как показано выше. Если исходные связи были установлены, например между таблицами Sales и Products, а также между Sales и Customers, то связь не выводится. Это вызвано тем, что связь между таблицами Products и Customers является связью «многие ко многим».
Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Часть 3.2: Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Продолжаем изучать теорию реляционных баз данных и в этой части мы познакомимся с видами и типами связей между таблицами в реляционных базах данных. Так же мы познакомимся с такими термина, как: кортеж, атрибут и отношения. Данная тема является базовой и ее понимание необходимо для работы с базами данных и для их проектирования.

Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты.
Сразу скажу, что связей между таблицами в реляционной базе данных всего три. Поэтому их изучение, понимание и восприятие пройдет быстро, легко и безболезненно. Приступим к изучению.
Термины кортеж, атрибут и отношение в реляционных базах данных
В своей публикации я буду стараться объяснять теорию баз данных не с математической точки зрения, а на примерах. Грубо говоря, на пальцах. Во-первых, практические примеры позволяют легче усваивать материал. Во-вторых, с математической теорией проще разобраться, когда понимаешь суть происходящего.
Давайте разбираться с тем, что такое: отношение, кортеж, атрибут в реляционной базе данных.
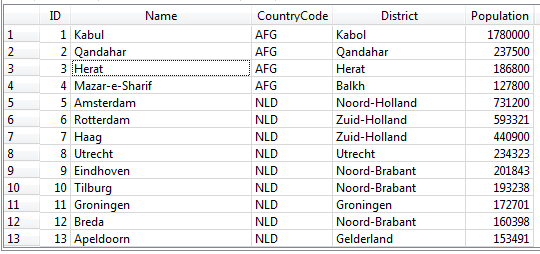
Таблица с данными из базы данных World
У нас есть простая таблица City из базы данных World, в которой есть строки и столбцы. Но термины: таблица, строка, столбец – это термины стандарта SQL.
Кстати: ни одна из существующих в мире СУБД не имеет полной поддержки того или иного стандарта SQL, но и ни один стандарт SQL полностью не реализует математику реляционных баз данных.
В терминологии реляционных баз данных: таблица – это отношение (принимается такое допущение), строка – это кортеж, а столбец – атрибут. Иногда вы можете услышать, как некоторые разработчики называют строки записями. Чтобы не было путаницы в дальнейшем предлагаю использовать термины SQL.
Если рассматривать таблицу, как объект (например книга), то столбец – это характеристики объекта, а строки содержат информацию об объекте.
Виды и типы связей между таблицами в реляционных базах данных
Давайте теперь рассмотрим то, как могут быть связаны таблицы в реляционных базах данных. Сразу скажу, что всего существует три вида связей между таблицами баз данных:
• связь один к одному;
• связь один ко многим;
• связь многие ко многим.
Рассмотрим, как такие связи между таблицами могут быть реализованы в реляционных базах данных.
Реализация связи один ко многим в теории баз данных
Связь один ко многим в реляционных базах данных реализуется тогда, когда объекту А может принадлежать или же соответствовать несколько объектов Б, но объекту Б может соответствовать только один объект А. Не совсем понятно, поэтому смотрим пример ниже.
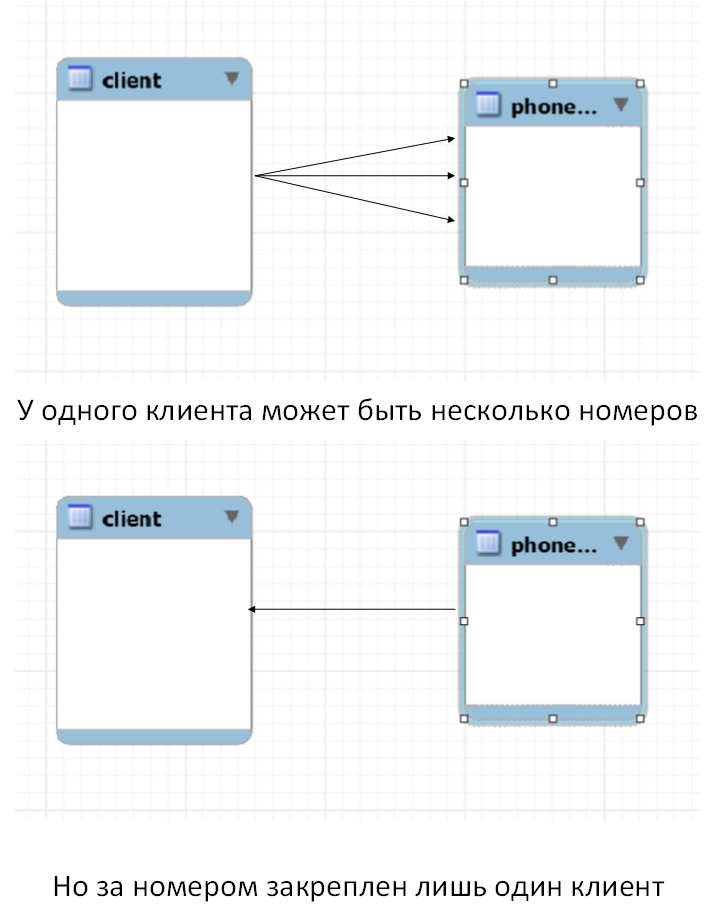
Реализация связи один ко многим в реляционных базах данных
У нас есть таблица, в которой содержатся данные о клиентах и у нас есть таблица, в которой хранятся их телефоны. Мы можем смело утверждать, что у одного клиента может быть несколько телефонов, но в тоже время мы можем быть уверены в том, что один конкретный номер может быть только у одного клиента. Это типичный пример связи один ко многим.
Связь многие ко многим
Связь многие ко многим реализуется в том случае, когда нескольким объектам из таблицы А может соответствовать несколько объектов из таблицы Б, и в тоже время нескольким объектам из таблицы Б соответствует несколько объектов из таблицы А. Рассмотрим простой пример.
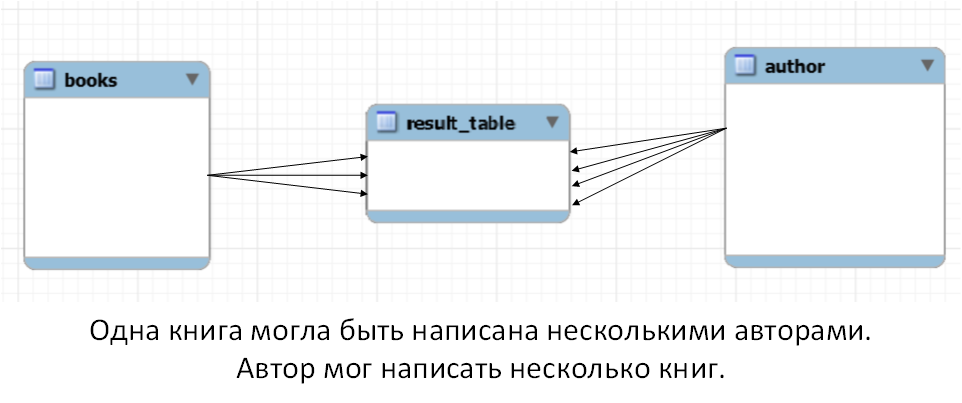
Пример связи многие ко многим
У нас есть таблица с книгами и есть таблица с авторами. Приведу два верных утверждения. Первое: одну книгу может написать несколько авторов. Второе: автор может написать несколько книг. Здесь мы наблюдаем типичную ситуацию, когда связь между таблицами многие ко многим. Такая связь (связь многие ко многим) реализуется путем добавления третьей таблицы.
Связь один к одному
Связь один к одному – самая редко встречаемая связь между таблицами. В 97 случаях из 100, если вы видите такую связь, вам необходимо объединить две таблицы в одну.
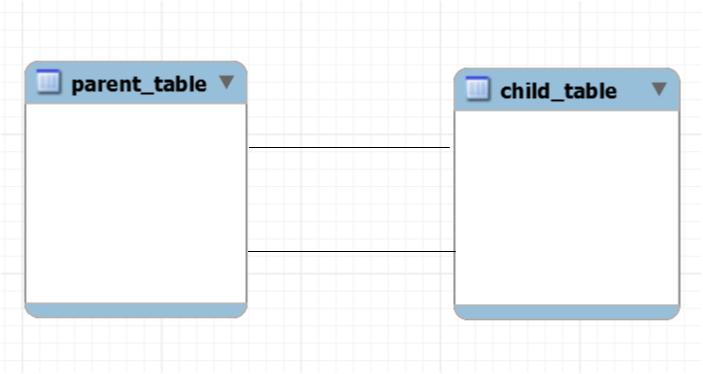
Пример связи один к одному
Таблицы будут связаны один к одному тогда, когда одному объекту таблицы А соответствует один объект таблицы Б, и одному объекту таблицы Б соответствует один объект таблицы А. Как я уже говорил: если вы видите, что связь один к одному – смело объединяйте таблицы в одну, за исключением тех случаев, когда происходит модернизация базы данных.
Например, у нас была таблица, в которой хранились данные о сотрудниках компании. Но произошли какие-то изменения в бизнес-процессе и появилась необходимость создать таблицы с теми же самыми сотрудниками, но не для всей компании, а разбив их по отделам. Таблицы отделов будут дочерними по отношению к таблице, в которой хранятся данные обо всех сотрудниках компании, и связаны такие таблицы будут связью один к одному.
Мы рассмотрели все виды связей между таблицами и то, как они реализуются в базах данных. В дальнейшем, когда мы начнем создавать свои базы данных, информация о видах связи между таблицами нам очень поможет.



