Python RegEx: практическое применение регулярок
Авторизуйтесь
Python RegEx: практическое применение регулярок
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
Основы регулярных выражений
Регулярками называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
Для чего используются регулярные выражения
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
Регулярные выражения в Python
А вот наиболее популярные методы, которые предоставляет модуль:
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
Теперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None :
Также есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
re.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки \n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра 6 (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
| [..] | Один из символов в скобках ([^..] — любой символ, кроме тех, что в скобках) |
| \ | Экранирование специальных символов (\. означает точку или \+ — знак «плюс») |
| ^ и $ | Начало и конец строки соответственно |
| От n до m вхождений ( — от 0 до m) | |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Теперь попробуем достать каждое слово (используя * или + )
И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем + :
Теперь вытащим первое слово, используя ^ :
Вернуть первые два символа каждого слова
Вариант 2: вытащить два последовательных символа, используя символ границы слова ( \b ):
Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ) :
Извлечь дату из строки
Используем \d для извлечения цифр.
Для извлечения только года нам опять помогут скобки:
Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
А теперь — только те, которые начинаются на определенные буквы (используя [] ):
Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем \b для обозначения границы слова:
Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
Разбить строку по нескольким разделителям
Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
Извлечь информацию из html-файла
Пример содержимого html-файла:
С помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str ):
Синтаксис регулярных выражений в Python.
Поведение и применение символов регулярных выражений.
Синтаксис регулярных выражений в Python немного отличается от синтаксиса регулярных выражений в языке программирования PERL.
Содержание:
Специальные символы:
Специальный символ '^' соответствует началу строки, а при включенном флаге re.MULTILINE также соответствует положению сразу после каждой новой строки.
Если не использовать необработанную строку r'' в написании шаблона регулярного выражения, то необходимо помнить, что Python также использует обратную косую черту в качестве escape-последовательности в строковых литералах. Если escape-последовательность не распознается синтаксическим анализатором Python, обратная косая черта и последующий символ включаются в полученную строку. Если Python распознает полученную последовательность, обратный слеш должен повторяться дважды. Это сложно и трудно понять, поэтому настоятельно рекомендуется использовать необработанные строки r'' для всех, кроме самых простых регулярных выражений.
Конструкция '[]' используется для обозначения символьного класса:
Расширения регулярных выражений:
- '(?aiLmsux)'
- '(?aiLmsux-imsx. )'
- '(?P=name)'
Конструкция '(?#. )' обозначает комментарий. Содержимое скобок просто игнорируется.
Этот пример ищет слово после дефиса:
- '(?(id/name)yes-pattern|no-pattern)'
Специальные последовательности:
- '\number'
Специальная последовательность '\A' совпадает только с положением начала строки.
Для шаблонов байтовых строк: специальная последовательность '\d' соответствует любой десятичной цифре, эквивалентно символьному классу 8.
Специальная последовательность '\Z' совпадает только с положением конца строки.
Большинство стандартных экранирований, поддерживаемых строковыми литералами Python, также принимаются анализатором регулярных выражений:
Обратите внимание, что \b используется для представления границ слов и означает "возврат" только внутри классов символов.
Регулярные выражения в Python
Перевод статьи «Python Regular Expression».
Обычное использование регулярного выражения:
Основы
Регулярное выражение – это комбинация символов и метасимволов. Из метасимволов доступны следующие:
re.search()
Этот метод возвращает совпадающую часть строки и останавливается сразу же, как находит первое совпадение. Таким образом, его можно использовать для проверки выражения, а не для извлечения данных.
Синтаксис: re.search(шаблон, строка)
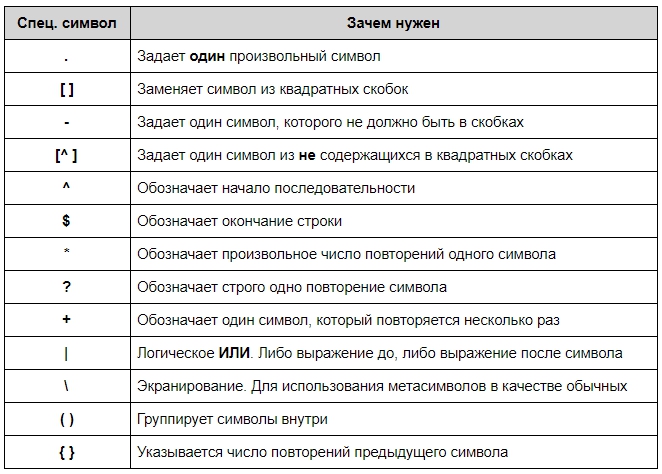
Давайте разберем пример: поищем в строке месяц и число.
re.match()
Этот метод ищет и возвращает первое совпадение. Но надо учесть, что он проверяет соответствие только в начале строки.
Синтаксис: re.match(шаблон, строка)
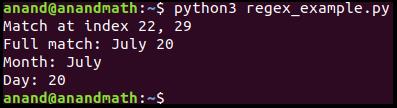
Теперь давайте посмотрим на пример. Проверим, совпадает ли строка с шаблоном.
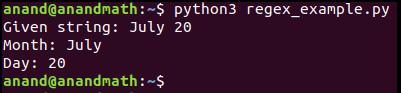
Рассмотрим другой пример. Здесь «July 20» находится не в начале строки, поэтому результатом кода будет «Not a valid date»

re.findall()
Этот метод возвращает все совпадения с шаблоном, которые встречаются в строке. При этом строка проверяется от начала до конца. Совпадения возвращаются в том порядке, в котором они идут в исходной строке.
Синтаксис: re.findall(шаблон, строка)
Возвращаемое значение может быть либо списком строк, совпавших с шаблоном, либо пустым списком, если совпадений не нашлось.
Рассмотрим пример. Используем регулярное выражение для поиска чисел в исходной строке.

Или другой пример. Теперь нам нужно найти в заданном тексте номер мобильного телефона. То есть, в данном случае, нам нужно десятизначное число.

re.compile()
С помощью этого метода регулярные выражения компилируются в объекты шаблона и могут использоваться в других методах. Рассмотрим это на примере поиска совпадений с шаблоном.
re.split()
Данный метод разделяет строку по заданному шаблону. Если шаблон найден, оставшиеся символы из строки возвращаются в виде результирующего списка. Более того, мы можем указать максимальное количество разделений для нашей строки.
Синтаксис: re.split(шаблон, строка, maxsplit = 0)
Возвращаемое значение может быть либо списком строк, на которые была разделена исходная строка, либо пустым списком, если совпадений с шаблоном не нашлось.
Рассмотрим, как работает данный метод, на примере.
re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Синтаксис: re.sub(шаблон, repl, строка, count = 0, flags = 0)
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
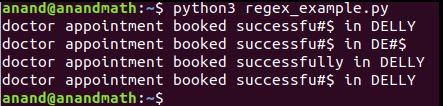
re.subn()
Синтаксис: re.subn(шаблон, repl, строка, count = 0, flags = 0)
Рассмотрим такой пример.
re.escape()
Этот метод возвращает строку с обратной косой чертой \ перед каждым не буквенно-числовым символом. Это полезно, если мы хотим сопоставить произвольную буквенную строку, которая может содержать метасимволы регулярного выражения.
Чтобы лучше понять принцип работы метода, рассмотрим следующий пример.

Заключение
Сегодня мы поговорили о регулярных выражениях в Python и о том, что необходимо для их понимания в любом приложении. Мы изучили различные методы и метасимволы, присутствующие в регулярных выражениях Python, на примерах.
Регулярные выражения в Python от простого к сложному. Подробности, примеры, картинки, упражнения

Решил я давеча моим школьникам дать задачек на регулярные выражения для изучения. А к задачкам нужна какая-нибудь теория. И стал я искать хорошие тексты на русском. Пяток сносных нашёл, но всё не то. Что-то смято, что-то упущено. У этих текстов был не только фатальный недостаток. Мало картинок, мало примеров. И почти нет разумных задач. Ну неужели поиск IP-адреса — это самая частая задача для регулярных выражений? Вот и я думаю, что нет.
Про разницу (. ) / (. ) фиг найдёшь, а без этого знания в некоторых случаях можно только страдать.
Плюс в питоне есть немало регулярных плюшек. Например, re.split может добавлять тот кусок текста, по которому был разрез, в список частей. А в re.sub можно вместо шаблона для замены передать функцию. Это — реальные вещи, которые прямо очень нужны, но никто про это не пишет.
Так и родился этот достаточно многобуквенный материал с подробностями, тонкостями, картинками и задачами.
Надеюсь, вам удастся из него извлечь что-нибудь новое и полезное, даже если вы уже в ладах с регулярками.
PS. Решения задач школьники сдают в тестирующую систему, поэтому задачи оформлены в несколько формальном виде.
Содержание
Регулярное выражение — это строка, задающая шаблон поиска подстрок в тексте. Одному шаблону может соответствовать много разных строчек. Термин «Регулярные выражения» является переводом английского словосочетания «Regular expressions». Перевод не очень точно отражает смысл, правильнее было бы «шаблонные выражения». Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей. Например, \d задаёт любую цифру, а \d+ — задает любую последовательность из одной или более цифр. Работа с регулярками реализована во всех современных языках программирования. Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку. В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений

Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент. Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред. Во-первых, плохо написанные регулярные выражения работают медленно. Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад. В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения. Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят). А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы. Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать. )):
А вот здесь более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так!Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака. Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Документация и ссылки
Основы синтаксиса
Шаблоны, соответствующие одному символу
Квантификаторы (указание количества повторений)
Жадность в регулярках и границы найденного шаблона
В тех случаях, когда это важно, условие на границу шаблона нужно обязательно добавлять в регулярку. О том, как это можно делать, будет дальше.
Пересечение подстрок
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны. Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным. Например, если мы решим искать e-mail адреса при помощи неправильной регулярки \w+@\w+ (или даже лучше, [\w'._+-]+@[\w'._+-]+ ), то в неудачном случае найдём вот что:
Эксперименты в песочнице
Регулярки в питоне
Пример использования всех основных функций
Тонкости экранирования в питоне ( '\\\\\\\\foo' )
Использование дополнительных флагов в питоне
Написание и тестирование регулярных выражений
Для написания и тестирования регулярных выражений удобно использовать сервис https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор Sublime text 3.
Задачи — 1
В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв. Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона. У такси — две буквы, три цифры, затем две или три цифры с кодом региона. Есть также и другие виды, но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером указанных двух типов, и если является, то каким.
На вход даются строки, которые претендуют на то, чтобы быть номером. Определите тип номера. Буквы в номерах — заглавные русские. Маленькие и английские для простоты можно игнорировать.
Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part) и текста после собаки (Domain part). Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в википедии). Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1]
"()<>[]:,;@\\\"!#$%&'-/=?^_`<>|
.a"@(comment)exa-mple
Но большинство почтовых сервисов такой ад и вакханалию не допускают. И мы тоже не будем 🙂
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными 🙂
Скобочные группы (. ) и перечисления |
Перечисления (операция «ИЛИ»)
Скобочные группы (группировка плюс квантификаторы)
Скобки плюс перечисления
Ещё примеры
Задачи — 2
Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные ФГУП НИЦ ГИДГЕО, ФГОУ ЧШУ АПК и т.п. Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на http://sokr.ru/. Помогите ему.
Будем считать аббревиатурой слова только лишь из заглавных букв (как минимум из двух). Если несколько таких слов разделены пробелами, то они
считаются одной аббревиатурой.
Match-объекты
Группирующие скобки (. )
Тонкости со скобками и нумерацией групп.
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
Группы и re.findall
Группы и re.split
В некоторых ситуация эта возможность бывает чрезвычайно удобна! Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу станет очевидна!
Использование групп при заменах
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции re.sub вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
Ссылки на группы при поиске
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае 🙂 Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Задачи — 3
Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
Хайку — жанр традиционной японской лирической поэзии века, известный с XIV века.
Оригинальное японское хайку состоит из 17 слогов, составляющих один столбец иероглифов. Особыми разделительными словами — кирэдзи — текст хайку делится на части из 5, 7 и снова 5 слогов. При переводе хайку на западные языки традиционно вместо разделительного слова использую разрыв строки и, таким образом, хайку записываются как трёхстишия.
Для простоты будем считать, что слогов ровно столько же, сколько гласных, не задумываясь о тонкостях.
| Ввод | Вывод |
|---|---|
| Вечер за окном. / Еще один день прожит. / Жизнь скоротечна. | Хайку! |
| Просто текст | Не хайку. Должно быть 3 строки. |
| Как вишня расцвела! / Она с коня согнала / И князя-гордеца. | Не хайку. В 1 строке слогов не 5, а 6. |
| На голой ветке / Ворон сидит одиноко… / Осенний вечер! | Не хайку. В 2 строке слогов не 7, а 8. |
| Тихо, тихо ползи, / Улитка, по склону Фудзи, / Вверх, до самых высот! | Не хайку. В 1 строке слогов не 5, а 6. |
| Жизнь скоротечна… / Думает ли об этом / Маленький мальчик. | Хайку! |
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
lookaround на примере королей и императоров Франции
Людовик(?=VI) — Людовик, за которым идёт VI
Прочие фичи
Конечно, здесь описано не всё, что умеют регулярные выражения, и даже не всё, что умеют регулярные выражения в питоне. За дальнейшим можно обращаться к этому разделу. Из полезного за кадром осталась компиляция регулярок для ускорения многократного использования одного шаблона, использование именных групп и разные хитрые трюки.
А уж какие извращения можно делать с регулярными выражениями в языке Perl — поручик Ржевский просто отдыхает 🙂
Задачи — 4
Владимир написал свой открытый проект, именуя переменные в стиле «ВерблюжийРегистр».
И только после того, как написал о нём статью, он узнал, что в питоне для имён переменных принято использовать подчёркивания для разделения слов (under_score). Нужно срочно всё исправить, пока его не «закидали тапками».
Задача могла бы оказаться достаточно сложной, но, к счастью, Владимир совсем не использовал строковых констант и классов.
Поэтому любая последовательность букв и цифр, внутри которой есть заглавные, — это имя переменной, которое нужно поправить.
Довольно распространённая ошибка ошибка — это повтор слова.
Вот в предыдущем предложении такая допущена. Необходимо исправить каждый такой повтор (слово, один или несколько пробельных символов, и снова то же слово).
| Ввод | Вывод |
|---|---|
| Довольно распространённая ошибка ошибка — это лишний повтор повтор слова слова. Смешно, не не правда ли? Не нужно портить хор хоровод. | Довольно распространённая ошибка — это лишний повтор слова. Смешно, не правда ли? Не нужно портить хор хоровод. |
Для простоты будем считать словом любую последовательность букв, цифр и знаков _ (то есть символов \w ).
Дан текст. Необходимо найти в нём любой фрагмент, где сначала идёт слово «олень», затем не более 5 слов, и после этого идёт слово «заяц».
Большие целые числа удобно читать, когда цифры в них разделены на тройки запятыми.
Переформатируйте целые числа в тексте.
Для простоты будем считать, что:
Разделите текст на предложения так, чтобы каждое предложение занимало одну строку.
Пустых строк в выводе быть не должно. Любые наборы из полее одного пробельного символа замените на один пробел.
В предыдущей задаче мы немного схалтурили.
Однако к этому моменту задача должна стать посильной!



